
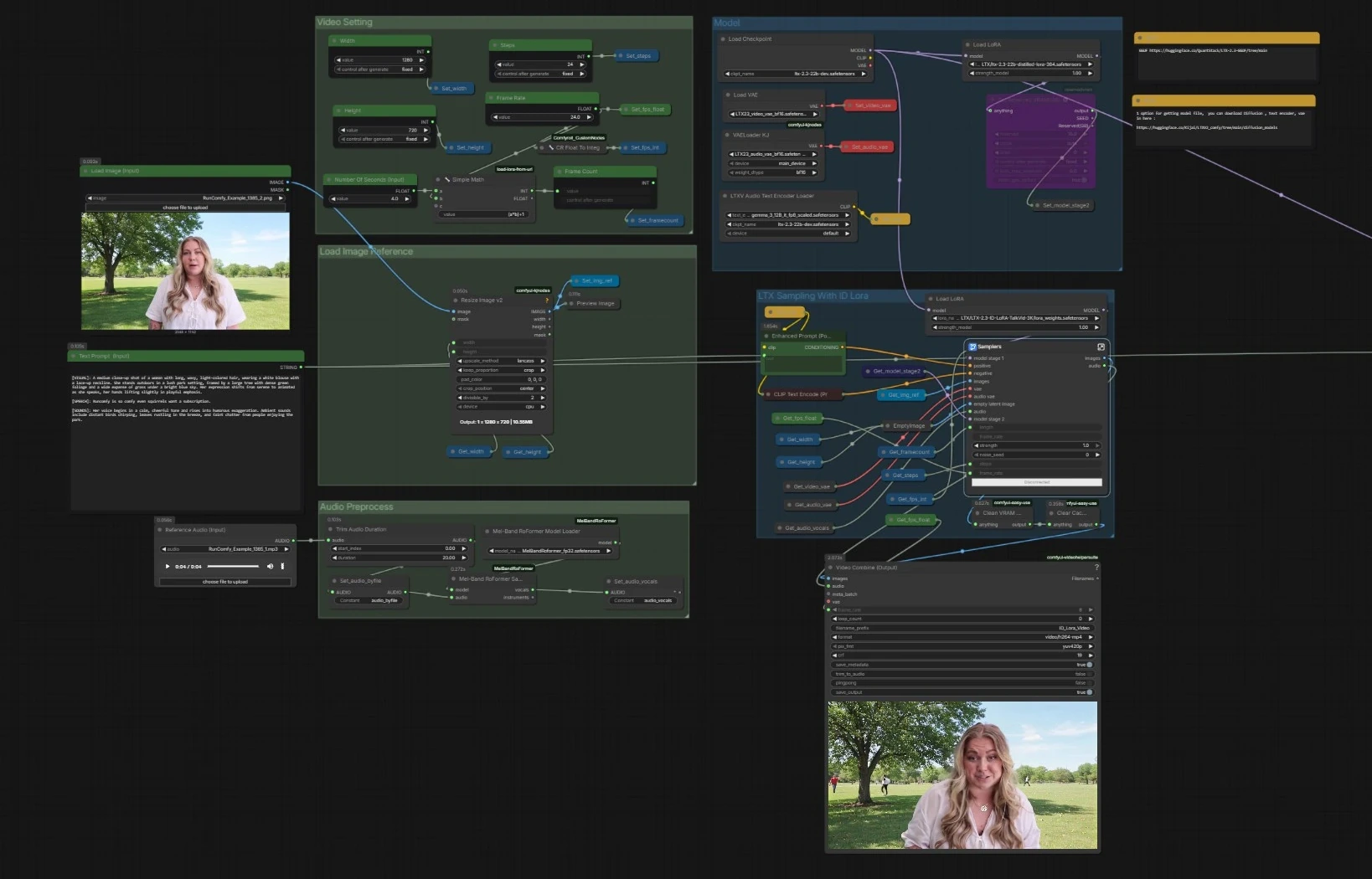
LTX 2.3 ID-LoRA Sprechvideo-Workflow für ComfyUI#
Dieser Workflow verwandelt ein einzelnes Gesichtsbild, einen kurzen Sprachclip und eine Eingabeaufforderung in ein vollständig synchronisiertes Sprechvideo. Basierend auf LTX-2.3, verschmilzt es Audio und Visuals in einem Diffusionsprozess und fügt einen In-Context LoRA Identitätsadapter hinzu, sodass die Person in Ihrem Referenzbild in allen Frames konsistent bleibt. LTX 2.3 ID-LoRA ist ideal für Avatare, virtuelle Moderatoren und jedes Szenario, in dem Lippen-Synchronisation, Ähnlichkeit und Steuerung der Eingabeaufforderung in einem Durchgang übereinstimmen müssen.
Sie liefern drei Dinge: ein Referenzbild, ein oder zwei Sätze Audio und eine Texteingabeaufforderung, die Aussehen und Leistung beschreibt. Der LTX 2.3 ID-LoRA Pfad verwaltet die Identität, während ein leichter Audioprozessor die Sprachklarheit für stärkere Mundbewegungen verbessert. Das Ergebnis ist ein kohärentes, identitätsbewahrendes Video mit synchronisierter Sprache, das kein subjektbasiertes Training erfordert.
Wichtige Modelle im ComfyUI LTX 2.3 ID-LoRA Workflow#
- Lightricks LTX-2.3 22B Basis-Checkpoint. Das gemeinsame Audio-Video-Grundlagenmodell, das synchronisierte Frames und Ton aus Text-, Bild- und Audiobedingungen generiert. Es ist der Kern-Generator, der von dieser ComfyUI-Pipeline verwendet wird. Model card
- LTX-2.3 destillierte LoRA 384. Offizieller LoRA-Adapter, der destillierte Anleitung auf das Basismodell anwendet, um die Abtastung zu stabilisieren und zu beschleunigen, ohne die Qualität zu beeinträchtigen. Es wird als zweites Bühnenmodell in diesem Workflow eingesteckt. Siehe die Checkpoint-Tabelle auf der LTX-2.3-Seite. Model card
- LTX-2.3 räumlicher Upscaler x2. Latent-Raum-Upscaler, der im Sampler-Untergraph verwendet wird, um räumliche Details vor der Dekodierung zu verbessern und die Gesichts- und Kantentreue im endgültigen Video zu verbessern. Model card
- Gemma 3 12B Instruct Text-Encoder für LTX-2.3. Bietet die Textkonditionierung, die Stil, Szene und Leistung antreibt. Dieser Workflow verwendet den Gemma 3 Encoder, der für LTX-2 in ComfyUI verpackt ist. Comfy-Org text encoders
- LTX-2.3 VAEs für Video und Audio. Speziell entwickelte VAEs dekodieren visuelle und akustische Latente, die vom Modell in Bilder und eine Wellenform umgewandelt werden. Kompatible bf16-Builds sind im Graphen referenziert. Beispielquellen: Video VAE · Audio VAE
- Mel-Band RoFormer für Stimmtrennung. Optionaler Vorprozessor, der saubere Vocals aus dem Referenzaudio extrahiert, sodass das Modell Silben und Mundformen zuverlässiger verfolgen kann. Paper · ComfyUI node
- LTX 2.3 ID-LoRA (IC-LoRA). Ein In-Context Identitäts-LoRA, das für Sprechvideo-Anwendungen trainiert wurde und den Generator auf das Gesicht in Ihrem Referenzbild ausrichtet, während Eingabeaufforderungen und Stimmhinweise respektiert werden. Lightricks dokumentiert die Verwendung von LoRA und IC-LoRA mit LTX-2.3 auf der Modellseite. Model card
So verwenden Sie den ComfyUI LTX 2.3 ID-LoRA Workflow#
Gesamtfluss. Die Pipeline lädt die LTX-2.3-Basis mit Text-Encodern und VAEs, bereitet Ihr Bild und Audio vor und führt dann einen zweistufigen LTX-Sampler aus, der Text, die Gesichtsreferenz und eine Sprachspur kombiniert, um synchronisierte Frames und Sprache zu erzeugen. Ein paralleler Sampler ohne ID-LoRA ist für schnelle Vergleiche enthalten. Endgültige Frames und Audio werden in ein MP4 gemultiplext.
- Modell
- Der Graph lädt den Basis-Checkpoint mit
CheckpointLoaderSimple(#5493), die Gemma-basierten Text-Encoder überLTXAVTextEncoderLoader(#5494) und die dedizierten VAEs für VideoVAELoader(#5651) und AudioVAELoaderKJ(#5649). Anschließend werden zwei Adapter angewendet: der offizielle destillierte LoRA, um ein Stage-2-Modell zu bilden, und der LTX 2.3 ID-LoRA für Identitätskonditionierung durchLoraLoaderModelOnly(#5573). - Diese Stufe stellt sicher, dass der Generator Ihre Eingabeaufforderung versteht, die richtigen Dekodierungsstapel hat und sowohl mit Effizienzführung als auch mit Identitätsneigung vorbereitet ist.
- Sie ändern hier in der Regel nichts, außer Checkpoints oder LoRAs auszutauschen, wenn Sie Alternativen haben.
- Der Graph lädt den Basis-Checkpoint mit
- Videoeinstellung
- Steuert Ausgabedimensionen, Bildrate, Schritte und Länge.
Width(#5284),Height(#5286) undFrame Rate(#5289) speisen ein kleines Dienstprogramm, das die Gesamtanzahl der Frames aus Sekunden berechnet, um die Synchronisation zwischen Audio und Video konsistent zu halten. - Einstellungen werden einmal gespeichert und von allen nachgeschalteten Knoten gelesen, sodass die beiden Sampler und der Multiplexer synchron bleiben.
- Passen Sie diese Werte zuerst an, wenn Sie einen anderen Aspekt, eine andere Glätte oder Dauer wünschen.
- Steuert Ausgabedimensionen, Bildrate, Schritte und Länge.
- Bildreferenz laden
- Stellen Sie ein einzelnes klares Gesichtsbild über
Load Image (Input)(#5525) bereit. Das Bild wird mitImageResizeKJv2(#5280) auf Ihre gewählte Ausgabegröße skaliert. - Dieses vorverarbeitete Bild wird zum Anker für die Identität in der LTX 2.3 ID-LoRA-Stufe und leitet Ähnlichkeit und Bildkomposition.
- Verwenden Sie ein gut beleuchtetes, frontales Foto mit minimaler Bewegungsunschärfe für beste Ergebnisse.
- Stellen Sie ein einzelnes klares Gesichtsbild über
- Audiovorverarbeitung
- Laden Sie einen kurzen WAV oder MP3 mit
Reference Audio (Input)(#5652) hoch. Der Clip wird bei Bedarf gekürzt und dann anMelBandRoFormerSampler(#5473) weitergegeben, um Vocals zu isolieren. - Saubere Vocals helfen dem Modell, Phoneme und Timing für genaue Lippenbewegungen und Sprechrhythmus abzuleiten.
- Wenn Ihr Audio bereits nur Sprache ist, können Sie die Trennung überspringen und es direkt zuführen.
- Laden Sie einen kurzen WAV oder MP3 mit
- LTX-Sampling mit ID-LoRA
- Dies ist der Hauptpfad. Der Sampler-Untergraph (
Samplers(#5278)) mischt Ihre positive Eingabeaufforderung vonEnhanced Prompt (Positive)(#5174), die Negativliste, die Gesichtsreferenz und die Sprachspur durch LTX-2.3s AV-latente Pipeline. LTXVReferenceAudiorichtet Bewegung mit Sprache aus, währendLTXVImgToVideoInplacedas Gesichtsbild als Anker in das latente Video injiziert. Der LTX 2.3 ID-LoRA-Adapter lenkt den Generator auf die Identität Ihres Subjekts.- Die Stufe umfasst einen internen latenten Upscaler, um Details vor der Dekodierung zu verbessern. Es gibt Frames plus einen synchronisierten Audiostream aus.
- Dies ist der Hauptpfad. Der Sampler-Untergraph (
- LTX-Sampling ohne ID-LoRA
- Ein gespiegelter Sampler (
Samplers(#5643)) führt die gleiche Konditionierung ohne den ID-LoRA-Adapter aus. Verwenden Sie dies für A/B-Überprüfungen oder wenn Sie mehr Freiheit fernab von der Referenzidentität wünschen. - Alles andere bleibt identisch, sodass Unterschiede, die Sie bemerken, nur auf die Identitätskonditionierung zurückzuführen sind.
- Dieser Pfad kann für schnelle Entwürfe oder kreative Abweichungen nützlich sein.
- Ein gespiegelter Sampler (
- Videokombination und Ausgabe
- Frames und generiertes Audio werden mit
Video Combine (Output)(#5218) in MP4 gemultiplext. Die Bildrate stammt aus Ihrer globalen Einstellung, sodass Bewegung und Lippen-Synchronisation mit dem Timing des Samplers übereinstimmen. - Der sekundäre
Video Combine(#5645) zeigt den no-ID-LoRA-Zweig an, wenn Sie ihn aktiviert haben, was für Vergleiche nützlich ist. - Der Workflow leert den Cache zwischen den Läufen, um die VRAM-Stabilität bei langen Sitzungen zu erhalten.
- Frames und generiertes Audio werden mit
Wichtige Knoten im ComfyUI LTX 2.3 ID-LoRA Workflow#
LoraLoaderModelOnly(#5573)- Lädt das LTX 2.3 ID-LoRA, das die Gesichtsidentität bewahrt. Verringern Sie das Gewicht, wenn Sie mehr kreative Vielfalt wünschen, oder erhöhen Sie es, um die Ähnlichkeit stärker zu fixieren. Kombinieren Sie es durchdacht mit der Stärke der Eingabeaufforderung, sodass Identität und Stil nicht konkurrieren. Referenz: LTX-2.3 LoRA-Verwendung auf der Modellseite. Model card
LTXVReferenceAudio(#5589)- Wandelt Ihr Referenzaudio in Konditionierung für Silbentiming, Prosodie und Mundformen um. Füttern Sie saubere Sprache für die beste Ausrichtung. Wenn Sie Pumpen oder Offbeat-Artikulation hören, verkürzen oder vereinfachen Sie den Clip, anstatt die Stärke zu erhöhen.
LTXVImgToVideoInplace(#5245, auch später verwendet)- Integriert das Gesichtsbild in den latenten Videostream als räumliche Priorität. Die Bildstärkekontrolle balanciert die Einhaltung des Fotos gegenüber Bewegungsfreiheit. Für starke Identität mit natürlicher Bewegung halten Sie die Bildstärke moderat und lassen Sie die ID-LoRA die Ähnlichkeit tragen.
LTXVConditioning(#5621)- Verpackt Textkonditionierung und Timing-Hinweise für die LTX-Sampler. Stellen Sie sicher, dass seine Bildraten-Eingabe Ihrer Ausgabebildrate entspricht, sodass Bewegungsfelder und Phonem-Timing kohärent bleiben.
VHS_VideoCombine(#5218)- Muxes Frames und Audio zur endgültigen Datei. Wenn Ihr Audio etwas länger als die Frames ist, aktivieren Sie das Trimmen hier, um einen schwarzen Nachlauf zu verhindern. Für Plattformkompatibilität behalten Sie die Standard-H.264-Einstellungen bei, es sei denn, Sie haben einen Grund, diese zu ändern. Knotenreferenz: ComfyUI-VideoHelperSuite
MelBandRoFormerSampler(#5473)- Trennt Vocals von Musik mit einem Mel-Band-Transformer, damit der Generator auf Sprache fixiert ist. Wenn Zischlaute verschwimmen oder Plosive knallen, versuchen Sie ein anderes Modelfile aus derselben Familie oder reduzieren Sie die Eingabelautstärke. Hintergrundlektüre: arXiv
Optionale Extras#
- Für die stabilsten Generierungen mit LTX-2.3 verwenden Sie Breiten und Höhen, die durch 32 teilbar sind, und wählen Sie eine Rahmenanzahl von 8n + 1, wie von Lightricks dokumentiert. Model card
- Halten Sie das Referenzbild konsistent mit Ihrer Eingabeaufforderung. Wenn Sie Außenbeleuchtung beschreiben, aber ein Innenfoto liefern, kann die Identität bestehen bleiben, während Farbe und Schattierung gegen die Eingabeaufforderung kämpfen.
- Geben Sie dem Audio 2 bis 8 Sekunden mit natürlichem Tempo. Überkomprimierte oder hallende Clips verringern die Lippen-Synchronisationsgenauigkeit, selbst nach der Stimmtrennung.
- Wenn Gesichter abdriften, verringern Sie leicht die Bildstärke und verlassen Sie sich mehr auf die LTX 2.3 ID-LoRA. Wenn Gesichter zu sehr wandern, tun Sie das Gegenteil.
- Für längere Takes generieren Sie in Segmenten, die denselben Seed und globale Einstellungen teilen, und fügen Sie Clips bei Bedarf in der Videobearbeitung zusammen.
Referenzen und nützliche Repos#
- LTX-2.3 offene Gewichte und Notizen: Hugging Face model page
- Offizielle ComfyUI-Knoten für LTX-Video: Lightricks/ComfyUI-LTXVideo
- LTX-2 Codebase und Papier: Lightricks/LTX-Video · arXiv
- Gemma 3 12B IT-Encoder für LTX in ComfyUI: Comfy-Org/ltx-2 text_encoders
- Mel-Band RoFormer Hintergrund: arXiv
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken den Erstellern der LTX 2.3 ID-LoRA Source für den LTX 2.3 ID-LoRA Source-Workflow für ihre Beiträge und die Wartung. Für autoritative Details beziehen Sie sich bitte auf die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- LTX 2.3 ID-LoRA Source
- Docs / Release Notes: YouTube @Benji’s AI Playground
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Betreuer.
