

IDM-VTON, kurz für "Improving Diffusion Models for Authentic Virtual Try-on in the Wild", ist ein innovatives Diffusionsmodell, das es Ihnen ermöglicht, Kleidungsstücke realistisch virtuell anzuprobieren, indem Sie nur wenige Eingaben verwenden. Was IDM-VTON auszeichnet, ist seine Fähigkeit, die einzigartigen Details und die Identität der Kleidungsstücke zu bewahren und gleichzeitig virtuelle Anprobierergebnisse zu erzeugen, die unglaublich authentisch aussehen.
1. Verständnis von IDM-VTON#
Im Kern ist IDM-VTON ein Diffusionsmodell, das speziell für das virtuelle Anprobieren entwickelt wurde. Um es zu verwenden, benötigen Sie lediglich eine Darstellung einer Person und ein Kleidungsstück, das Sie anprobieren möchten. IDM-VTON vollbringt dann seine Magie und erzeugt ein Ergebnis, das aussieht, als würde die Person das Kleidungsstück tatsächlich tragen. Es erreicht ein Maß an Kleidungsgenauigkeit und Authentizität, das frühere diffusionsbasierte virtuelle Anprobiermethoden übertrifft.
2. Die Funktionsweise von IDM-VTON#
Wie gelingt es IDM-VTON, solch realistische virtuelle Anproben zu ermöglichen? Das Geheimnis liegt in seinen zwei Hauptmodulen, die zusammenarbeiten, um die Semantik der Kleidereingabe zu kodieren:
- Das erste ist ein Bildprompt-Adapter, oder kurz IP-Adapter. Diese clevere Komponente extrahiert die hochgradigen Semantiken des Kleidungsstücks - im Wesentlichen die Schlüsselmöglichkeiten, die sein Aussehen definieren. Diese Informationen werden dann in die Cross-Attention-Schicht des Haupt-UNet-Diffusionsmodells integriert.
- Das zweite Modul ist ein paralleles UNet namens GarmentNet. Seine Aufgabe ist es, die niedriggradigen Merkmale des Kleidungsstücks zu kodieren - die kleinen Details, die es einzigartig machen. Diese Merkmale werden dann in die Self-Attention-Schicht des Haupt-UNet integriert.
Aber das ist noch nicht alles! IDM-VTON nutzt auch detaillierte Textprompts für sowohl die Kleidungs- als auch die Personeneingaben. Diese Prompts bieten zusätzlichen Kontext, der die Authentizität des endgültigen virtuellen Anprobierergebnisses verbessert.
3. IDM-VTON in ComfyUI zum Einsatz bringen#
3.1 Der Star der Show: Der IDM-VTON-Knoten#
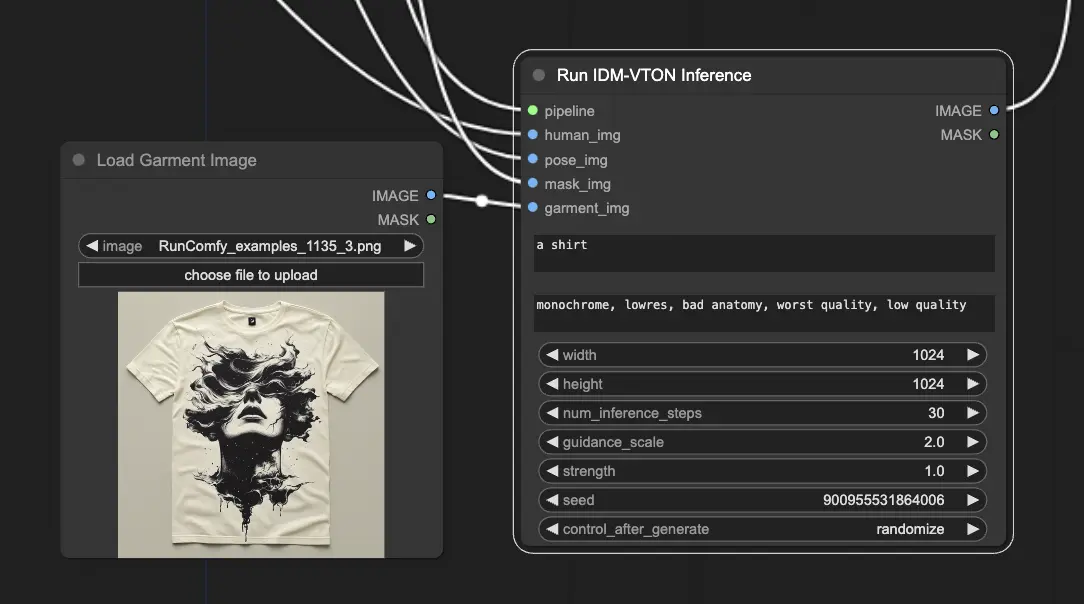
In ComfyUI ist der "IDM-VTON"-Knoten das Kraftpaket, das das IDM-VTON-Diffusionsmodell ausführt und die virtuelle Anprobierausgabe generiert.
Damit der IDM-VTON-Knoten seine Magie entfalten kann, benötigt er einige wichtige Eingaben:
- Pipeline: Dies ist die geladene IDM-VTON-Diffusionspipeline, die den gesamten virtuellen Anprobeprozess antreibt.
- Menschliche Eingabe: Ein Bild der Person, die das Kleidungsstück virtuell anprobieren wird.
- Pose-Eingabe: Eine vorverarbeitete DensePose-Darstellung der menschlichen Eingabe, die IDM-VTON hilft, die Pose und Körperform der Person zu verstehen.
- Masken-Eingabe: Eine binäre Maske, die anzeigt, welche Teile der menschlichen Eingabe Kleidung sind. Diese Maske muss in ein geeignetes Format umgewandelt werden.
- Kleidungs-Eingabe: Ein Bild des Kleidungsstücks, das virtuell anprobiert werden soll.
3.2 Alles vorbereiten#
Um den IDM-VTON-Knoten in Betrieb zu nehmen, gibt es einige Vorbereitungsschritte:
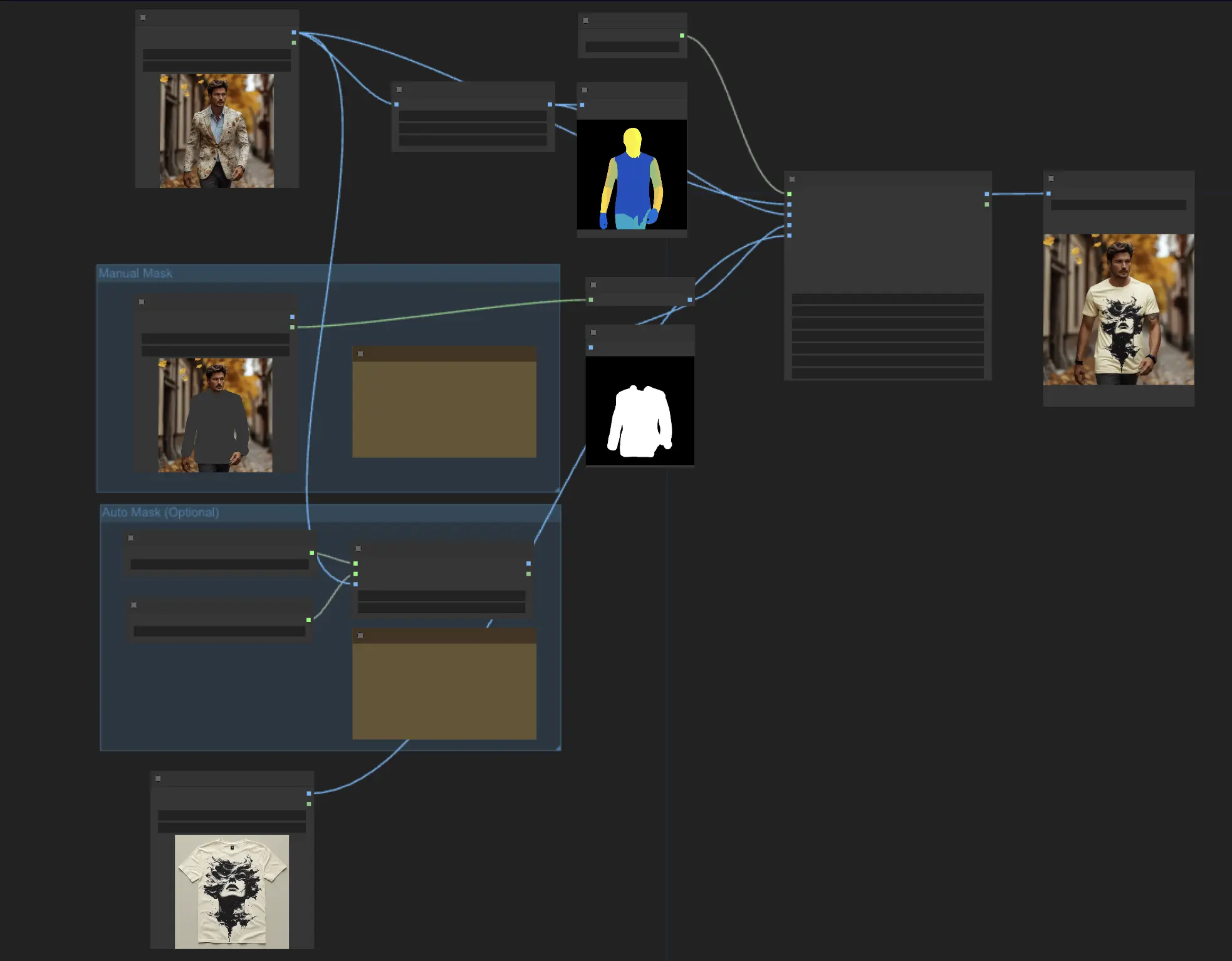
- Laden des menschlichen Bildes: Ein LoadImage-Knoten wird verwendet, um das Bild der Person zu laden. <img src="https://cdn.runcomfy.net/workflow_assets/1135/readme01.webp" alt="IDM-VTON" width="500" />
- Erzeugen des Pose-Bildes: Das menschliche Bild wird durch einen DensePosePreprocessor-Knoten geleitet, der die benötigte DensePose-Darstellung berechnet, die IDM-VTON benötigt. <img src="https://cdn.runcomfy.net/workflow_assets/1135/readme02.webp" alt="IDM-VTON" width="500" />
- Erhalten des Maskenbildes: Es gibt zwei Möglichkeiten, die Kleidungsmaske zu erhalten: <img src="https://cdn.runcomfy.net/workflow_assets/1135/readme03.webp" alt="IDM-VTON" width="500" />
a. Manuelles Maskieren (empfohlen)
- Rechtsklicken Sie auf das geladene menschliche Bild und wählen Sie "In Masken-Editor öffnen."
- Maskieren Sie im Masken-Editor-UI manuell die Kleidungsbereiche.
b. Automatisches Maskieren
- Verwenden Sie einen GroundingDinoSAMSegment-Knoten, um die Kleidung automatisch zu segmentieren.
- Geben Sie dem Knoten eine Textbeschreibung des Kleidungsstücks (wie "T-Shirt").
Unabhängig von der gewählten Methode muss die erhaltene Maske in ein Bild umgewandelt werden, indem ein MaskToImage-Knoten verwendet wird, der dann mit dem "Maskenbild"-Eingang des IDM-VTON-Knotens verbunden wird.
- Laden des Kleidungsbildes: Es wird verwendet, um das Bild des Kleidungsstücks zu laden.
Für einen tieferen Einblick in das IDM-VTON-Modell sollten Sie das Originalpapier "Improving Diffusion Models for Authentic Virtual Try-on in the Wild" nicht verpassen. Und wenn Sie daran interessiert sind, IDM-VTON in ComfyUI zu verwenden, schauen Sie sich die dedizierten Knoten hier an. Ein großer Dank geht an die Forscher und Entwickler hinter diesen unglaublichen Ressourcen.