
LTX 2.3 Dual Character Lip Sync LoRA: Zwei-Charakter-Lippensynchronisationsvideo aus einem Bild und einer Audiospur#
Dieser ComfyUI-Workflow verwandelt ein einzelnes Standbild und ein aufgezeichnetes Gespräch mit zwei Sprechern in ein kohärentes, identitätsstabiles Video mit synchronisierter Sprache für beide auf dem Bildschirm sichtbaren Charaktere. Basierend auf dem LTX‑2.3-Videorückgrat und dem LTX 2.3 Dual Character Lip Sync LoRA, werden Phoneme und Timing aus Ihrem Dialog auf jedes Gesicht abgebildet, während Ausdrücke, Blick und Szenenkonsistenz über die Frames hinweg erhalten bleiben.
Entwickelt für Interviews, filmische Dialoge, Podcasts mit Video-Hosts und virtuelle Charakterinteraktionen, kombiniert der Workflow Text-Prompting für den Szenenaufbau mit audiogesteuerter Bewegung. Es beinhaltet eine Bild-Bootstrap-Phase für die schnelle Entwicklung von Looks, eine zweistufige LTX-Sampling für zeitliche Stabilität und einen latenten Upscaler für scharfe Ergebnisse. Das endgültige Ergebnis ist ein MP4 mit eingebettetem Audio.
Wichtige Modelle im ComfyUI LTX 2.3 Dual Character Lip Sync LoRA Workflow#
- LTX‑2.3 Videogenerationsmodell. Bietet das multimodale Diffusionsrückgrat, das zeitlich konsistente Videos basierend auf Text, Bild und Audio synthetisiert. Lightricks/LTX-2.3
- LTX‑2.3 Video VAE und Audio VAE. Kodieren und dekodieren Video- und Audiolatenten, die vom Modell verwendet werden, um die Generierung effizient und synchron zu halten. Mit der LTX‑2.3-Veröffentlichung geliefert. Lightricks/LTX-2.3
- LTX räumlicher latenter Upscaler. Verfeinert Details nach dem Basisdurchlauf durch Upsampling im latenten Raum für sauberere Texturen und Kanten. Varianten sind zusammen mit LTX-Assets verfügbar. Lightricks/LTX-2
- LTX 2.3 Dual Character Lip Sync LoRA. Integriert Training, das die Mundbewegung und das Timing pro Sprecher für zwei Gesichter im gleichen Bild fördert, während die Gesichtserkennung erhalten bleibt.
- Z‑Image Turbo Text-zu-Bild-Modell. Produziert schnell ein qualitativ hochwertiges Referenzbild, das Identität, Rahmung und Beleuchtung vor der Videosynthese verankert. Comfy‑Org/z_image_turbo
Verwandte Node-Packs, die von diesem Workflow verwendet werden: ComfyUI‑KJNodes, ComfyUI‑VideoHelperSuite, rgthree‑comfy, und ComfyUI‑PromptRelay.
So verwenden Sie den Comfyui LTX 2.3 Dual Character Lip Sync LoRA Workflow#
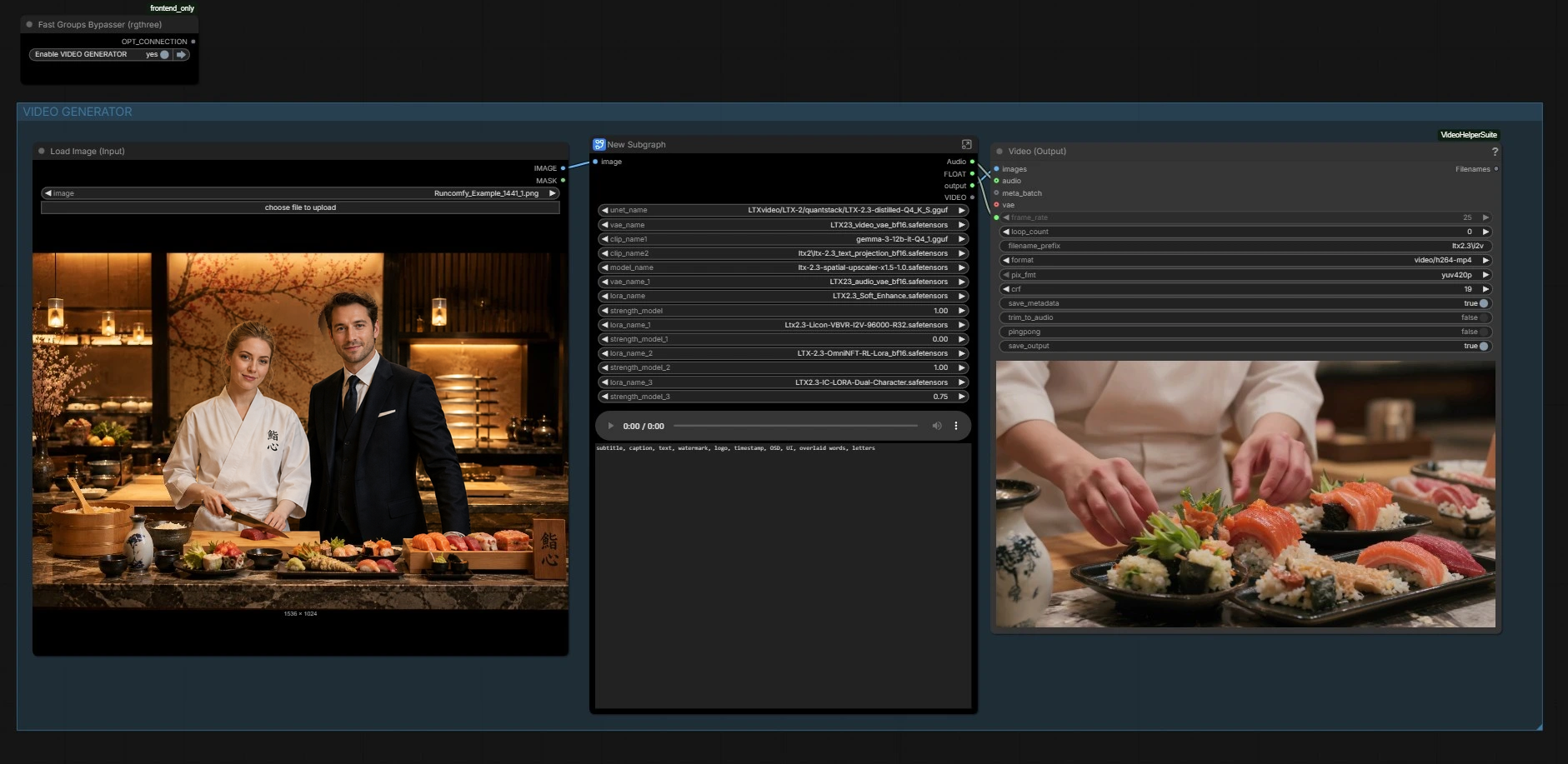
Der Workflow hat zwei koordinierte Teile: einen Bildgenerator, der das Hauptbild erstellt, und einen Videogenerator, der Bewegung und Lippen-Synchronisation aus Audio steuert und dabei den Look beibehält. Verwenden Sie die untenstehenden Gruppen als Leitfaden.
BILDGENERATOR#
Dieser Abschnitt erstellt das Ankerbild. Verwenden Sie die Szenen-Voreinstellungen in der Prompt-Liste, um schnell Kompositionen zu entwerfen, und verfeinern Sie dann den Text mit Charakterbeschreibungen für beide Personen. Ein kompakter Bilddiffusionsstapel ("Z IMG TURBO"-Subgraph) kodiert Ihren Prompt und sampelt ein sauberes Referenzbild. Das Bild wird dekodiert und zur Inspektion gespeichert und dann weitergeleitet, um Identität und Layout für das Video zu verankern.
Wichtige Eingaben, die Sie hier berühren: der beschreibende Prompt für Szene, Garderobe und zwei unterschiedliche Charaktere; vermeiden Sie Linsen- oder Rendering-Jargon, der dem Realismus widerspricht, es sei denn, dieser Look ist beabsichtigt.
Modelle#
Hier lädt der Graph das LTX‑2.3-Rückgrat, seine Video- und Audio-VAEs, die Text-Encoder und den latenten Upscaler. Es wird auch das LTX 2.3 Dual Character Lip Sync LoRA angewendet, plus optionale Stil- oder Verbesserungs-LoRAs, wenn Sie sie aktivieren. Hier werden die Fähigkeiten des Basismodells mit dem Zwei-Sprecher-Lippensynchronisationsverhalten des LoRA kombiniert, um Mundbewegungen zu steuern, ohne die Identität zu opfern. Es ist keine Aktion erforderlich, es sei denn, Sie möchten Gewichte austauschen oder den LoRA-Einfluss anpassen.
BENUTZERDEFINIERTES AUDIO#
Laden Sie hier Ihre Gesprächsspur hoch. Die Audiodatei wird geladen und in ein Audio-Latent umgewandelt, das Timing- und phonetische Hinweise durch die Pipeline trägt. Wenn Sie kein Audio bereitstellen, kann der Workflow Bewegung mit einem leeren Audio-Latent erzeugen, aber das LTX 2.3 Dual Character Lip Sync LoRA ist darauf ausgelegt, mit echtem Dialog zu glänzen. Verwenden Sie einen sauberen Mix mit klaren Sprecherwechseln für die beste Trennung der Mundbewegungen.
Video-PARAMETER#
Stellen Sie die gewünschte Dauer und Bildrate ein. Diese Werte werden gespeichert und während des Samplings, der Planung, der Zuschneidehilfen und der endgültigen Wiedergabe wiederverwendet, sodass Lippen, Blinzeln und Aufnahmetiming übereinstimmen. Halten Sie Ihre Videolänge konsistent mit dem bereitgestellten Audio, um zusätzliche Vorspannung oder Nachlauf zu vermeiden.
LATENTE GENERIERUNG#
Ihr ausgewähltes Standbild wird vorverarbeitet und seine Abmessungen werden erkannt. Der Workflow erstellt ein Video-Latent der richtigen Länge und fügt das Standbild ein, sodass der erste Frame Ihrem Design entspricht. Eine Vollbild-Rauschmaske wird angewendet, um zu steuern, wie stark sich der Hintergrund im Vergleich zu den Gesichtern entwickeln kann. Das vorbereitete Audio-Latent wird dann mit dem Video-Latent gepaart, sodass beide Modalitäten bereit für die Konditionierung sind.
Bemerkenswerte Knoten: LTXVPreprocess skaliert Ihr Standbild für LTX, EmptyLTXVLatentVideo erstellt die Zeitleiste, und LTXVImgToVideoInplaceKJ (#5881) sperrt die Identität, indem es den ersten Frame vom Standbild ausgehend setzt.
Konditionierung#
Text-Prompts werden kodiert und als positive und negative Bedingungen angehängt. Verwenden Sie das globale Prompt-Feld, um in natürlicher Sprache Bühnenaufbau und Absicht zu beschreiben; Sie können eine kurze Shot-Liste einfügen, wenn dies hilfreich ist. Ein dedizierter negativer Text-Encoder unterdrückt Untertitel, Wasserzeichen und UI auf dem Frame, sodass die Gesichter sauber bleiben. Zuschneidehilfen analysieren das Latent, um die Aufmerksamkeit auf beide Gesichter zu lenken, was die Ausdrucksverfolgung pro Sprecher mit dem aktiven LTX 2.3 Dual Character Lip Sync LoRA verbessert.
Repräsentative Komponenten: PromptRelayEncode (#5903) verbindet Ihre Szenenbeschreibung mit dem latenten Kontext, und LTXVConditioning fügt bildratenbewusste Führung für beide Modalitäten hinzu.
1. Sampling#
Der erste Entrauschungsschritt erzeugt ein zeitlich kohärentes Basisvideo mit blockierten Lippenbewegungen. Ein leichter Scheduler und ein Sampler-Paar werden automatisch ausgewählt, wobei Parameter aus den gespeicherten Zeitwerten geroutet werden. Die Modellvariante aus LTX2_NAG fügt rauschbewusste Führung für Video- und Audiobedingungen hinzu, sodass die Sprachzeitung verankert bleibt, während sich der Inhalt formt.
Kern-Sampler-Pfad: SamplerCustom (#5891) mit KSamplerSelect und einem einfachen Scheduler; passen Sie nur an, wenn Sie spezielle Sampler-Präferenzen haben.
Stufe #2 Upscale und Verfeinerung#
Die zweite Stufe verbessert Schärfe und Mikroausdrücke. Der latente Upscaler erhöht die räumlichen Details, Audio- und Video-Latenten werden wieder zusammengeführt, und ein Verfeinerungssampler nimmt subtile Korrekturen vor, während die etablierte Bewegung erhalten bleibt. Danach werden die Latenten getrennt und zurück in eine Bildsequenz und eine Audiowelle dekodiert.
Wichtige Blöcke: LTXVLatentUpsampler (#5927) für Klarheit, SamplerCustomAdvanced (#5929) für den Verfeinerungsschritt, gefolgt von VAEDecode und LTXVAudioVAEDecode, um in den Pixel- und Audioraum zurückzukehren.
Ausgabe#
Schließlich werden Frames und Audio in ein MP4 zur Wiedergabe und Überprüfung gepackt. Die für die Konditionierung verwendete Bildrate wird hier wiederverwendet, sodass der visuelle Rhythmus und die Phonemzeitung mit dem übereinstimmen, was das Modell während der Generierung sah. Sie können auch Audio in der Mitte des Graphen vorhören, wenn Sie eine schnelle Überprüfung benötigen.
Ausgabepfad: CreateVideo (#5931) erstellt den Clip; ein zusätzlicher VHS_VideoCombine (#5905) Pfad wird für alternative Exporte mit Metadatensteuerungen bereitgestellt.
Wichtige Knoten im Comfyui LTX 2.3 Dual Character Lip Sync LoRA Workflow#
LTXICLoRALoaderModelOnly(#5958) Lädt das LTX 2.3 Dual Character Lip Sync LoRA in das LTX‑2.3-Rückgrat. Erhöhen Siestrength_model, wenn Sie engere Mundartikulation und Sprechertrennung benötigen; verringern Sie es, wenn Sie möchten, dass die Bewegung und der Stil des Basismodells dominieren, insbesondere wenn Sie zusätzliche Stil-LoRAs stapeln.PromptRelayEncode(#5903) Zentraler Ort, um die Szenenbeschreibung und optional einen kurzen Shot-Plan zu schreiben. Es verbindet den globalen Prompt mit dem Modellkontext und dem aktuellen Latent, sodass die Führung über die Zeitleiste hinweg konsistent bleibt. Halten Sie die Sprache klar und beschreiben Sie beide Charaktere deutlich, um Identität und Rollentrennung zu unterstützen.LTXVImgToVideoInplaceKJ(#5881) Setzt den ersten Frame des Video-Latents direkt aus Ihrem generierten oder geladenen Standbild. Dies fixiert Identität, Garderobe und Beleuchtung und reduziert Drift über die Zeit. Verwenden Sie eine mittlere oder mittelweite Zweieraufnahme mit beiden Gesichtern unbehindert für beste Ergebnisse.LTXVAudioVAEEncode(#5851) Konvertiert die bereitgestellte Sprachspur in ein Audio-Latent, das das Modell für die Phonemzeitung verwenden kann. Füttern Sie einen sauberen Mix ohne starke Kompression; stellen Sie sicher, dass die Startzeit mit der ersten auf dem Bildschirm sichtbaren Sprache übereinstimmt, um versetzte Lippenbewegungen zu vermeiden.SamplerCustom(#5891) undSamplerCustomAdvanced(#5929) Zwei komplementäre Entrauschungsstufen. Halten Sie die Sampler-Familien zwischen den Stufen konsistent, um Bewegungskontinuität zu gewährleisten, und vermeiden Sie drastische Änderungen in der Rauschplanung, sobald Sie einen Look haben, der Ihnen gefällt.LTXVLatentUpsampler(#5927) Wendet den LTX latenten Upscaler vor der Verfeinerung an, um Klarheit hinzuzufügen, ohne die etablierte Bewegung zu destabilisieren. Wählen Sie eine Upscaler-Variante, die für Ihre Zielauflösung und Texturrealismus geeignet ist.
Optionale Extras#
- Verwenden Sie ein Zwei-Sprecher-WAV mit 24 kHz und minimalem Hintergrundrauschen; fügen Sie kurze natürliche Pausen zwischen den Zeilen hinzu, um dem LTX 2.3 Dual Character Lip Sync LoRA zu helfen, Wechsel zu trennen.
- Erstellen oder liefern Sie ein Standbild, in dem beide Subjekte sichtbar sind, allgemein zur Kamera hin ausgerichtet, mit gleichmäßiger Beleuchtung über die Gesichter hinweg.
- Halten Sie den negativen Text-Prompt, der "Untertitel, Untertitel, Logo, Zeitstempel" ausschließt, um eingebrannte UI-Elemente während des Samplings zu vermeiden.
- Beginnen Sie mit einem kurzen Clip, um das Timing zu validieren, und verlängern Sie dann die Dauer oder erhöhen Sie die Auflösung, sobald Ihnen das Verhalten gefällt.
- Wenn Sie Stil-LoRAs hinzufügen, balancieren Sie sie gegen das LTX 2.3 Dual Character Lip Sync LoRA, damit die Artikulation genau bleibt, während die Szene Ihre gewählte Ästhetik beibehält.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir bedanken uns herzlich bei den Erstellern der "LTX 2.3 Dual Character Lip Sync LoRA Workflow Source" für den Workflow. Für autoritative Details verweisen wir auf die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- LTX 2.3 Dual Character Lip Sync LoRA Workflow Source/LTX 2.3 Dual Character Lip Sync LoRA Workflow Source
- Docs / Release Notes: YouTube video
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und des Codes unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Betreuer.