
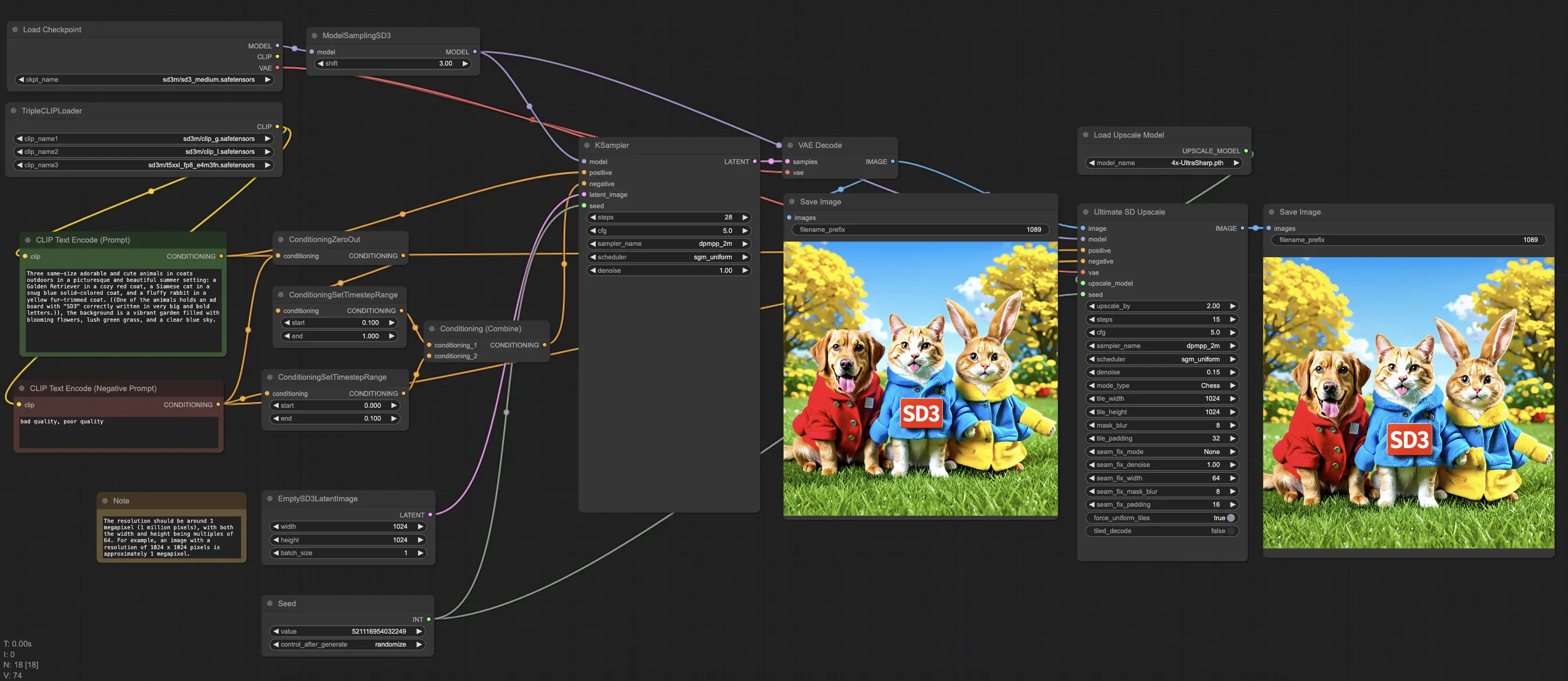



1. Steigerung Ihres kreativen Prozesses mit ComfyUI Stable Diffusion 3#
🌟🌟🌟Das Stable Diffusion 3 Medium-Modell und seine zugehörigen Knoten sind jetzt in der RunComfy‘s ComfyUI Beta-Version (Version 24.06.13.0) vorinstalliert!!!🌟🌟🌟 Sie können das Stable Diffusion 3 Medium entweder direkt in diesem ComfyUI-Workflow verwenden oder nahtlos in Ihre bestehenden ComfyUI-Workflows integrieren.
Der ComfyUI Stable Diffusion 3 Workflow enthält alle notwendigen Stable Diffusion 3 Medium-Modelle. Experimentieren Sie einfach mit verschiedenen Eingabeaufforderungen oder Parametern, um es zu erleben!
1.1. Stable Diffusion 3 Medium-Modelle vorinstalliert in ComfyUI#
sd3_medium.safetensors: Enthält die MMDiT- und VAE-Gewichte, jedoch keine Text-Encoder.sd3_medium_incl_clips_t5xxlfp16.safetensors: Enthält alle notwendigen Gewichte, einschließlich der fp16-Version des T5XXL-Text-Encoders.sd3_medium_incl_clips_t5xxlfp8.safetensors: Enthält alle notwendigen Gewichte, einschließlich der fp8-Version des T5XXL-Text-Encoders, und bietet ein Gleichgewicht zwischen Qualität und Ressourcenanforderungen.sd3_medium_incl_clips.safetensors: Enthält alle notwendigen Gewichte außer dem T5XXL-Text-Encoder. Diese Version erfordert minimale Ressourcen, aber die Leistung des Modells wird ohne den T5XXL-Text-Encoder anders sein.- Der
text_encodersOrdner enthält drei Text-Encoder und ihre Original-Modelldatei-Links zur Benutzerfreundlichkeit. Alle Komponenten in diesem Ordner (und deren Äquivalente in anderen Paketen) unterliegen ihren jeweiligen Original-Lizenzen.
1.2 Gesamtqualität und Fotorealismus von Stable Diffusion 3 Medium#
Stable Diffusion 3 Medium setzt einen neuen Standard für Bildqualität in der KI-Kunst-Community. Dieses Modell liefert Bilder mit außergewöhnlichen Details, Farbgenauigkeit und realistischer Beleuchtung. Hier ist, was Sie erwarten können:
- Detail & Auflösung: Verbesserte Fähigkeit, komplizierte Details darzustellen, was es perfekt für Nahaufnahmen und komplexe Kompositionen macht.
- Farbe & Beleuchtung: Verbesserte Algorithmen sorgen dafür, dass Farben lebendig und naturgetreu sind, mit dynamischen Lichteffekten, die Tiefe und Realismus zu Ihren Bildern hinzufügen.
- Realismus bei Gesichtern und Händen: Häufige Fallstricke wie verzerrte Hände und Gesichter werden dank Innovationen wie dem 16-Kanal-Variational Autoencoder (VAE) erheblich reduziert.
1.3 Verständnis der Eingabeaufforderungen von Stable Diffusion 3 Medium#
Eine der herausragenden Eigenschaften von SD3 Medium ist sein ausgeklügeltes Verständnis von Eingabeaufforderungen. Dieses Modell kann lange und komplexe Eingabeaufforderungen interpretieren, die räumliches Denken, kompositorische Elemente, Aktionen und Stile umfassen. Hier sind einige Highlights:
- Text-Encoder: Nutzt drei Text-Encoder, um Leistung und Effizienz auszugleichen. Dies ermöglicht ein nuanciertes Verständnis und die Ausführung detaillierter Eingabeaufforderungen.
- Kompositorisches Bewusstsein: In der Lage, räumliche Beziehungen zu bewahren und Szenen genau so darzustellen, wie sie beschrieben werden, was es ideal für das Geschichtenerzählen durch visuelle Darstellungen macht.
1.4 Typografie von Stable Diffusion 3 Medium#
Typografie war schon immer eine Herausforderung bei der Text-zu-Bild-Generierung. SD3 Medium meistert dies mit bemerkenswertem Erfolg:
- Textqualität: Erreicht beispiellose Genauigkeit bei Rechtschreibung, Kerning, Buchstabenbildung und Abstand.
- Diffusion Transformer Architektur: Diese fortschrittliche Architektur ermöglicht eine präzisere Darstellung von Text innerhalb von Bildern, reduziert Fehler und verbessert die visuelle Kohärenz.
1.5 Ressourceneffizienz von Stable Diffusion 3 Medium#
Trotz seiner fortschrittlichen Fähigkeiten ist SD3 Medium ressourceneffizient gestaltet:
- Niedriger VRAM-Footprint: Kann auf Standard-Consumer-GPUs ohne Leistungseinbußen laufen, wodurch qualitativ hochwertige KI-Kunst einem breiteren Publikum zugänglich wird.
- Optimiert für Effizienz: Balanciert die Anforderungen an die Rechenleistung mit der Ausgabequalität, um einen reibungslosen Betrieb auch auf weniger leistungsstarker Hardware zu gewährleisten.
1.6 Feinabstimmung von Stable Diffusion 3 Medium#
Anpassung ist ein kritischer Aspekt für KI-Künstler, und SD3 Medium glänzt in diesem Bereich:
- Aufnahme nuancierter Details: In der Lage, mit kleinen Datensätzen feinabgestimmt zu werden, sodass Künstler ihren einzigartigen Stil einprägen oder spezifische Projektanforderungen erfüllen können.
- Vielseitigkeit: Ob Sie an bestimmten Themen, Stilen oder komplizierten Details arbeiten, SD3 Medium bietet die Flexibilität, die für personalisierte Kunstwerke erforderlich ist.
2. Was ist Stable Diffusion 3#
Stable Diffusion 3 ist ein hochmodernes KI-Modell, das speziell für die Generierung von Bildern aus Eingabeaufforderungen entwickelt wurde. Es stellt die dritte Iteration in der Stable Diffusion-Serie dar und zielt darauf ab, verbesserte Genauigkeit, bessere Einhaltung der Nuancen von Eingabeaufforderungen und überlegene visuelle Ästhetik im Vergleich zu früheren Versionen und anderen Modellen wie DALL·E 3, Midjourney v6 und Ideogram v1 zu liefern.
3. Stable Diffusion 3 Modelle#
Stable Diffusion 3 bietet drei verschiedene Modelle, die jeweils auf unterschiedliche Bedürfnisse und Rechenkapazitäten ausgelegt sind:
3.1. Stable Diffusion 3 Medium#
🌟🌟🌟 Direkt in diesen Workflow integriert 🌟🌟🌟
- Parameter: 2 Milliarden
- Hauptmerkmale:
- Hochwertige, fotorealistische Bilder
- Fortgeschrittenes Verständnis komplexer Eingabeaufforderungen
- Überlegene Typografiefähigkeiten
- Ressourceneffizient, geeignet für Consumer-GPUs
- Hervorragend für die Feinabstimmung mit kleinen Datensätzen
3.2. Stable Diffusion 3 Large#
Verfügbar über Stability AI Developer Platform API
- Parameter: 8 Milliarden
- Hauptmerkmale:
- Verbesserte Bildqualität und Detailgenauigkeit
- Größere Kapazität für die Handhabung komplexer Eingabeaufforderungen und Stile
- Ideal für professionelle Projekte, die hohe Auflösung und Treue erfordern
3.3. Stable Diffusion 3 Large Turbo#
Verfügbar über Stability AI Developer Platform API
- Parameter: 8 Milliarden (mit optimierter Inferenzzeit)
- Hauptmerkmale:
- Die gleiche hohe Leistung wie SD3 Large
- Schnellere Inferenz, was es für Echtzeitanwendungen und schnelles Prototyping geeignet macht
4. Technische Architektur von Stable Diffusion 3#
Im Kern von Stable Diffusion 3 liegt die Multimodal Diffusion Transformer (MMDiT) Architektur. Dieses innovative Framework verbessert die Art und Weise, wie das Modell textuelle und visuelle Informationen verarbeitet und integriert. Im Gegensatz zu seinen Vorgängern, die ein einziges Set neuronaler Netzwerkgewichte für die Verarbeitung von Bild- und Textdaten verwendeten, verwendet Stable Diffusion 3 separate Gewichtungen für jede Modalität. Diese Trennung ermöglicht eine spezialisierte Handhabung von Text- und Bilddaten, was zu einem verbesserten Textverständnis und einer besseren Rechtschreibung in den generierten Bildern führt.
4.1. Komponenten der MMDiT-Architektur#
- Text-Encoder: Stable Diffusion 3 verwendet eine Kombination aus drei Text-Embedding-Modellen, einschließlich zwei CLIP-Modellen und T5, um Text in ein Format zu konvertieren, das die KI verstehen und verarbeiten kann.
- Bild-Encoder: Ein verbessertes Autoencoding-Modell wird verwendet, um Bilder in eine Form zu konvertieren, die für die KI geeignet ist, neue visuelle Inhalte zu manipulieren und zu generieren.
- Dual Transformer Ansatz: Die Architektur verfügt über zwei verschiedene Transformer für Text und Bilder, die unabhängig arbeiten, aber für Aufmerksamkeitsoperationen miteinander verbunden sind. Diese Konfiguration ermöglicht es beiden Modalitäten, sich direkt zu beeinflussen, was die Kohärenz zwischen dem Texteingang und dem Bildausgang verbessert.
5. Was ist neu und verbessert in Stable Diffusion 3?#
- Einhaltung der Eingabeaufforderungen: SD3 zeichnet sich durch die genaue Befolgung der Spezifikationen der Benutzereingabeaufforderungen aus, insbesondere bei komplexen Szenen oder mehreren Subjekten. Diese Präzision beim Verständnis und der Darstellung detaillierter Eingabeaufforderungen ermöglicht es, andere führende Modelle wie DALL·E 3, Midjourney v6 und Ideogram v1 zu übertreffen, was es äußerst zuverlässig für Projekte macht, die eine strikte Einhaltung der gegebenen Anweisungen erfordern.
- Text in Bildern: Mit seiner fortschrittlichen Multimodal Diffusion Transformer (MMDiT) Architektur verbessert SD3 die Klarheit und Lesbarkeit von Text innerhalb von Bildern erheblich. Durch die Verwendung separater Gewichtungen für die Verarbeitung von Bild- und Sprachdaten erreicht das Modell eine überlegene Textverständnis- und Rechtschreibgenauigkeit. Dies ist eine wesentliche Verbesserung gegenüber früheren Versionen von Stable Diffusion und adressiert eine der häufigen Herausforderungen bei Text-zu-Bild-KI-Anwendungen.
- Visuelle Qualität: SD3 übertrifft nicht nur die visuelle Qualität der von seinen Konkurrenten erzeugten Bilder, sondern übertrifft sie in vielen Fällen. Die erzeugten Bilder sind nicht nur ästhetisch ansprechend, sondern behalten auch eine hohe Treue zu den Eingabeaufforderungen bei, dank der verfeinerten Fähigkeit des Modells, textuelle Beschreibungen zu interpretieren und zu visualisieren. Dies macht SD3 zur ersten Wahl für Benutzer, die außergewöhnliche visuelle Ästhetik in ihren generierten Bildern suchen.

Für detaillierte Einblicke in das Modell besuchen Sie bitte Stable Diffusion 3's research paper, Github








