
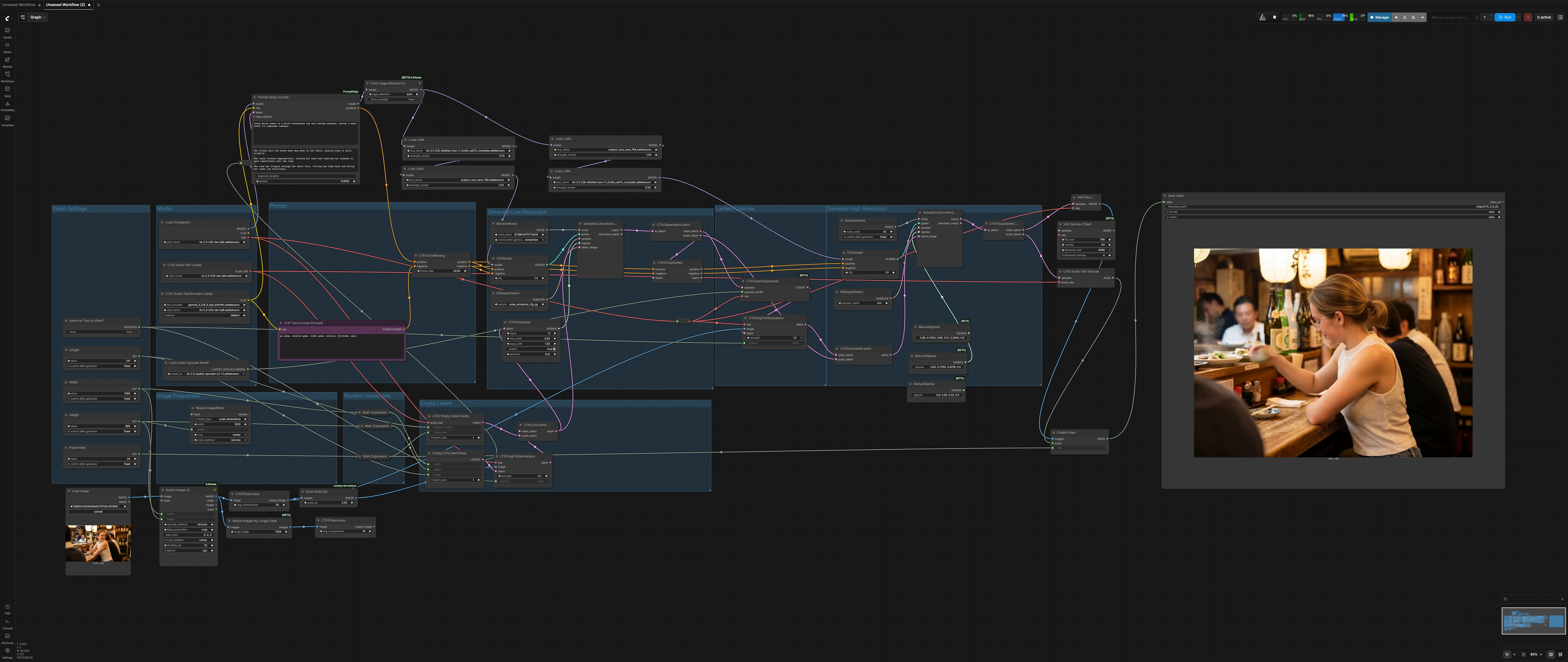
LTX 2.3 Sulphur Bild-zu-Video-Workflow: filmisches Bild-zu-Video mit steuerbarer Bewegung#
Dieser LTX 2.3 Sulphur Bild-zu-Video-Workflow verwandelt ein einzelnes Standbild in eine veröffentlichungsreife filmische Aufnahme mit natürlichen Mikroausdrücken, glaubwürdiger Charakterbewegung und stabiler atmosphärischer Kontinuität. Er ist speziell für Erzählaufnahmen konzipiert, bei denen Sie die Kontrolle über Kameragefühl, Stimmung und Szenendynamik haben möchten, ohne sich in den Einrichtungsdetails zu verlieren.
Der Workflow läuft in einer zweistufigen Diffusionspipeline rund um LTX-2.3: ein Durchgang mit niedriger Auflösung zur Festlegung von Bewegung und Timing, gefolgt von einem latenten Upscaling und einem hochauflösenden Verfeinerungsdurchgang für das endgültige Detail. Ein Sulphur-Stil-LoRA steuert Look und Hauttöne, während die Prompt-Segmentierung die Entwicklung der Beats über die Aufnahme hinweg unterstützt. Schalten Sie einen einzigen Schalter um, um bei Bedarf klassisches Bild-zu-Video oder reines Text-zu-Video auszuführen.
Wichtige Modelle im ComfyUI LTX 2.3 Sulphur Bild-zu-Video-Workflow#
- Lightricks LTX-2.3-22B dev FP8. Der Basis-Video-Diffusions-Checkpoint, der die Generierung und Decodierung antreibt und dabei den Speicherverbrauch praktikabel hält. Model card
- LTX-2.3 Spatial Upscaler x2. Ein latentes Super-Resolution-Modell, das zwischen den Durchgängen verwendet wird, um Bewegung zu bewahren und gleichzeitig die räumliche Treue zu erhöhen. Model page
- Gemma 3 12B anweisungsgestimmter Text-Encoder, gepackt für LTX. Ermöglicht reichhaltige, fundierte Konditionierung für globale und Segment-Prompts. Repository
- Sulphur-Stil-LoRA und LTX-2.3 destilliertes LoRA 1.1. Paired LoRAs, die die Gesichtsrealität und den filmischen Ton stabilisieren und gleichzeitig die Prompt-Kontrolle beibehalten.
So verwenden Sie den ComfyUI LTX 2.3 Sulphur Bild-zu-Video-Workflow#
Gesamtfluss: Legen Sie die Abmessungen und die Länge der Aufnahme fest, bereiten Sie Ihr Standbild vor, definieren Sie ein globales Prompt sowie optionale lokale Prompt-Beats und rendern Sie dann. Die Phase mit niedriger Auflösung baut Bewegung und Timing auf, der latente Upscaler hebt Details hervor, und die hochauflösende Phase finalisiert Textur und Beleuchtung, bevor sie in MP4 decodiert wird.
Videoeinstellungen#
Wählen Sie Ihre Zielmaße Width, Height, Length (Frames) und Frame Rate. Die Abmessungen sind so eingestellt, dass sie durch gängige Diffusionsgittergrößen teilbar sind, um Artefakte zu vermeiden. Ein einzelnes boolesches Switch to Text to Video? (#28) steuert, ob das Standbild injiziert oder umgangen wird. Halten Sie das Seitenverhältnis konsistent mit dem Eingabebild für das sauberste Framing, insbesondere für Gesichter und Hände.
Bildvorbereitung#
Ihr Quell-Standbild wird geladen, in der Größe angepasst und leicht komprimiert, um es diffusionsbereit zu machen, unter Verwendung von ImageResizeKJv2 (#75) und LTXVPreprocess (#76). Eine skalierte Version wird an den Durchgang mit niedriger Auflösung übergeben, um stabile Bewegungen zu erzeugen, während die höher detaillierte Version für die hochauflösende Phase verfügbar ist. Verwenden Sie diesen Abschnitt, um das Framing und den Spielraum vor der Generierung abzustimmen. Subtile Vorab-Schnittanpassungen zahlen sich hier in konsistenteren Augenlinien und Hintergrundkontinuität aus.
Leeres Latent#
EmptyLTXVLatentVideo (#21) und LTXVEmptyLatentAudio (#33) konstruieren synchronisierte Video- und Audio-Latents unter Verwendung Ihrer Aufnahme-Einstellungen. Sie werden von LTXVConcatAVLatent (#32) zusammengeführt, um ein Zeitachse-Gerüst zu erstellen, das nachgelagerte Knoten verfeinern werden. Der Audiozweig erstellt eine stille, gültige Spur, sodass das endgültige MP4 überall zuverlässig abgespielt wird. Diese Latents verankern auch Prompt-Segmente, sodass Bewegungsänderungen dort landen, wo Sie es erwarten.
Prompt#
Verfassen Sie Ihre Aufnahmebeschreibung in PromptRelayEncode (#80). Verwenden Sie ein prägnantes globales Prompt für das Gesamtbild und fügen Sie beat-spezifische Zeilen als lokale Prompts hinzu, getrennt durch das | Zeichen, um Mikroaktionen über den Clip hinweg zu entwickeln. Der LTX-Text-Encoder von LTXAVTextEncoderLoader (#5) verarbeitet die Semantik, während CLIPTextEncode (#41) ein stark realismusorientiertes Negativ-Prompt bietet. LTXVConditioning (#31) mischt positive und negative Konditionierung und synchronisiert sie mit der Bildrate.
Modell#
CheckpointLoaderSimple (#44) lädt das LTX-2.3-Basis. PathchSageAttentionKJ (#67) optimiert die Aufmerksamkeit für große Bilder. Eine kurze LoRA-Kette wendet den Sulphur-Stil und ein destilliertes Stabilitäts-LoRA vor jeder Sampling-Phase an. Dieses Design balanciert Konsistenz des Aussehens mit Prompt-Reaktionsfähigkeit, sodass Charakteridentität und Beleuchtung zwischen den Durchgängen kohärent bleiben.
Generieren niedriger Auflösung#
Dieser erste Diffusionsdurchgang etabliert Bewegung. LTXVImgToVideoInplace (#22) injiziert Ihr vorverarbeitetes Standbild in die Zeitachse; wenn Switch to Text to Video? aktiviert ist, deaktiviert sein bypass-Eingang sauber die Bildinjektion für reines T2V. LTXVScheduler (#47) formt den Sigma-Zeitplan, um Bewegungsamplitude und zeitliche Glätte zu steuern. SamplerCustomAdvanced (#9), angetrieben von CFGGuider (#42) und KSamplerSelect (#17), synthetisiert ein kohärentes Low-Res A/V Latent. LTXVSeparateAVLatent (#35) teilt dann die Video- und Audiopfade und leitet die Framing-Informationen an LTXVCropGuides (#10) für kompositionsbewusste Führung weiter.
Latentes Upscaling#
LTXVLatentUpsampler (#13) mit dem LTX-2.3 Spatial Upscaler hebt räumliche Details im latenten Raum hervor, während die in der ersten Phase gelernte Bewegung erhalten bleibt. Upscaling hier vermeidet die Neuerfindung des Timings und reduziert Flimmern, das oft bei naiver zweiter Pass-Generierung zu sehen ist. Es liefert ein schärferes, bewegungskonsistentes Latent an die endgültige Verfeinerungsphase.
Generieren hoher Auflösung#
Die verfeinerte Phase kombiniert das hochskalierte Video-Latent und das Audio-Latent über LTXVConcatAVLatent (#3). CFGGuider (#8) und KSamplerSelect (#6) steuern einen schnellen, detailorientierten Sampler in SamplerCustomAdvanced (#36) unter Verwendung eines abgestimmten Sigma-Zeitplans für das Finishing. Wenn Sie die Bildinjektion aktiviert gelassen haben, hilft ein zweites LTXVImgToVideoInplace (#14) dem Modell, das Standbild in hoher Auflösung zu respektieren, ohne die bereits etablierte Bewegung zu verlieren. Das Ergebnis ist eine stabile, filmische Sequenz mit natürlichen Augen- und Munddynamiken.
Ausgabe#
VAEDecode (#68) wandelt das finale Video-Latent in Frames um, während LTXVAudioVAEDecode (#23) die stille Audiospur rekonstruiert. CreateVideo (#38) muxes Frames und Audio mit Ihrer gewählten Bildrate, und SaveVideo (#45) schreibt ein H.264 MP4 zur sofortigen Überprüfung und zum Teilen. Verwenden Sie einen beschreibenden Dateinamen-Präfix pro Aufnahme, um Iterationen organisiert zu halten.
Zahlumwandlung#
Ein kleiner Dienstblock berechnet halbskalierte Größen für die latente Konstruktion, um VRAM zu verwalten und Geschwindigkeit zu erhöhen. Normalerweise müssen Sie diese nicht anfassen, aber sie stellen sicher, dass die upstream Breite und Höhe alles konsistent steuern. Wenn Sie die Basisauflösung ändern, passen sich diese automatisch an.
Wichtige Knoten im ComfyUI LTX 2.3 Sulphur Bild-zu-Video-Workflow#
PromptRelayEncode(#80). Zentralisiert ein globales Prompt und beat-für-beat lokale Prompts, die an die Zeitleiste angepasst sind. Verwenden Sie es, um Mikroausdrücke und kleine Kameraveränderungen über die Aufnahme hinweg zu skripten. Halten Sie lokale Prompts kurz und spezifisch, damit sie das globale Aussehen ergänzen, anstatt dagegen zu kämpfen.LTXVImgToVideoInplace(#22, #14). Integriert das Standbild in niedrige und hohe Auflösungs-Latents. Erhöhen Siestrength, wenn Sie möchten, dass das Finale eng am Referenzrahmen haftet; reduzieren Sie es für mehr Freiheit. Derbypass-Eingang ist an den Text-zu-Video-Schalter angeschlossen, sodass Sie die Bildinjektion für T2V-Läufe sauber deaktivieren können.LTXVScheduler(#47). Kontrolliert, wie sich die Rauschpegel während der Phase mit niedriger Auflösung entwickeln, was sich direkt auf Bewegungsintensität und Glätte auswirkt. Verwenden Sie es, um überaktive Aufnahmen zu zähmen oder einen subtilen Schub zu geben, wenn sich Dinge statisch anfühlen. Anpassungen hier sind am auffälligsten bei Gesichtern, Haaren und handgehaltener Kameraenergie.LTXVLatentUpsampler(#13). Führt x2 latentes Upscaling mit LTXs räumlichem Upscaler durch, wobei Bewegungsmerkmale aus der ersten Phase erhalten bleiben. Verwenden Sie es, um scharfe Texturen und Kantendefinition vor der hochauflösenden Verfeinerung hinzuzufügen, ohne das Timing neu zu rollen.CFGGuider(#42, #8). Balanciert, wie stark das Modell Ihren Prompts gegenüber seinen gelernten Prioritäten folgt. Wenn Gesichter abweichen oder der Stil schwächer wird, erhöhen Sie die Führung; wenn Details übertrieben oder plastisch aussehen, reduzieren Sie sie. Paaren Sie Änderungen mit einem kurzen Blick auf das negative Prompt, um den Realismus zu erhalten.KSamplerSelect(#17, #6). Ermöglicht die Auswahl des Sampling-Algorithmus pro Phase. Bevorzugen Sie einen robusten, ausdrucksstarken Sampler für die Phase mit niedriger Auflösung und eine schnelle, detailfreundliche Option für die Finishing-Phase. Halten Sie die Wahl konsistent über Iterationen hinweg, wenn Sie Aussehen vergleichen.
Optionale Extras#
- Für gezieltes Kameraverhalten können Sie ein Kamera-Kontroll-LoRA wie Dolly-Left aus der LTX-Familie zu Ihrer LoRA-Ladekette hinzufügen, wenn Sie einen konsistenten lateralen Schub wünschen. Model page
- Halten Sie Breite und Höhe durch 32 teilbar, um Fehlausrichtung bei latenten Operationen zu vermeiden und die VRAM-Effizienz zu erhalten.
- Verwenden Sie kurze, aktive Verben in lokalen Prompts, um Beats zu choreographieren, zum Beispiel Griff straffen, Blick abwenden, Lächeln mildern.
- Wenn Sie sehr hohe Ausgabegrößen anstreben, erwägen Sie,
VAEDecodedurchVAEDecodeTiled(#43) zu ersetzen, um Frames speichereffizienter zu decodieren. - Wenn Gesichter am wichtigsten sind, iterieren Sie, indem Sie nur den Prompt-Text und
CFGGuideranpassen, bevor Sie Sampler oder Auflösung ändern. Dies hält Vergleiche sinnvoll und bringt die beste Formulierung für den LTX 2.3 Sulphur Bild-zu-Video-Workflow hervor.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken RunningHub für die Workflow-Referenz, Lightricks für die LTX 2.3 Familie (Modell, räumlicher Upscaler und Kamera-Kontroll-LoRA) und Comfy-Org für den LTX-Text-Encoder für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- RunningHub/RunningHub Workflow-Referenz
- Docs / Release Notes: runninghub.ai post
- Lightricks/LTX 2.3 Model Source
- Hugging Face: Lightricks/LTX-2.3-fp8
- Lightricks/LTX 2.3 Spatial Upscaler Source
- Hugging Face: Lightricks/LTX-2.3
- Lightricks/LTX Kamera-Kontroll-LoRA Source
- Hugging Face: Lightricks/LTX-2-19b-LoRA-Camera-Control-Dolly-Left
- Comfy-Org/LTX Text-Encoder Source
- Hugging Face: Comfy-Org/ltx-2
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen, die von ihren Autoren und Betreuern bereitgestellt werden.
