
LTX-2 ControlNet: strukturgeführte, audio-synchronisierte Videogenerierung in ComfyUI#
LTX-2 ControlNet ist ein kontrollgetriebener ComfyUI-Workflow für die ComfyUI-LTXVideo-Erweiterung, mit der Sie die LTX-2-Videogenerierung mit Tiefen-, Canny-Kanten- und Pose-Leitlinien steuern können, während Audio und visuelle Inhalte synchron bleiben. Es läuft in einem einheitlichen audio-visuellen latenten Raum, sodass Sprache, Geräuscheffekte und Bewegung zusammen erzeugt und vom ersten bis zum letzten Frame ausgerichtet bleiben.
Entwickelt für Text-zu-Video-, Bild-zu-Video- und Video-zu-Video-Anwendungen, fügt der Workflow IC LoRA-basierte ControlNet-Konditionierung für präzise Layout- und Bewegungssteuerung hinzu, Erst-Frame-Initialisierung für Szenenkontinuität und eine zweistufige Pipeline mit latentem Upscaling für scharfe Ergebnisse ohne VRAM-Belastung. LTX-2 ControlNet ist vollständig offen, schnell iterierbar und produktionsorientiert für Schöpfer, die wiederholbare, hochwertige Ausgaben benötigen.
Schlüsselmodelle im ComfyUI LTX-2 ControlNet-Workflow#
- LTX-2 19B (dev FP8 und destilliert). Kernmodell für audio-visuelle Generierung, das zur Probenahme von Video und Audio in einem einzigen latenten Raum verwendet wird. Model family
- Gemma 3 12B IT Text-Encoder. Bietet robustes Sprachverständnis für Eingabeaufforderungen und Negativa über den von LTX-2 verwendeten integrierten Encoder. Encoder file
- LTX-2 Spatial Upscaler x2. Latentes Upscaling-Modell, das in Phase zwei zur Verfeinerung räumlicher Details verwendet wird. Upscaler
- LTX-2 Audio VAE. Spezialisierter Audio-Decoder-Encoder, der den erzeugten Klang mit den Frames ausgerichtet hält. In LTX-2-Checkpoints enthalten. Checkpoints
- IC LoRA Kontrollfamilie für LTX-2. Fügt ControlNet-Style-Konditionierung hinzu:
- Tiefenkontroll-LoRA: ltx-2-19b-IC-LoRA-Depth-Control
- Canny-Kontroll-LoRA: ltx-2-19b-IC-LoRA-Canny-Control
- Pose-Kontroll-LoRA: ltx-2-19b-IC-LoRA-Pose-Control
- Destillierte LoRA für Qualitäts-/Effizienzkompromisse: ltx-2-19b-distilled-lora-384
- Lotus Depth D v1.1. Tiefenschätzer, der im Tiefenkontrollpfad verwendet wird. Model
- SD VAE FT MSE (Stability AI). Bild-VAE, das zur Tiefenvorberechnung und gekachelten Dekodierung verwendet wird. VAE
- ComfyUI-LTXVideo-Erweiterung. Bietet die LTX-2-Sampler, AV-Latenten, Audio-VAE und Leitknoten, die überall verwendet werden. Repository
Verwendung des ComfyUI LTX-2 ControlNet-Workflows#
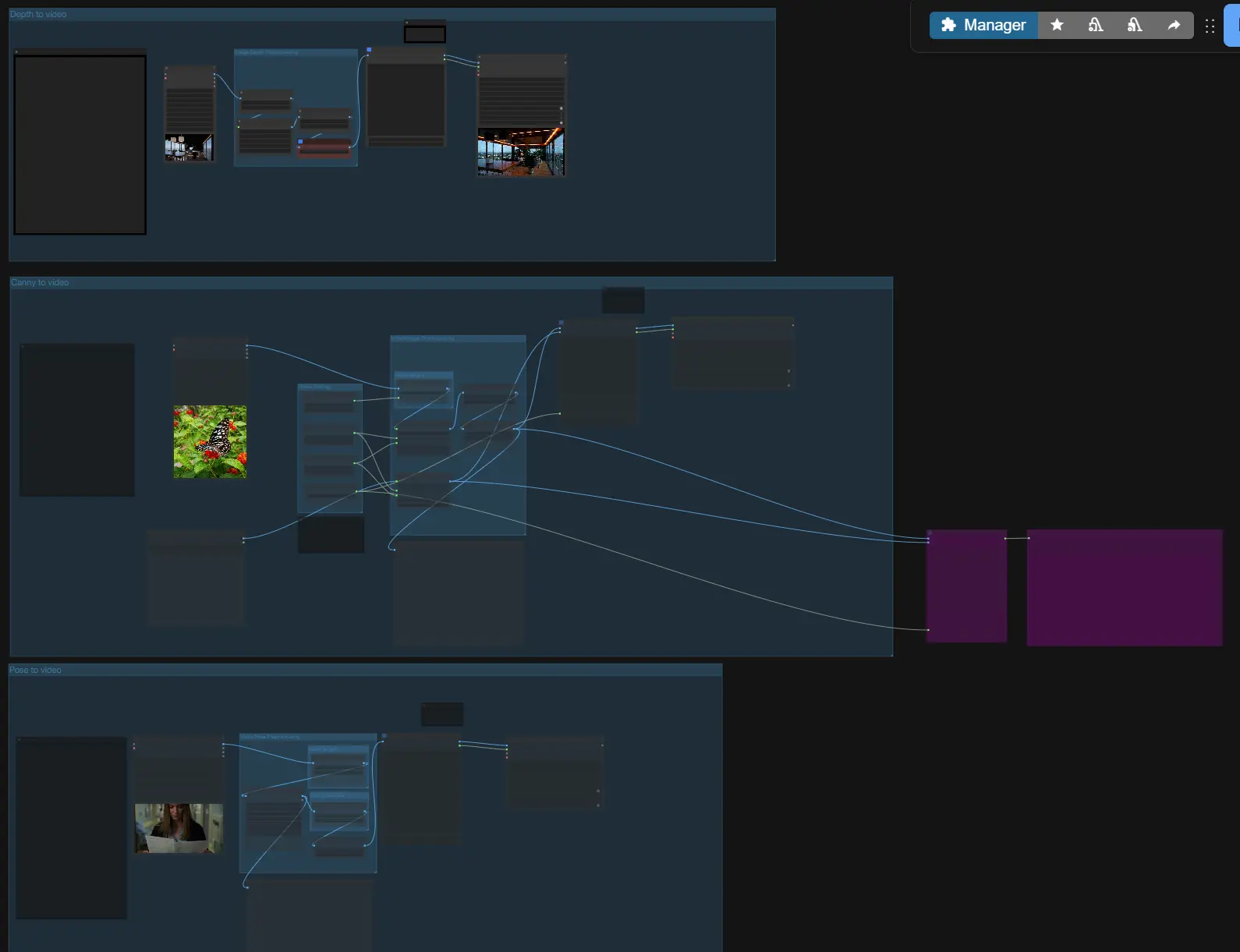
Auf hohem Niveau nimmt LTX-2 ControlNet Ihre Eingabeaufforderung und optionale Referenzen, baut einen audio-visuellen Latenten mit ControlNet-Style-Leitlinien, probiert einen ersten Durchgang, und skaliert dann den Latenten für scharfe Videos und synchronisiertes Audio hoch. Wählen Sie einen von drei geführten Pfaden (Tiefe, Canny, Pose) oder verwenden Sie sie unabhängig, dann legen Sie Länge und Größe fest, bevor Sie exportieren.
- Bild/Video-Vorverarbeitung
- Wenn Sie Bild-zu-Video oder Video-zu-Video machen, verwenden Sie die Loader, um Ihre Referenzmedien zu importieren.
VHS_LoadVideo(#196, #197, #198) teilt Frames zur Analyse, währendLoadImage(#189) Standbilder verarbeitet. Die Gruppe bietet eine bequeme Skalierung, sodass die nachgeschalteten Leitfäden konsistente Frame-Größen sehen. - Ein "Erst-Frame"-Bild kann zur Szeneninitialisierung weitergeleitet werden; Sie werden es später in der Generierungsgruppe aktivieren.
- Wenn Sie Bild-zu-Video oder Video-zu-Video machen, verwenden Sie die Loader, um Ihre Referenzmedien zu importieren.
- Bildtiefenvorverarbeitung
- Für Tiefenleitlinien konvertiert der "Image to Depth Map (Lotus)"-Untergraph Ihre Eingabe in eine normalisierte Tiefenkarte mit Lotus Depth. Dies bereitet eine Einzelbild- oder Mehrbild-Tiefendarstellung vor, der LTX-2 folgen kann.
- Der Pfad umfasst optionale Größenanpassungen und Intensitätskontrollen, sodass der Leitfaden eine breite Struktur codiert, ohne sich auf kleine Artefakte zu überanpassen.
- Video-Pose-Vorverarbeitung
- Für Pose-Leitlinien erkennt
DWPreprocessor(#158) vollständige Körper-Schlüsselpunkte aus dem Eingabevideo und skaliert sie für stabile Konditionierung. Dies ergibt eine saubere Pose-Bildsequenz, die Skelett- und Gliedmaßenorientierung betont. - Vorschauknoten helfen Ihnen, schnell zu überprüfen, ob Erkennungen und Seitenverhältnisse vor der Generierung korrekt aussehen.
- Für Pose-Leitlinien erkennt
- Canny zu Video
- Dieser Kontrollpfad extrahiert Kanten mit
Canny(#169) und baut dann einen AV-Latenten mit der Kontrollbildsequenz. Verwenden Sie ihn, wenn Sie Silhouetten, Hauptkonturen oder Typografiekanten aus einer Referenz erhalten möchten. - Ein Erst-Frame-Bildeingang ist für eine konsistente Initialisierung verfügbar; aktivieren Sie ihn nur, wenn Sie möchten, dass der Eröffnungsframe einem bestimmten Standbild entspricht.
- Dieser Kontrollpfad extrahiert Kanten mit
- Tiefe zu Video
- Dieser Pfad speist die Lotus-Tiefenkarten als Kontrollbilder ein. Tiefenkontrolle ist ideal, um Kamerageometrie, großflächiges Layout und Subjektdistanz zu erzwingen, während der Generator Texturen und Beleuchtung auswählen kann.
- Sie können einen Erst-Frame angeben, um die anfängliche Komposition zu sperren und dann die Bewegung durch Tiefenhinweise leiten zu lassen.
- Pose zu Video
- Der Pose-Pfad verwendet das Schlüsselpunkt-Rendering aus dem Preprozessor, um Körperorientierung und Bewegungstiming zu steuern. Er ist besonders effektiv für Charakterblockierung, Handhebungstiming und Gehzyklen.
- Wie bei anderen Modi können Sie Eingabeaufforderungszeitplanung mit optionaler Erst-Frame-Konditionierung für Kontinuität kombinieren.
- Videoeinstellungen und Länge
- Stellen Sie die Arbeitsbreite, Höhe und Frame-Anzahl in den Gruppen "Videoeinstellungen" und "Videolänge" ein. Der Workflow passt ungültige Werte automatisch an die nächstgelegenen kompatiblen Größen für LTX-2's latentes Raster und Schritt an, sodass Sie sicher iterieren können.
- Halten Sie Ihre Zielbildrate über alle Knoten hinweg konsistent; die Konditionierungsknoten und das finale Mux respektieren sie für eine reibungslose audio-visuelle Synchronisation.
- Generierung, Upscaling und Export
- Während der Probenahme integriert
LTXVAddGuideIhre positive/negative Konditionierung mit den ausgewählten Kontrollbildern, dann führtSamplerCustomAdvancedden Zeitplan vonLTXVSchedulerfür sowohl Video- als auch Audio-Latenten aus. Der optionale Erst-Frame wird mitLTXVImgToVideoInplaceeingefügt, wo aktiviert. - Die zweite Phase läuft
LTXVLatentUpsampler, um Details mit dem x2 latenten Upscaler zu verfeinern. Die finale Dekodierung erfolgt mit gekacheltemVAEDecodeTiledfür Frames undLTXVAudioVAEDecodefür Audio, dann wird das Video je nach gewähltem Zweig mitVHS_VideoCombineoderCreateVideogeschrieben.
- Während der Probenahme integriert
Schlüsselnoten im ComfyUI LTX-2 ControlNet-Workflow#
LTXVAddGuide(#132)- Vereint Text-Konditionierung und IC LoRA-Kontrollen in den AV-Latenten und fungiert als Herzstück der LTX-2 ControlNet-Leitlinien. Passen Sie nur die wenigen Kontrollen an, die wichtig sind: Wählen Sie die Kontroll-LoRA, die zu Ihrem Pfad passt (Tiefe, Canny oder Pose) und, wo verfügbar, die
image_strength, die anpasst, wie eng das Modell den Leitlinien folgt. Referenzimplementierung und Knotenverhalten werden von der LTXVideo-Erweiterung bereitgestellt. Docs/Code
- Vereint Text-Konditionierung und IC LoRA-Kontrollen in den AV-Latenten und fungiert als Herzstück der LTX-2 ControlNet-Leitlinien. Passen Sie nur die wenigen Kontrollen an, die wichtig sind: Wählen Sie die Kontroll-LoRA, die zu Ihrem Pfad passt (Tiefe, Canny oder Pose) und, wo verfügbar, die
LTXVImgToVideoInplace(#149, #155)- Integriert ein Erst-Frame-Bild in den AV-Latenten für eine konsistente Szeneninitialisierung. Verwenden Sie
strength, um die Treue zum ersten Frame gegenüber der Freiheit zur Entwicklung auszugleichen; halten Sie es niedriger für mehr Bewegung und höher für engere Anker. Umgehen Sie es, wenn Sie rein text- oder kontrollgesteuerte Eröffnungen wünschen. Docs/Code
- Integriert ein Erst-Frame-Bild in den AV-Latenten für eine konsistente Szeneninitialisierung. Verwenden Sie
LTXVScheduler(#95)- Steuert die Entstörungsbahn für den einheitlichen Latenten, sodass Audio und Video zusammen konvergieren. Erhöhen Sie die Schritte für komplexe Szenen und feine Details; verkürzen Sie sie für Entwürfe und schnelle Iterationen. Zeitplaneinstellungen interagieren mit Leitstärke, vermeiden Sie also extreme Werte, wenn die Leitung stark ist. Docs/Code
LTXVLatentUpsampler(#112)- Führt das zweite Stadium des latenten Upscalings mit dem LTX-2 x2 räumlichen Upscaler durch und verbessert die Schärfe bei minimalem VRAM-Wachstum. Verwenden Sie es nach dem ersten Durchlauf anstelle der Erhöhung der Basisauflösung, um Iterationen reaktionsschnell zu halten. Upscaler model
DWPreprocessor(#158)- Erzeugt saubere menschliche Pose-Schlüsselpunkte für den Pose-Kontrollpfad. Überprüfen Sie Erkennungen mit der Vorschau; wenn Hände oder kleine Gliedmaßen verrauscht sind, skalieren Sie Eingaben auf eine moderate Maximaldimension vor der Vorverarbeitung. Bereitgestellt durch die ControlNet-Auxiliary-Suite. Repo
VHS_VideoCombine/CreateVideo(#195, #106)- Muxes dekodierte Frames und Audio in eine MP4 mit der ausgewählten Bildrate und Pixelformat. Verwenden Sie diese nur, nachdem Sie bestätigt haben, dass Ihr Audio-Dekodierung in der Vorschau ausgerichtet aussieht. Bereitgestellt von der Video Helper Suite. Repo
Optionale Extras#
- Eingabeaufforderungen für LTX-2 ControlNet
- Beschreiben Sie Handlungen über die Zeit, nicht nur statische Attribute.
- Fügen Sie benötigte Klanghinweise oder Dialoge hinzu, sodass Audio im Takt generiert wird.
- Verwenden Sie eine prägnante negative Eingabeaufforderung, um Artefakte zu unterdrücken, die Sie wiederholt sehen.
- Größen und Längen
- Verwenden Sie Bildgrößen der Form 32k + 1 für Breite/Höhe; der Graph korrigiert automatisch, wenn Sie sich irren, aber genaue Werte beschleunigen die Iteration.
- Bildzählungen der Form 8k + 1 sind für die Planung am stabilsten.
- Erst-Frame-Konsistenz
- Aktivieren Sie den Erst-Frame nur, wenn Sie eine gesperrte Eröffnungskomposition benötigen; kombinieren Sie ihn mit moderater
image_strength, um Überbeschränkungen zu vermeiden.
- Aktivieren Sie den Erst-Frame nur, wenn Sie eine gesperrte Eröffnungskomposition benötigen; kombinieren Sie ihn mit moderater
- VRAM und Durchsatz
- Der Workflow enthält sequenzparallele und Torch-Compile-Optionen im LTXVideo-Patcher für Multi-GPU- oder speicherbeschränkte Setups. Halten Sie sie für lange Clips eingeschaltet, aus, wenn Sie das Knotenverhalten debuggen. Extension
Anerkennungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Lightricks für ComfyUI-LTXVideo für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die Originaldokumentation und Repositories, die unten verlinkt sind.
Ressourcen#
- ComfyUI-LTXVideo GitHub Repository: https://github.com/Lightricks/ComfyUI-LTXVideo
- GitHub: Lightricks/ComfyUI-LTXVideo
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreuern bereitgestellt werden.
