
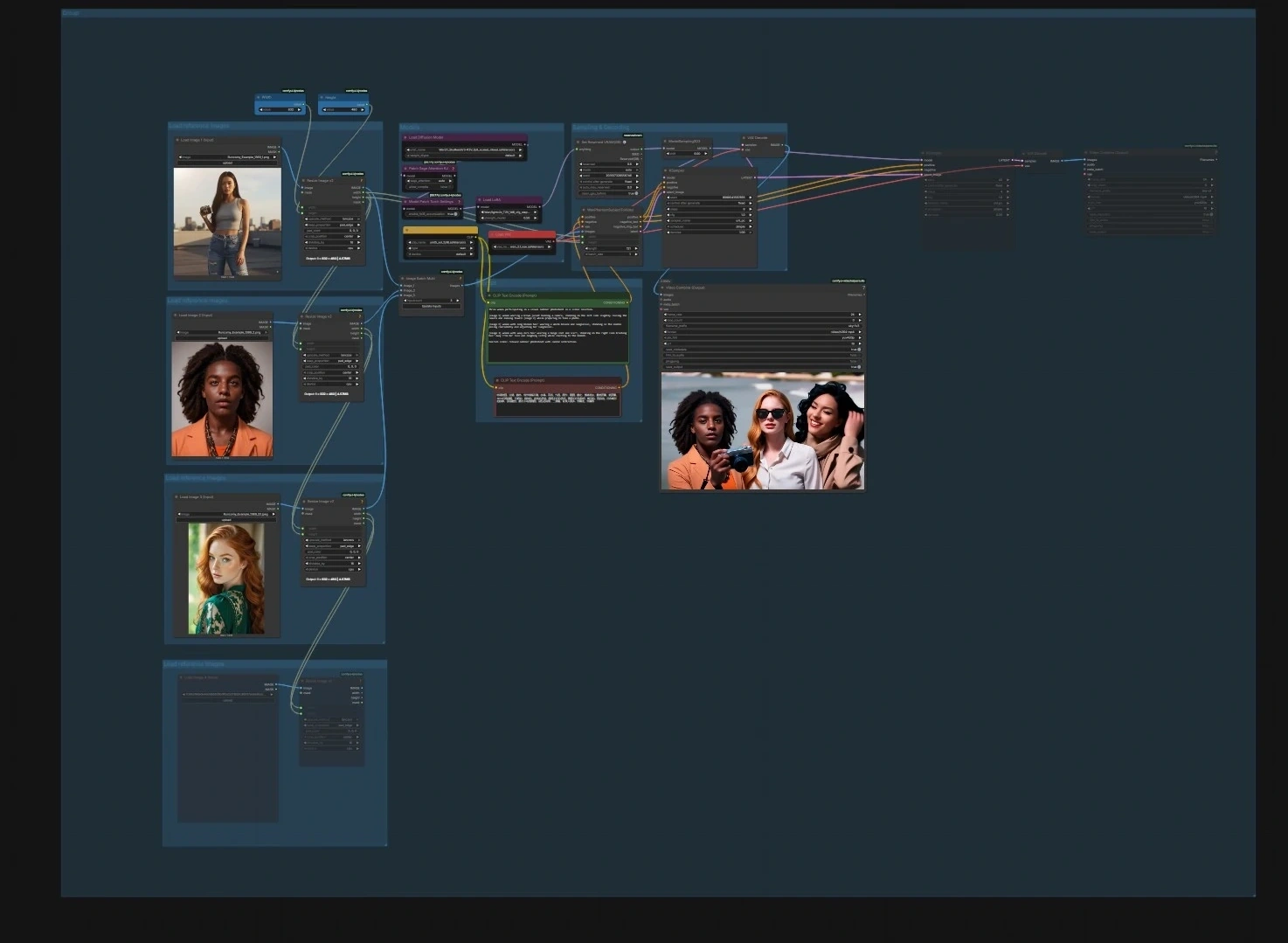
SkyReels V3 ComfyUI: identitätsgetreue Bild-, Video- und Audio-zu-Video-Erstellung#
SkyReels V3 ComfyUI ist ein produktionsbereiter Workflow, der das SkyReels V3 Multimodale Video-Modell in ComfyUI bringt, damit Sie Standbilder animieren, vorhandene Aufnahmen erweitern und audio-gesteuerte sprechende Avatare mit präzisem Lip-Sync erstellen können. Es ist für Kreative konzipiert, die filmische Bewegungen, eine starke Subjektidentität und zeitliche Kohärenz wünschen, während sie in einem flexiblen Knotengraphen bleiben.
Der Workflow wird mit vier fokussierten Pipelines geliefert, die unabhängig oder verkettet ausgeführt werden können: Bild-zu-Video-Charakteranimation, Video-zu-Video-Fortführung, Audio-zu-Video-sprechende Avatare und Next-Shot-Generierung für den Story-Flow. Jeder Pfad enthält klare Eingabepunkte und sinnvolle Vorgaben, sodass Sie Ihre Assets einfügen und schnell hochwertige SkyReels V3-Ausgaben rendern können.
Hinweis für 2X Large und größere Maschinen (R2V-Workflow): Setzen Sie
Patch Sage Attention KJ(#240)sage_attentionaufdeaktiviert, bevor Sie starten. Wenn es aktiviert bleibt, könnenSM90 kernel is not available-Fehler auftreten.
Schlüsselmodelle im Comfyui SkyReels V3 ComfyUI Workflow#
- SkyReels V3 Videobackbones (R2V, V2V Shot, A2V) aus dem WanVideo FP8 Pack. Dies sind die Kern-Generatoren, die identitätsbewusste Bewegungen, Videofortführung und audio-konditionierten Lip-Sync handhaben. Siehe die SkyReels V3 Gewichte im WanVideo Pack auf Hugging Face hier.
- OpenCLIP Vision ViT Modelle für Bildführung und Referenzembedding. Sie bieten robuste visuelle Merkmale, die helfen, Aussehen und Stil über die Frames hinweg zu bewahren. Projektseite: open_clip.
- UMT5 Text-Encoder für Prompt-Verständnis. Er liefert reichhaltige Sprachkonditionierung, um Stil, Szene und Aktionen zu steuern. Repo: umt5.
- Wav2Vec2 Sprachmerkmale für Lip-Sync und Audioanalyse. Die chinesische Basisvariante wird von Haus aus unterstützt und ähnliche englische Varianten funktionieren ebenfalls. Modellkarte: TencentGameMate/chinese-wav2vec2-base.
- Qwen3-ASR-1.7B für Sprach-zu-Text. Wird verwendet, um Referenz-Audio zu transkribieren und Voice-Cloned TTS-Prompts zu bootstrappen. Modellkarte: Qwen/Qwen3-ASR-1.7B.
- MelBandRoFormer für Stimmentrennung. Hilfreich, wenn Sie saubere Sprachspuren benötigen, bevor Sie Lip-Sync-Embedding erstellen. Modellkarte: Kijai/MelBandRoFormer_comfy.
- MiniCPM-V für aufnahmebewusste Prompt-Generierung. Es analysiert vorheriges Filmmaterial und schlägt den nächsten Shot für Story-Kontinuität vor. Modell-Hub: OpenBMB/MiniCPM-V.
Verwendung des Comfyui SkyReels V3 ComfyUI Workflows#
Der Graph ist in vier Pipelines organisiert. Sie können jede einzeln oder in der Reihenfolge ausführen, um längere Bearbeitungen zu erstellen.
Bild-zu-Video-Charakteranimation#
- Modelle. Laden Sie die UNet, CLIP und VAE in der Modellgruppe mit
UNETLoader(#241),CLIPLoader(#242) undVAELoader(#194). Die Modell-Patch-KnotenPathchSageAttentionKJ(#240) undModelPatchTorchSettings(#239) optimieren Aufmerksamkeit und mathematische Einstellungen, währendLoraLoaderModelOnly(#250) es Ihnen ermöglicht, optional einen Stil oder eine Bewegungs-LoRA in das SkyReels-Modell zu mischen. - Referenzbilder laden. Verwenden Sie die drei „Referenzbilder laden“-Gruppen, um 1–3 Porträts oder Posen zu importieren. Die Größenanpassungshelfer
ImageResizeKJv2(#291, #298, #299, #304) richten das Seitenverhältnis aus und stapeln sie; sauberere Identitätsfotos liefern stabilere Ergebnisse. - Prompt. Geben Sie Szenen- und Aktionstext in der Prompt-Gruppe mit
CLIPTextEncode(#6) und einem optionalen negativen Text-EncoderCLIPTextEncode(#7) ein, um unerwünschte Merkmale abzuschwächen. Halten Sie die Sprache prägnant und spezifisch für Bewegung und Bildgestaltung. - Sampling und Decodierung.
WanPhantomSubjectToVideo(#249) fusioniert Ihre Referenzen und Prompts in ein identitätsbewusstes Latent, dasKSampler(#149) überModelSamplingSD3(#48) speist. Die decodierten Frames vonVAEDecode(#264) werden mitVHS_VideoCombine(#280) zu einem Film verpackt; legen Sie dort Ihre Zielbildrate und das Dateiformat fest.
Video-zu-Video-Erweiterungsschleife#
- Eingabevideo und Einstellungen. Bringen Sie Ihren Quellclip mit
VHS_LoadVideo(#329) ein. Legen Sie fest, wie viele zusätzliche Segmente generiert werden sollen und wie viel Überlappung zwischen den Segmenten mit den Ganzzahlhelfern „Number of Extend“ (#342) und „Overlapping Frames“ (#341).ImageResizeKJv2(#327) standardisiert die Auflösung für den Sampler. - Schleifen-Sampling-Erweiterungsvideo. Das Schleifenpaar
easy forLoopStart(#331) undeasy forLoopEnd(#332) durchläuft den Clip in Fenstern, um Übergänge zu stabilisieren. Jedes Fenster wird mitWanVideoEncode(#326) codiert, erhält neutrale oder Steuerungsembeds überWanVideoEmptyEmbeds(#328) und wird vonWanVideoSampler(#320) ausWanVideoModelLoader(#319) entrauscht. Frames werden mitWanVideoDecode(#321) decodiert und mitVHS_VideoCombine(#322, #335) vorgeführt oder gespeichert. - Leistungshilfen.
WanVideoTorchCompileSettings(#323) undWanVideoBlockSwap(#325) ermöglichen Kompilierungs- und Speichertipps für längere oder hochauflösende Läufe.
Audio-zu-Video-sprechender Avatar#
- 1 – Audio erstellen. Sie können eine sprachgeklonte Sprachspur mit
FB_Qwen3TTSVoiceClonePrompt(#416) undFB_Qwen3TTSVoiceClone(#412) generieren oder jede voraufgezeichnete Stimme mitLoadAudio(#417) laden.Qwen3ASRLoader(#414) plusQwen3ASRTranscribe(#413) helfen Ihnen dabei, Text aus einem Referenzclip zu extrahieren, um das TTS-Prompt bei Bedarf zu starten. - 2 – Audiofunktionen.
DownloadAndLoadWav2VecModel(#348) speistMultiTalkWav2VecEmbeds(#350), um Lippenbewegungs-Embeddings aus Ihrer Sprache zu erstellen; die Länge wird an das Audio angepasst und ist mitPreviewAudio(#422) vorschaubar. Verwenden SieAny Switch (rgthree)(#435), um TTS-Ausgabe oder Ihre importierte Datei als Steuerungsspur auszuwählen. - 3 – Eingabebild. Laden Sie das sprechende Gesicht in der Gruppe „3 - Eingabebild“ und passen Sie es mit
ImageResizeKJv2(#370) an. Saubere, frontale Porträts mit gleichmäßiger Beleuchtung funktionieren am besten. - Referenzvideoerzeugung. Erstellen Sie zunächst einen kurzen visuellen Anker aus dem Standbild mit
WanVideoImageToVideoEncode(#392). CLIP-Vision-Funktionen vonCLIPVisionLoader(#352) undWanVideoClipVisionEncode(#351) stabilisieren die Identität über die nächste Stufe hinweg; ein SchedulerWanVideoSchedulerv2(#385) wird in der Sampling-Einstellung-Gruppe vorbereitet. - Audio-Lip-Sync erzeugen.
WanVideoImageToVideoSkyreelsv3_audio(#383) kombiniert das Startbild, optionale Referenzframes und CLIP-Vision-Embeds in der Bildkonditionierung.WanVideoSamplerv2(#384) entrauscht dann mit dem SkyReels A2V-Modell, währendWanVideoSamplerExtraArgs(#386) dieMultiTalk-Lip-Sync-Embeddings für präzise Mundformen injiziert.WanVideoPassImagesFromSamples(#381) streamt decodierte Frames zuVHS_VideoCombine(#346), wo das endgültige Video mit Ihrem Audio gemischt wird.
Video-zu-Video-Next-Shot-Generierung#
- Videoframes vorverarbeiten. Importieren Sie den vorherigen Shot mit
VHS_LoadVideo(#443) und passen Sie ihn überImageResizeKJv2(#441) an.GetImageRangeFromBatch(#445) wählt einen Kontextausschnitt aus, denWanVideoEncode(#440) in Latents umwandelt;WanVideoEmptyEmbeds(#442) bereitet das Konditionierungsfenster vor. - Auto-Videoprompt.
CreateVideo(#450) assembliert einen kompakten Proxyclip aus den Kontextframes, denAILab_MiniCPM_V_Advanced(#449) analysiert, um einen Next-Shot-Prompt zu entwerfen. Inspizieren oder verfeinern Sie den Entwurf inShowText|pysssss(#447) und betten Sie ihn mitWanVideoTextEncodeCached(#444) ein, bevor Sie sampeln. - Modelle und Sampling. Laden Sie das V2V Shot-Modell mit
WanVideoModelLoader(#436) undWanVideoVAELoader(#438); optionalesWanVideoBlockSwap(#439) handhabt VRAM. DerWanVideoSampler(#451) generiert die Fortführung,WanVideoDecode(#437) rendert Frames undVHS_VideoCombine(#446) gibt den finalen Shot aus. Dieser SkyReels V3 ComfyUI-Pfad ist ideal für Storyboards und Previz, bei denen jeder neue Schnitt den letzten respektieren sollte.
Wichtige Knoten im Comfyui SkyReels V3 ComfyUI Workflow#
WanPhantomSubjectToVideo(#249). Baut ein identitätsbewusstes Latent aus Ihren gebündelten Referenzbildern plus Text-Cues, die dann den Sampler antreiben. Passen Sie die Anzahl und Vielfalt der Referenzen an, um das Gleichgewicht zwischen Ähnlichkeitsfixierung und kreativer Bewegung zu finden; halten Sie die Resizenodes, die es speisen, konsistent, um Drift zu vermeiden. Referenz: WanVideo Wrapper auf GitHub enthält Implementierungsnotizen und erwartete Eingaben ComfyUI-WanVideoWrapper.WanVideoImageToVideoEncode(#392). Codiert ein Standbild in einen stabilen Shot-Samen und mischt optional CLIP-Vision-Leitlinien für Pose und Bildgestaltung. Verwenden Sie es, um Ankerframes vor der audio-gesteuerten Phase zu erstellen, damit Identität und Kameraeinstellungen über die Pipelines hinweg konsistent bleiben. Wrapper-Dokumentation: ComfyUI-WanVideoWrapper.WanVideoImageToVideoSkyreelsv3_audio(#383). Bereitet Bild-Embeds vor, die für den A2V-Sampler maßgeschneidert sind, und fügt optionale Referenzvideoframes zusammen. Stellen Sie sicher, dass seine Breite und Höhe zum Samplerpfad passen; paaren Sie es mitWanVideoSamplerv2undMultiTalkWav2VecEmbedsfür präzisen Lip-Sync.WanVideoSamplerv2(#384, #387). Der Hauptentrauscher für SkyReels V3, der Bild- und Textembeds sowie Scheduler-Einstellungen akzeptiert. DieWanVideoSamplerExtraArgs-Knoten (#386, #409) sind, wo Lip-Sync-, Loop- oder Kontextmerkmale injiziert werden; halten Sie diese verbunden, wenn Sie zwischen A2V- und I2V-Modellen wechseln. Implementierungsdetails: ComfyUI-WanVideoWrapper.MultiTalkWav2VecEmbeds(#350). Wandelt Sprache in zeitlich ausgerichtete Embeddings um, die die Mundbewegung steuern. Das Anpassen des vorgesehenen Frame-Budgets und das Sicherstellen sauberer Vokale verbessert die Phonemgenauigkeit erheblich. Wav2Vec-Referenzmodell: TencentGameMate/chinese-wav2vec2-base.AILab_MiniCPM_V_Advanced(#449). Analysiert den vorherigen Shot und entwirft ein strukturiertes Prompt für Charakter, Hintergrund, Aktion, Stimmung und Beleuchtung. Verwenden Sie dies, um narrative Kontinuität zu bewahren, wenn Sie den V2V Next-Shot-Pfad verwenden; der resultierende Text fließt inWanVideoTextEncodeCached. Modellfamilie: OpenBMB/MiniCPM-V.
Optionale Extras#
- Halten Sie Bild-, Video- und Samplerauflösungen über verbundene Knoten hinweg konsistent, um Aspektverzerrungen und Identitätsflimmern zu vermeiden.
- Für längere Erweiterungen erhöhen Sie die Fensterüberlappung in der V2V-Erweiterungsschleife, um Übergänge zwischen Segmenten zu glätten.
- Wenn der GPU-Speicher knapp ist, lassen Sie die Reserved VRAM-Knoten (
ReservedVRAMSetter(#312, #448)) aktiviert und verwenden Sie die Kompilierungseinstellungsblöcke vor dem Sampling. - Wenn sprechende Avatare aus dem Takt geraten, priorisieren Sie saubere Sprache oder trennen Sie Vokale mit MelBandRoFormer, bevor Sie
MultiTalk-Embeddings erstellen. - Die endgültigen Lieferungseinstellungen wie Bildrate, Pix-Format und CRF werden in den
VHS_VideoCombine-Ausgabeknoten gesteuert; passen Sie die Bildrate an Ihre Quelle an, um nahtlose Bearbeitungen zu erzielen.
Dieses README deckt das vollständige SkyReels V3 ComfyUI-Graph ab, sodass Sie den Pfad wählen können, der zu Ihrem Projekt passt, sie bei Bedarf kombinieren und konsistente, storybereite Videos mit minimalem Aufwand rendern können.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken @Benji's AI Playground und SkyReels für den SkyReels V3 ComfyUI-Workflow für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die unten verlinkte Originaldokumentation und -repositories.
Ressourcen#
- SkyReels/V3 ComfyUI Quelle
- Docs / Release Notes: SkyReels V3 ComfyUI Source from @Benji’s AI Playground
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreuern bereitgestellt werden.