
Pose Control LipSync mit Wan2.2 S2V: audiogesteuert, posengesteuertes Bild-zu-Video für ausdrucksstarke Avatare#
Pose Control LipSync mit Wan2.2 S2V verwandelt ein einzelnes Bild, einen Audioclip und ein Posenreferenzvideo in eine synchronisierte Sprechaufführung. Der Charakter in Ihrem Referenzbild folgt der Körperbewegung des Referenzvideos, während die Lippenbewegungen dem Audio entsprechen. Dieser ComfyUI-Workflow ist ideal für Avatare, Story-Szenen, Trailer, Erklärvideos und Musikvideos, bei denen Sie die Posen, Ausdrücke und die Sprechzeit genau kontrollieren möchten.
Basierend auf der Wan 2.2 S2V 14B Modellfamilie kombiniert der Workflow Text-Prompts, klare Vokaleigenschaften und Posenkarten, um filmische Bewegungen mit stabiler Identität zu erzeugen. Er ist einfach zu bedienen und bietet Kreativen gleichzeitig feine Kontrolle über Aussehen, Tempo und Bildgestaltung.
Wichtige Modelle im Comfyui Pose Control LipSync mit Wan2.2 S2V Workflow#
- Wan2.2‑S2V‑14B. Der Kern der Sprach-zu-Video-Generator, der ein Standbild plus Audio in Video umwandelt, mit optionaler Posenkonditionierung zur Bewegungsführung. Siehe das offizielle Repository und das Modellblatt für Fähigkeiten und Nutzungshinweise: Wan‑Video/Wan2.2 und Wan‑AI/Wan2.2‑S2V‑14B.
- Wan VAE. Der Wan-Encoder kodiert und dekodiert Videolatente mit hoher Treue und wird in den Wan 2.x-Pipelines verwendet. Referenzimplementierung: Wan-Pipelines in Diffusers Dokumentation.
- Google UMT5‑XXL Text-Encoder. Bietet starke mehrsprachige Textkonditionierung für hochrangige Szenenintention und Stilkontrolle innerhalb der Wan-Pipelines. Modellkarte: google/umt5‑xxl.
- Facebook Wav2Vec2‑Large. Extrahiert robuste Spracheigenschaften, die Lippensynchronisation und Mikroexpressionen antreiben. Modellkarte: facebook/wav2vec2‑large‑960h.
- DWPose mit YOLOX-Detektor. Generiert menschliche Posen-Schlüsselpunkte und Posenkarten aus dem Referenzvideo zur Steuerung der Ganzkörperbewegung. Repos: IDEA‑Research/DWPose und Megvii‑BaseDetection/YOLOX.
- LightX2V LoRA für Wan. Ein leichtes LoRA, das zur Beschleunigung der Low-Step-Bild-zu-Video-Stil-Entstörung verwendet wird, während die Bewegungsqualität erhalten bleibt; Wan 2.2 unterstützt LoRAs in seinen Entstörern. Siehe die Wan Diffusers Anleitung zur LoRA-Nutzung in Wan-Pipelines.
Verwendung des Comfyui Pose Control LipSync mit Wan2.2 S2V Workflows#
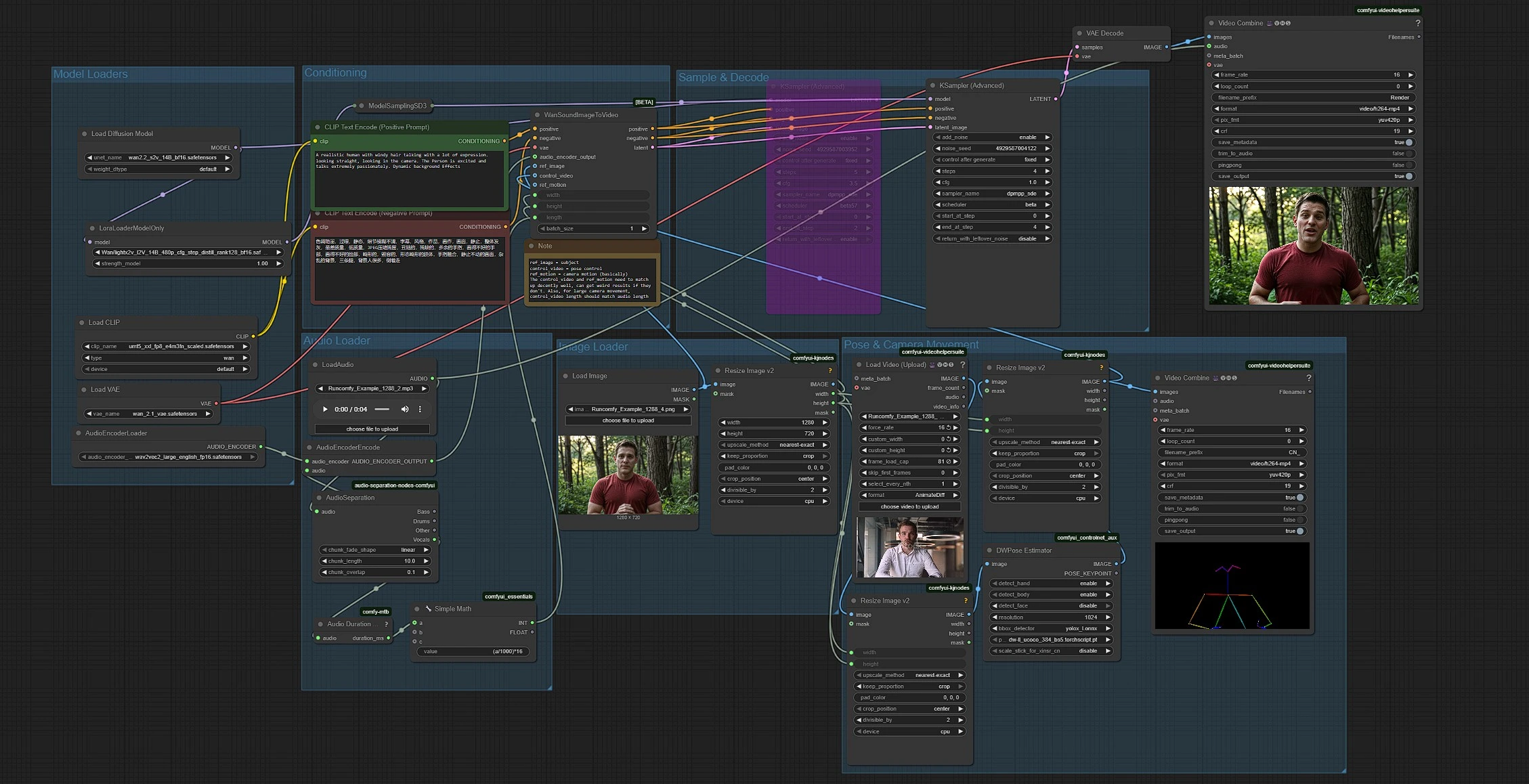
Der Workflow kombiniert fünf Teile: Modellladung, Audiovorbereitung, Bild- und Posen-Eingaben, Konditionierung und Generierung. Gruppen laufen in einem Links-nach-Rechts-Fluss, wobei die Audiolänge automatisch die Clip-Dauer bei 16 fps festlegt.
Modell-Loader#
Diese Gruppe lädt das Wan 2.2 S2V Modell, sein VAE, den UMT5‑XXL Text-Encoder und ein LightX2V LoRA. Der Basistransformer wird in UNETLoader (#37) initialisiert und mit LoraLoaderModelOnly (#61) für schnelleres Low-Step-Sampling angepasst. Das Wan VAE wird von VAELoader (#39) bereitgestellt. Text-Encoder werden von CLIPLoader (#38) bereitgestellt, der die UMT5‑XXL Gewichte lädt, auf die sich Wan bezieht. Sie müssen diese Gruppe selten berühren, es sei denn, Sie tauschen Mod-Dateien aus.
Audio-Loader#
Legen Sie eine Audiodatei mit LoadAudio (#58) ab. AudioSeparation (#85) isoliert den Vokalstamm, sodass die Lippen klarer Sprache oder Gesang folgen, anstatt Hintergrundinstrumenten. Audio Duration (mtb) (#70) misst den Clip und SimpleMath+ (#71) konvertiert die Dauer in eine Bildanzahl bei 16 fps, sodass die Videolänge Ihrem Audio entspricht. AudioEncoderEncode (#56) füttert einen Wav2Vec2‑Large Encoder, sodass Wan Phoneme auf Mundformen für präzise Lippensynchronisation abbilden kann.
Bild-Loader#
LoadImage (#52) liefert das Standbild des Subjekts, das Identität, Kleidung und Kameraeinstellung trägt. ImageResizeKJv2 (#69) liest die Abmessungen aus dem Bild, sodass die Pipeline konsistent die Zielbreite und -höhe für alle späteren Stufen ableitet. Verwenden Sie ein scharfes, frontales Bild mit einem ungehinderten Mund für die getreuesten Lippenbewegungen.
Posen- & Kamerabewegung#
VHS_LoadVideo (#80) importiert Ihr Posenreferenzvideo. ImageResizeKJv2 (#83) passt die Rahmen an die Zielgröße an, und DWPreprocessor (#78) verwandelt sie in Posenkarten mit YOLOX-Erkennung plus DWPose-Schlüsselpunkten. Ein endgültiges ImageResizeKJv2 (#81) passt die Posenrahmen an die Generierungsauflösung an, bevor sie als Kontrollvideo weitergeleitet werden. Sie können Posen-Ausgaben in der Vorschau anzeigen, indem Sie an VHS_VideoCombine (#95) weiterleiten, was hilft, zu bestätigen, dass die Referenzrahmung und -zeitung zu Ihrem Subjekt passen.
Konditionierung#
Schreiben Sie den Stil und die Szenenintention in CLIP Text Encode (Positive Prompt) (#6) und verwenden Sie CLIP Text Encode (Negative Prompt) (#7), um unerwünschte Artefakte zu vermeiden. Prompts steuern hochrangige Ästhetik und Hintergrundbewegung, während das Audio Lippenbewegungen antreibt und die Posenreferenz die Körperdynamik bestimmt. Halten Sie Prompts prägnant und im Einklang mit Ihrem Zielkamera-Winkel und Ihrer Stimmung.
Beispiel & Dekodierung#
WanSoundImageToVideo (#55) kombiniert Text, Audioeigenschaften, das Referenzbild und das Posenkontrollvideo und bereitet eine latente Sequenz vor. KSamplerAdvanced (#64) führt eine Low-Step-Entstörung durch, die für LightX2V-Stil-Beschleunigung geeignet ist, und VAEDecode (#8) rekonstruiert Rahmen. VHS_VideoCombine (#62) kombiniert Rahmen zu einem MP4 und fügt Ihr ursprüngliches Audio hinzu, sodass das Ergebnis bereit für die Überprüfung oder Bearbeitung ist.
Wichtige Knoten im Comfyui Pose Control LipSync mit Wan2.2 S2V Workflow#
WanSoundImageToVideo (#55)#
Das Herzstück des Workflows, das Wan2.2‑S2V mit Ihrem Prompt, Vocals, Subjektbild und Posenkontrollvideo konditioniert. Passen Sie nur das an, was wichtig ist: Setzen Sie width, height und length, um Ihr Subjektbild und die Audiolänge anzupassen, und schließen Sie ein vorverarbeitetes Posenvideo zur Bewegungssteuerung an. Lassen Sie ref_motion leer, es sei denn, Sie planen, eine separate Kameraspur einzufügen. Das Sprach-zu-Video-Verhalten des Modells wird in Wan‑AI/Wan2.2‑S2V‑14B und Wan‑Video/Wan2.2 beschrieben.
DWPreprocessor (#78)#
Generiert Posenkarten mit YOLOX zur Erkennung und DWPose für Ganzkörper-Schlüsselpunkte. Starke Posenhinweise helfen Wan, Gliedmaßen und Torso zu folgen, während das Audio Lippen und Ausdrücke steuert. Wenn Ihre Referenz starke Kamerabewegungen aufweist, verwenden Sie ein Posenvideo, das den Blickwinkel und die Zeit mit der beabsichtigten Aufführung abstimmt. DWPose und seine Varianten sind dokumentiert in IDEA‑Research/DWPose.
KSamplerAdvanced (#64)#
Führt die Entstörung für die latente Sequenz aus. Mit einem geladenen LightX2V LoRA können Sie Schritte niedrig halten für schnelle Vorschauen, während die Bewegungskohärenz erhalten bleibt; erhöhen Sie die Schritte, wenn Sie maximalen Detailreichtum anstreben. Scheduler-Wahlen beeinflussen die Bewegungsglätte versus Schärfe und sollten zusammen mit der LoRA-Nutzung abgestimmt werden, wie in den Wan Diffusers Dokumentation beschrieben.
VHS_LoadVideo (#80)#
Importiert und durchsucht Ihre Posenreferenz. Verwenden Sie die In-Node-Auswahlwerkzeuge, um das exakte Segment auszuwählen, das Ihrem Audioteil entspricht. Das Halten der Rahmung und der Subjektgröße konsistent mit dem Referenzbild stabilisiert die Bewegungsübertragung. Der Knoten ist Teil der VideoHelperSuite: ComfyUI‑VideoHelperSuite.
VHS_VideoCombine (#62)#
Kombiniert generierte Rahmen und Ihr Audio zu einem MP4 und speichert Workflow-Metadaten. Setzen Sie die Ausgabebildrate auf 16 fps, um die Bildanzahl zu erreichen, die aus der Audio-Dauer in diesem Workflow berechnet wurde. Deaktivieren oder aktivieren Sie das Speichern von Metadaten, je nach Ihren Anforderungen an das Asset-Management. Siehe VideoHelperSuite-Dokumentation bei ComfyUI‑VideoHelperSuite.
AudioSeparation (#85)#
Isoliert Vokale, sodass Wav2Vec2-Funktionen Mundformen ohne Störung durch Instrumente oder Effekte antreiben. Wenn Ihr Eingang bereits klare Sprache ist, können Sie die Trennung umgehen. Für beste Ergebnisse halten Sie die Audiopegel konsistent und minimieren Sie den Nachhall.
Optionale Extras#
- Für beste Lippensynchronisation bevorzugen Sie klare Sprache oder A-cappella-Gesang. Wav2Vec2 arbeitet bei 16 kHz; die meisten Pipelines resampeln automatisch, aber das Bereitstellen von 16 kHz-Dateien hilft.
- Verwenden Sie ein gut beleuchtetes, frontales Subjektbild mit sichtbaren Zähnen und Lippen. Verdeckungen verringern die Genauigkeit.
- Passen Sie die Rahmung und Bewegung der Posenreferenz an Ihr Subjekt an. Große Kamerabewegungen funktionieren am besten, wenn die Länge des Posenvideos mit dem Audio-Segment übereinstimmt.
- Beginnen Sie mit 480p für schnelle Iterationen; wechseln Sie zu 720p für die endgültige Qualität. Wan 2.2 unterstützt beide Auflösungen in S2V.
- Halten Sie Prompts kurz und konsistent mit der Kameraeinstellung in Ihrem Bild und der Posenreferenz, um Konflikte zu vermeiden.
- Wenn Sie mit LoRAs experimentieren, stellen Sie sicher, dass sie mit Wan 2.2-Entstörern kompatibel sind. Siehe LoRA-Hinweise in den Wan Diffusers Dokumentation.
Dieser Pose Control LipSync mit Wan2.2 S2V Workflow bietet Ihnen einen schnellen Weg von Audio und einem Standbild zu einer kontrollierbaren, rhythmischen Aufführung, die kohärent aussieht und ausdrucksstark wirkt.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken @ArtOfficialLabs von Pose Control LipSync mit Wan2.2 S2VDemo für ihre Beiträge und Wartung. Für autoritative Details beachten Sie bitte die ursprüngliche Dokumentation und die unten verlinkten Repositories.
Ressourcen#
- YouTube/Pose Control LipSync mit Wan2.2 S2VDemo
- Docs / Release Notes von @ArtOfficialLabs: Pose Control LipSync mit Wan2.2 S2VDemo
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und des Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Wartungspersonen bereitgestellt werden.
