
⚠️ Wichtiger Hinweis: Diese ComfyUI MultiTalk-Implementierung unterstützt derzeit nur die EINZELPERSON-Generierung. Multi-Personen-Konversationsfunktionen werden in Kürze verfügbar sein.
1. Was ist MultiTalk?#
MultiTalk ist ein revolutionäres Framework für die audiogesteuerte Multi-Personen-Konversations-Videogenerierung, entwickelt von MeiGen-AI. Im Gegensatz zu traditionellen Talking-Head-Generierungsmethoden, die nur Gesichtsbewegungen animieren, kann die MultiTalk-Technologie realistische Videos von sprechenden, singenden und interagierenden Personen generieren und dabei eine perfekte Lippensynchronisation mit der Audioeingabe beibehalten. MultiTalk verwandelt statische Fotos in dynamische sprechende Videos, in denen die Person genau das sagt oder singt, was Sie möchten.
2. Wie MultiTalk funktioniert#
MultiTalk nutzt fortschrittliche KI-Technologie, um sowohl Audiosignale als auch visuelle Informationen zu verstehen. Die ComfyUI MultiTalk-Implementierung kombiniert MultiTalk + Wan2.1 + Uni3C für optimale Ergebnisse:
Audioanalyse: MultiTalk verwendet einen leistungsstarken Audio-Encoder (Wav2Vec), um die Nuancen der Sprache zu verstehen, einschließlich Rhythmus, Tonfall und Aussprachemuster.
Visuelles Verständnis: Aufgebaut auf dem robusten Wan2.1 Video-Diffusionsmodell versteht MultiTalk die menschliche Anatomie, Gesichtsausdrücke und Körperbewegungen (besuchen Sie unseren Wan2.1 Workflow für t2v/i2v-Generierung).
Kamerasteuerung: MultiTalk mit Uni3C Controlnet ermöglicht subtile Kamerabewegungen und Szenensteuerung, wodurch das Video dynamischer und professioneller wirkt. Schauen Sie sich unseren Uni3C Workflow für schöne Kamerabewegungsübertragung an.
Perfekte Synchronisation: Durch ausgefeilte Attention-Mechanismen lernt MultiTalk, Lippenbewegungen perfekt mit dem Audio abzugleichen und dabei natürliche Gesichtsausdrücke und Körpersprache beizubehalten.
Anweisungsbefolgung: Im Gegensatz zu einfacheren Methoden kann MultiTalk Textprompts folgen, um Szene, Pose und Gesamtverhalten zu steuern, während die Audiosynchronisation beibehalten wird.
3. Vorteile von ComfyUI MultiTalk#
- Hochwertige Lippensynchronisation: MultiTalk erreicht millisekundengenaue Lippensynchronisation, besonders beeindruckend bei Gesangsszenarien
- Vielseitige Inhaltserstellung: MultiTalk unterstützt sowohl Sprach- als auch Gesangsgenerierung mit verschiedenen Charaktertypen einschließlich Cartoon-Charakteren
- Flexible Auflösung: MultiTalk generiert Videos in 480P oder 720P mit beliebigen Seitenverhältnissen
- Lange Video-Unterstützung: MultiTalk erstellt Videos mit einer Länge von bis zu 15 Sekunden
- Anweisungsbefolgung: MultiTalk steuert Charakteraktionen und Szeneneinstellungen über Textprompts
4. Verwendung des ComfyUI MultiTalk Workflows#
Schritt-für-Schritt MultiTalk Anleitung#
Schritt 1: MultiTalk-Eingaben vorbereiten
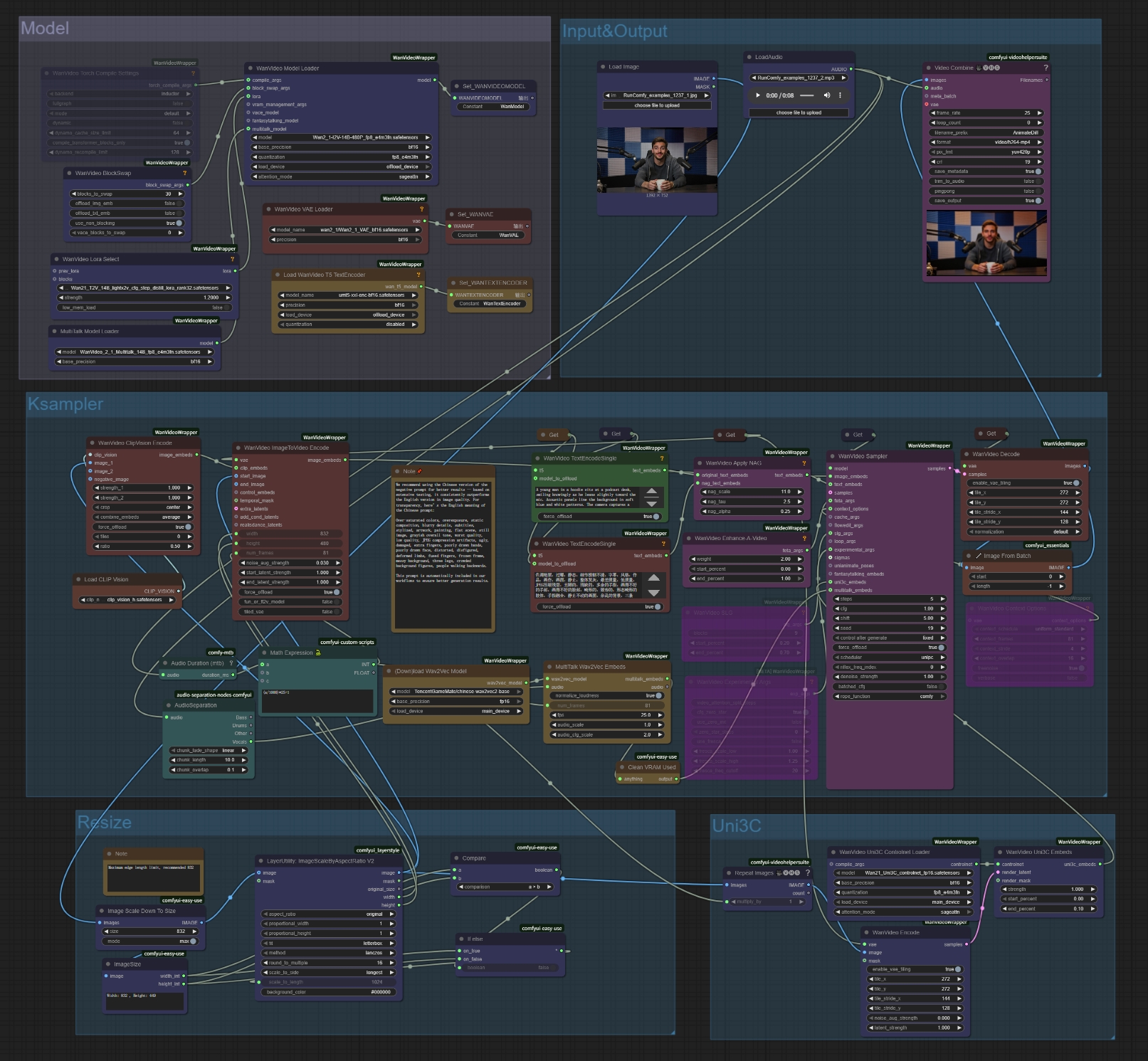
- Referenzbild hochladen: Klicken Sie auf "choose file to upload" im Load Image-Knoten
- Verwenden Sie klare, frontal aufgenommene Fotos für beste MultiTalk-Ergebnisse
- Das Bild wird automatisch auf optimale Dimensionen angepasst (832px empfohlen)
- Audiodatei hochladen: Klicken Sie auf "choose file to upload" im LoadAudio-Knoten
- MultiTalk unterstützt verschiedene Audioformate (WAV, MP3 usw.)
- Klare Sprache/Gesang funktioniert am besten mit MultiTalk
- Für die Erstellung benutzerdefinierter Songs nutzen Sie unseren Ace-Step Musikgenerierungs-Workflow, der hochwertige Musik mit synchronisierten Texten produziert.
- Textprompt schreiben: Beschreiben Sie Ihre gewünschte Szene in den Text-Encode-Knoten für die MultiTalk-Generierung
Schritt 2: MultiTalk-Generierungseinstellungen konfigurieren
- Sampling-Schritte: 20-40 Schritte (höher = bessere MultiTalk-Qualität, langsamere Generierung)
- Audio Scale: Bei 1.0 belassen für optimale MultiTalk-Lippensynchronisation
- Embed Cond Scale: 2.0 für ausgewogene MultiTalk-Audio-Konditionierung
- Kamerasteuerung: Uni3C für subtile Bewegungen aktivieren oder für statische MultiTalk-Aufnahmen deaktivieren
Schritt 3: Optionale MultiTalk-Verbesserungen
- LoRA-Beschleunigung: Aktivieren für schnellere MultiTalk-Generierung mit minimalem Qualitätsverlust
- Video-Verbesserung: Verbesserungsknoten für MultiTalk-Nachbearbeitung verwenden
- Negative Prompts: Unerwünschte Elemente zur Vermeidung in der MultiTalk-Ausgabe hinzufügen (unscharf, verzerrt usw.)
Schritt 4: Mit MultiTalk generieren
- Den Prompt in die Warteschlange stellen und auf die MultiTalk-Generierung warten
- VRAM-Nutzung überwachen (48GB für MultiTalk empfohlen)
- MultiTalk-Generierungszeit: 7-15 Minuten je nach Einstellungen und Hardware
5. Danksagungen#
Originalforschung: MultiTalk wurde von MeiGen-AI in Zusammenarbeit mit führenden Forschern auf diesem Gebiet entwickelt. Das Originalpaper "Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation" präsentiert die bahnbrechende Forschung hinter dieser Technologie.
ComfyUI-Integration: Die ComfyUI-Implementierung wird von Kijai über das ComfyUI-WanVideoWrapper-Repository bereitgestellt und macht diese fortschrittliche Technologie der breiteren kreativen Gemeinschaft zugänglich.
Basistechnologie: Aufgebaut auf dem Wan2.1 Video-Diffusionsmodell und integriert Audioverarbeitungstechniken von Wav2Vec, was eine Synthese modernster KI-Forschung darstellt.
6. Links und Ressourcen#
- Originalforschung: MeiGen-AI MultiTalk Repository
- Projektseite: https://meigen-ai.github.io/multi-talk/
- ComfyUI-Integration: ComfyUI-WanVideoWrapper
