
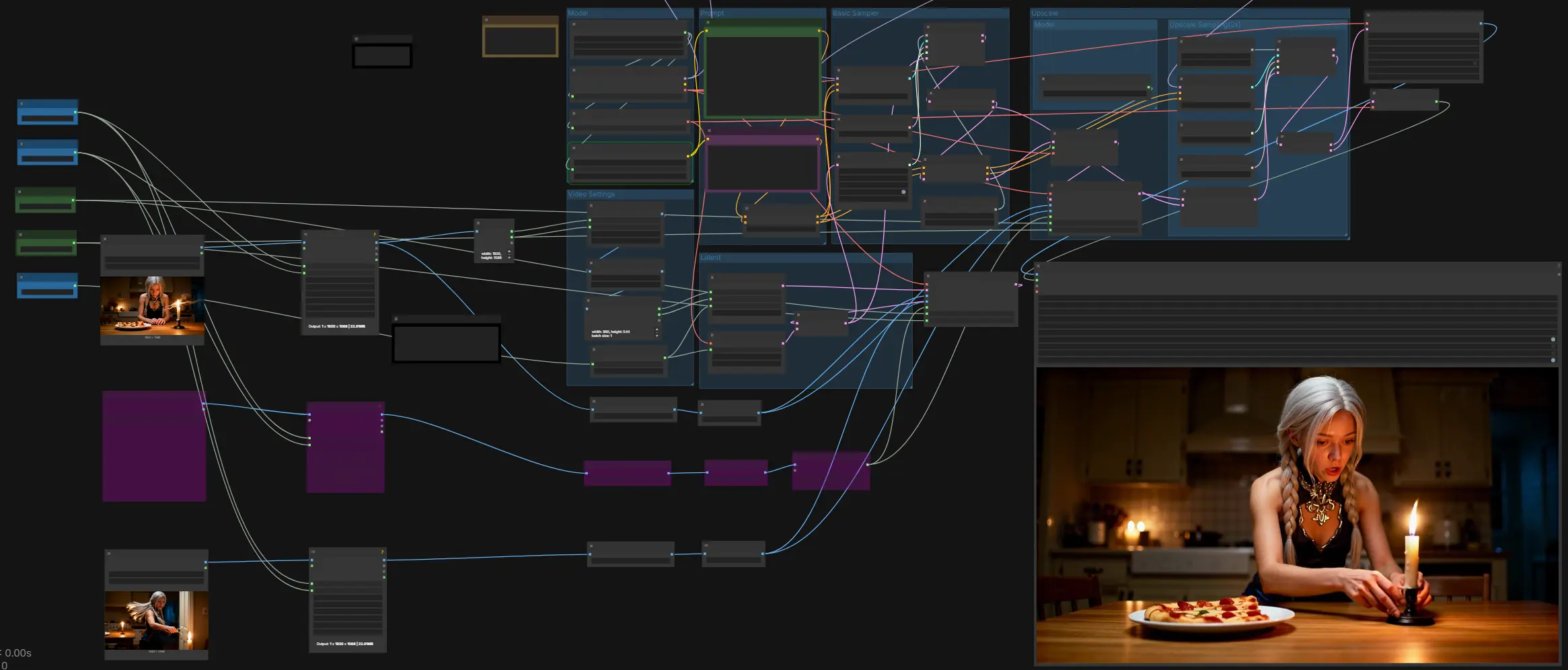
LTX-2 Erste Letzte Frame: Start-zu-Ende-kontrollierte, audio-synchronisierte Videogenerierung in ComfyUI#
LTX-2 Erste Letzte Frame ist ein ComfyUI-Workflow für Kreative, die präzise, filmische Bewegungen zwischen einem definierten Start- und Endbild wünschen, während synchronisiertes Audio und visuelle Effekte in einem Durchgang generiert werden. Durch die Konditionierung auf beiden Bildern (und optional einem leitenden Mittelbild) bewahrt die Pipeline Identität, Framing und Beleuchtung über die Aufnahme hinweg und lenkt die Bewegung, um genau auf dem letzten Bild zu landen. Es ist für narrative Beats, Titel- oder Szenenübergänge, Kamerabewegungen und jeden Moment konzipiert, in dem zeitliche Kontinuität und Audioausrichtung wichtig sind.
Angetrieben von dem LTX-2-Echtzeitmodell, hält der Workflow die Iteration schnell, während er feine Kontrolle über Eingabeaufforderungen, Kameraverhalten über LoRAs und die Stärke des ersten/letzten Bildes bietet. Das Ergebnis ist eine glatte, kohärente Sequenz, deren Timing, Aussehen und Ton Ihren Anweisungen vom ersten bis zum letzten Bild folgt.
Hinweis: Für Maschinentypen unter 2x Large verwenden Sie bitte das "ltx-2-19b-dev-fp8.safetensors"-Modell!
Schlüsselmodelle im ComfyUI LTX-2 Erste Letzte Frame-Workflow#
- LTX-2 19B (dev). Das Kernmodell zur Videogenerierung, das gemeinsame Audio-Video-Latents aus Text- und Frame-Kontrollen erzeugt; unterstützt Echtzeit-Iteration und kamera-bewusste LoRAs. Siehe das offizielle Repository und die Gewichte: Lightricks/LTX-2 auf GitHub und Lightricks/LTX-2 auf Hugging Face.
- Gemma 3 12B Instruct Text-Encoder für LTX-2. Bietet robuste, an Anweisungen angepasste Sprachverständnis für visuelle und auditive Eingabeaufforderungen in dieser Pipeline; verpackt für ComfyUI als LTX-kompatibler Text-Encoder. Gewichtsreferenz: Comfy-Org/ltx-2 split text encoders.
- LTXV Audio VAE (24 kHz Vocoder). Kodiert und dekodiert Audio-Latents, sodass der Soundtrack zusammen mit dem Video generiert wird und synchron mit der Bildschirmaktion bleibt. Siehe Modelfamilienkontext in Lightricks/LTX-2.
- LTX-2 Spatial Upscaler x2. Ein latenter Upscaler für sauberere Hochauflösungsergebnisse nach dem Basisdurchgang, verwendet während der Upscale-Sampling-Phase. Gewichte sind verfügbar unter Lightricks/LTX-2.
- LTX-2 LoRA-Paket für Kamerasteuerung und Detail. Optionale LoRAs wie Dolly In/Out/Left/Right, Jib Up/Down, Static und ein Image-Conditioning Detailer formen Kamerabewegung und feine Details. Durchsuchen Sie die offizielle Sammlung: Lightricks LTX-2 LoRAs.
So verwenden Sie den ComfyUI LTX-2 Erste Letzte Frame-Workflow#
Dieser Workflow bewegt sich von Eingaben und Eingabeaufforderungen zu einem Basis-Audio-Video-Sample, führt dann einen geführten 2x-Upscale-Pass durch, bevor er dekodiert und mit Audio in MP4 gemuxt wird. Er verlässt sich auf Kontrollen des ersten/letzten Bildes sowohl in den Basis- als auch Upscale-Phasen, wobei ein optionales Mittelbild hinzugefügt werden kann, um die Trajektorie zu stabilisieren.
Modell#
Die Modellgruppe lädt den LTX-2-Checkpoint, den Gemma 3 12B Instruct Text-Encoder und den LTXV Audio VAE. Verwenden Sie das ckpt_name-Panel, um zwischen Standard- und FP8-Varianten basierend auf Ihrer GPU zu wählen. Der Text-Encoder wird von LTXAVTextEncoderLoader bereitgestellt und speist sowohl positive als auch negative Eingabeaufforderungen. Der Audio-VAE ermöglicht die gemeinsame Audio-Video-Generierung, sodass Dialoge, Effekte oder Ambiente, die in der Eingabeaufforderung beschrieben werden, mit den visuellen Effekten erscheinen.
Eingabeaufforderung#
Schreiben Sie die Szene in die positive Eingabeaufforderung und listen Sie unerwünschte Merkmale in der negativen Eingabeaufforderung auf. Beschreiben Sie Aktionen im Laufe der Zeit, wichtige visuelle Spezifika und Tonevents in der Reihenfolge, in der sie auftreten sollen. Der LTXVConditioning-Block wendet Ihre Eingabeaufforderung zusammen mit der gewählten Bildrate an, sodass Timing und Bewegung konsistent interpretiert werden. Behandeln Sie das Audio als Teil der Eingabeaufforderung, wenn Sie Sprache, Effekte oder Ambiente benötigen.
Videoeinstellungen#
Stellen Sie Width, Height und die Gesamtanzahl der Video Frames ein, wählen Sie dann Length für die Steuerung der Abstände des ersten/letzten Bildes, falls erforderlich. Der Workflow stellt sicher, dass die Dimensionen den Modellanforderungen entsprechen und skaliert die Eingaben entsprechend. Wenn Ihre Eingabebilder größer sind, liest das Diagramm deren Größe, um die latente Leinwand zu initialisieren und die bereitgestellten Bilder anzupassen. Wählen Sie eine Bildrate, die Ihrer beabsichtigten Lieferung entspricht.
Latent#
Diese Gruppe erstellt ein leeres Video-Latent und ein passendes Audio-Latent, dann werden sie verkettet, sodass das Modell Audio und Video zusammen sampelt. Hier wird die Führung des ersten/letzten Bildes im Basisdurchgang erstmals injiziert. Ein Mittelbild bereitzustellen ist optional, aber nützlich, um Identität oder Schlüsselpose in der Mitte der Aufnahme zu stabilisieren. Das Ergebnis ist ein einzelnes AV-Latent, das für das Basissampling bereit ist.
Basis-Sampler#
Der Basisdurchgang verwendet zufälliges Rauschen, einen Scheduler und den konfigurierten Guider, um Ihre Eingabeaufforderung in ein kohärentes AV-Latent aufzulösen. Der Guider erhält positive und negative Konditionierungen sowie jedes LoRA-modifizierte Modell. Nach dem Sampling wird das Latent wieder in Video und Audio aufgeteilt, sodass das Video hochskaliert wird, während das Audio synchron bleibt. Diese Phase setzt die globale Bewegung, das Tempo und den Audio-Rhythmus, die der Upscale-Pass verfeinern wird.
Upscale#
Der Upscaler hebt das Latent auf eine höhere räumliche Auflösung, bevor ein zweiter Sampling-Durchgang durchgeführt wird. Die Steuerung des ersten/letzten Bildes wird bei dieser höheren Auflösung erneut angewendet, um die Anfangs- und Schlussbilder präzise zu fixieren. Sie können hier auch ein Mittelbild einspeisen, um Merkmale während des Upscales stabil zu halten. Das Ergebnis ist ein schärferes AV-Latent, das die geplante Bewegung bewahrt.
Modell#
Diese Modellgruppe lädt den LTX-2-Latent-Upscaler, der von der Upscale-Gruppe verwendet wird. Sie bereitet das spezifische x2-Raum-Modell vor und stellt es dem latenten Upsampler-Knoten zur Verfügung. Wechseln Sie die Modelle hier, wenn Sie mehrere Upscaler verwenden. Lassen Sie diese Gruppe unberührt, wenn Sie mit dem Standard-x2-Verhalten zufrieden sind.
Upscale Sampling(2x)#
Der zweite Durchgang führt geführtes Sampling auf dem hochskalierten Latent mit einem separaten Sampler und Sigma-Plan durch. Ein zuschneidungsbewusster Guide stimmt die Konditionierung auf die neue Auflösung ab, sodass Details konsistent bleiben. Das Ergebnis wird erneut in Video und Audio aufgeteilt, um dekodiert zu werden. Dieser Durchgang schärft hauptsächlich Kanten, verbessert kleine Texte oder Texturen und hält die Übereinstimmung des ersten/letzten Bildes aufrecht.
LTX-2-19b-IC-LoRA-Detailer#
Diese Gruppe wendet ein detailorientiertes LoRA an, das für den Bildkonditionierungsweg von LTX-2 abgestimmt ist. Aktivieren Sie es, wenn Sie mehr Mikrodetaillierung oder engere Texturen nach der Konditionierung auf echten Bildern wünschen. Halten Sie die Stärke moderat, um Ihre Eingabeaufforderung oder Bildbeschränkungen nicht zu überfordern. Wenn Ihre Eingaben bereits scharf und gut beleuchtet sind, können Sie dieses LoRA umgehen.
Kamerasteuerung-Dolly-In#
Verwenden Sie dieses LoRA, wenn die Kamera im Laufe der Zeit auf das Motiv zudrücken soll. Es neigt das Modell zu Vorwärtsbewegung, während es die Ziele des ersten/letzten Bildes respektiert. Kombinieren Sie es mit textlichen Hinweisen, die die Bewegung beschreiben, für den stärksten Effekt. Reduzieren Sie die Stärke, wenn die Bewegung Ihre beabsichtigte Einrahmung überschreitet.
Kamerasteuerung-Dolly-Out#
Wählen Sie dies, wenn die Aufnahme vom Motiv wegziehen soll. Es hilft, negativen Parallax und erweiternden Kontext zu schaffen, während die Sequenz fortschreitet. Halten Sie das letzte Bild mit Ihrer Ausgangskomposition in Einklang, um die Bewegung sauber abzuschließen. Kombinieren Sie es mit atmosphärischen Audio-Eingabeaufforderungen für filmische Enthüllungen.
Kamerasteuerung-Dolly-Left#
Wendet eine seitliche Bewegung nach links an, die als Dolly oder Truck gelesen wird. Gut für Gesprächsbeats oder Enthüllungen über ein Set. Wenn Objekte verschmieren oder driften, erhöhen Sie leicht die Stärke des ersten/letzten Bildes oder fügen Sie ein Mittelbild hinzu. Balancieren Sie mit kleinen textlichen Hinweisen wie "langsames Bewegen nach links", um das LoRA zu ergänzen.
Kamerasteuerung-Dolly-Right#
Das Spiegelbild von Dolly-Left, dies neigt die Bewegung zur rechten Seite. Es funktioniert gut, um einem Charakter zu folgen oder zu einem neuen Motiv zu schwenken. Halten Sie die LoRA-Stärke bescheiden, wenn Sie auch einen Schub anfordern, um widersprüchliche Signale zu vermeiden. Stellen Sie sicher, dass die Komposition des letzten Bildes Ihrem gewünschten Endpunkt entspricht.
Kamerasteuerung-Jib-Up#
Erzeugt einen vertikalen Aufstieg, nützlich für Enthüllungen oder Eröffnungsszenen. Kombinieren Sie es mit flachen Eingabeaufforderungen über Perspektivwechsel und Horizontverschiebung für Klarheit. Wenn die Bewegung stark ist, achten Sie auf Decken oder Himmelsbelichtung; passen Sie die negative Eingabeaufforderung an, um überbelichtete Highlights zu vermeiden. Falls nötig, fügen Sie ein Mittelbild hinzu, das die Einrahmung der mittleren Erhebung zeigt.
Kamerasteuerung-Jib-Down#
Erzeugt einen kontrollierten Abstieg, der oft verwendet wird, um sich auf ein Detail oder einen Charakter zu konzentrieren. Es kann mit einem ruhigeren Audiobett für Betonung kombiniert werden. Stellen Sie sicher, dass das letzte Bild das Zielobjekt oder Gesicht enthält, damit sich die Bewegung entscheidend auflöst. Passen Sie die LoRA-Stärke an, wenn der Abstieg zu schnell erscheint.
Kamerasteuerung-Static#
Sperrt die virtuelle Kamera an Ort und Stelle, wenn Sie Aktion ohne Kamerabewegung wünschen. Dies ist nützlich für Dialog- oder Produktaufnahmen, bei denen sich nur das Motiv bewegt. Kombinieren Sie es mit der Kontrolle des ersten/letzten Bildes, um die Komposition perfekt stabil zu halten. Fügen Sie subtile Bewegung über die Texteingabeaufforderung hinzu, anstatt ein Kamera-LoRA.
Schlüssel-Knoten im ComfyUI LTX-2 Erste Letzte Frame-Workflow#
LTXVFirstLastFrameControl_TTP (#227)#
Injiziert erste und letzte Bildbeschränkungen in das Basis-AV-Latent. Passen Sie first_strength an, um zu steuern, wie streng das erste Bild übereinstimmt, und last_strength, um zu bestimmen, wie stark die Sequenz auf dem letzten Bild landet. Wenn die Mitte des Clips driftet, geben Sie ein Mittelbild über LTXVMiddleFrame_TTP ein und halten Sie die Stärken moderat, um Bewegungen nicht zu stark einzuschränken.
LTXVMiddleFrame_TTP (#181)#
Fügt optional ein leitendes Bild an einer gewählten position zwischen Start und Ende ein, um Identität oder Pose zu stabilisieren. Erhöhen Sie strength, wenn sich das Motiv zu stark in der Mitte des Schusses ändert. Verwenden Sie es sparsam; die besten Ergebnisse kommen von einem einzelnen, gut gewählten mittleren Referenzbild anstelle vieler konkurrierender Einschränkungen.
LTXVLatentUpsampler (#217)#
Führt das x2-räumliche Upscale im latenten Raum mit dem LTX-2-räumlichen Upscaler durch. Verwenden Sie dies vor dem 2x-Sampling-Durchgang, damit die hochauflösenden Details vom Modell verfeinert werden, anstatt gedehnt zu werden. Wenn der Speicher knapp ist, halten Sie die LoRA-Nutzung während dieser Phase minimal.
LTXVFirstLastFrameControl_TTP (#223)#
Wendet Start-/Ende- (und optional mittlere) Führung nach dem x2-Upscale erneut an. Dies stellt sicher, dass die endgültigen dekodierten Bilder Ihre ersten und letzten Referenzen präzise bei der Lieferauflösung entsprechen. Wenn der Upscale Mikroverschiebungen einführt, erhöhen Sie leicht last_strength hier, anstatt in der Basisphase.
LTXVSpatioTemporalTiledVAEDecode (#230)#
Dekodiert das hochauflösende Video-Latent zu Frames unter Verwendung von spatio-temporaler Kachelung. Passen Sie Kachel- und Überlappungseinstellungen nur an, wenn Sie Nähte oder temporales Flimmern sehen; größere Überlappung kostet mehr VRAM, verbessert jedoch die Konsistenz. Halten Sie last_frame_fix für Grenzfälle, in denen das letzte Bild eine geringfügige Drift zeigt.
VHS_VideoCombine (#254)#
Muxes dekodierte Frames und das generierte Audio zu einer einzigen MP4. Stellen Sie die Ausgabe format, pix_fmt und crf für Ihr Lieferziel ein und wählen Sie eine frame_rate, die mit der Konditionierung übereinstimmt. Aktivieren Sie das Speichern von Metadaten, um Reproduzierbarkeitsaufzeichnungen mit jedem Render zu behalten.
Optionale Extras#
- Verwenden Sie FP8-Gewichte von LTX-2, wenn Ihre GPU begrenzt ist; wechseln Sie zurück zu voller Präzision für die höchste Wiedergabetreue, wenn der VRAM dies zulässt. Gewichte sind in Lightricks/LTX-2.
- Dimensionen funktionieren am besten, wenn Breite und Höhe die Form 32n + 1 haben; Gesamtrahmen funktionieren am besten als 8n + 1. Der Workflow korrigiert automatisch auf die nächstgelegenen gültigen Werte, falls erforderlich.
- Beschreiben Sie Audiocues direkt in Ihrer positiven Eingabeaufforderung (Dialoge, Effekte, Ambiente). Das gemeinsame AV-Latent des Modells hält Lippen, Aktionen und Geräusche ausgerichtet.
- Beginnen Sie mit moderaten Stärken des ersten/letzten Bildes; erhöhen Sie die letzte Stärke, um die endgültige Pose zu treffen, oder fügen Sie ein Mittelbild hinzu, um die Identität zu stabilisieren.
- Wenden Sie jeweils nur ein Kamera-LoRA an, um eine klare Absicht zu haben. Durchsuchen Sie die offiziellen Optionen in der Lightricks LTX-2 LoRA-Sammlung.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken @AIKSK für das LTX-2 Erste Letzte Frame Workflow Reference für ihre Beiträge und Wartung. Für autoritative Details verweisen Sie bitte auf die Originaldokumentationen und -repositories, die unten verlinkt sind.
Ressourcen#
- RunningHub/LTX-2 Erste Letzte Frame Workflow Reference
- Docs / Release Notes: LTX-2 Erste Letzte Frame Workflow Reference von AIKSK