
Fish Audio S2 TTS für ComfyUI: Hochwertiges TTS, Stimmklonung und Mehrsprecher-Dialog#
Fish Audio S2 TTS ist ein einsatzbereiter ComfyUI-Workflow, der Text in natürliche Sprache umwandelt, eine Stimme aus einem kurzen Referenzclip klont und Mehrsprecher-Konversationen generiert. Er wird von der Fish Audio S2-Pro-Familie angetrieben und unterstützt reichhaltige Stilsteuerung über Emotionen- und Prosodie-Tags wie [excited], [whisper] und [laughing].
Dieser Workflow ist ideal für Kreative, Produktteams und Entwickler, die flexible, ausdrucksstarke Sprachsynthese innerhalb von ComfyUI wünschen. Er umfasst optionales Speech-to-Text für schnelle Transkriptaufnahmen, automatische Spracherkennung und mehrere Präzisionsoptionen, einschließlich fp8 und sage_attention für effiziente Inferenz.
Hinweis: Führen Sie diesen Workflow auf einer 2X Large oder größeren Maschine aus. Kleinere Instanzen könnten den Speicher (OOM) überschreiten.
Wichtige Modelle im ComfyUI Fish Audio S2 TTS-Workflow#
- Fish Audio S2-Pro — das zentrale generative Text-zu-Sprache-Modell für Einzelsprecher-TTS, Stimmklonung und Mehrsprecher-Dialog. Es unterstützt umfangreiche Stil-Token und mehrsprachige Synthese model card und ist Teil des Fish-Speech-Projekts repo.
- Fish Audio S2-Pro FP8 — eine speichereffiziente Variante von S2-Pro, die den VRAM-Bedarf mit minimalen Qualitätsverlusten reduziert, empfohlen für eingeschränkte GPUs model card.
- OpenAI Whisper large-v3 — ein optionales Speech-to-Text-Modell, das zur automatischen Transkription Ihres Referenzaudios beim Erstellen von Stimmklonungsprompts verwendet wird repo.
So verwenden Sie den ComfyUI Fish Audio S2 TTS-Workflow#
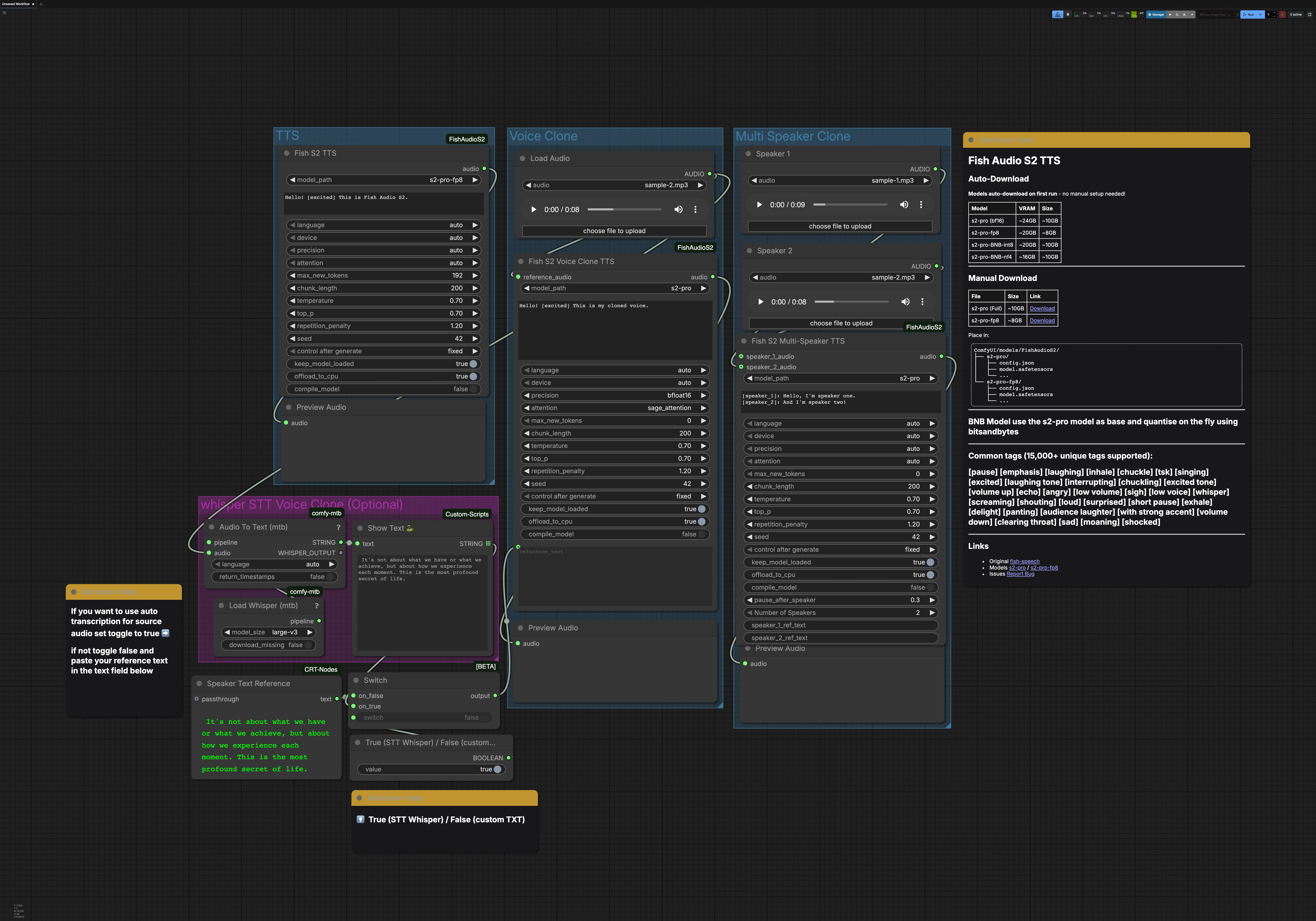
Dieser Workflow enthält drei Hauptpfade, die unabhängig voneinander ausgeführt werden können: TTS, Voice Clone und Multi Speaker Clone. Eine optionale Whisper STT-Gruppe kann das Transkript für die Stimmklonung generieren. Jeder Pfad endet mit einer Audiovorschau, damit Sie die Ergebnisse schnell überwachen können.
TTS-Gruppe#
Der FishS2TTS (#42) Knoten führt direktes Text-zu-Sprache mit Fish Audio S2 TTS aus. Geben Sie Ihr Skript in das Textfeld des Knotens ein und streuen Sie Stil-Tags wie [excited], [pause] oder [whisper], um Emotion und Tempo zu formen. Die Spracherkennung erfolgt automatisch, sodass Sie in der Zielsprache schreiben können und das Modell sich anpasst. Wählen Sie die S2-Pro-Variante, die zu Ihrem GPU-Speicher passt, zum Beispiel fp8 für leichtere Lasten. Die Ausgabe wird an PreviewAudio weitergeleitet, um sofortiges Hören zu ermöglichen.
Voice Clone-Gruppe#
Verwenden Sie LoadAudio, um einen kurzen, sauberen Referenzclip der Zielstimme bereitzustellen, und leiten Sie ihn dann in FishS2VoiceCloneTTS (#14) weiter. Geben Sie das Transkript ein, das dem gewünschten Sprechstil entspricht; genauer Text hilft dem Modell, Rhythmus und Akzent zu bewahren. Sie können den Referenztext aus der STT-Gruppe verwenden oder Ihren eigenen eingeben und Stil-Tags hinzufügen, um Emotion und Ausdruck zu verfeinern. Präzisions- und Aufmerksameits-Backend-Optionen balancieren Geschwindigkeit, Speicher und Stabilität für lange Zeilen. Der synthetisierte Klon wird an PreviewAudio gesendet, damit Sie schnell iterieren können.
Multi Speaker Clone-Gruppe#
Laden Sie einen Referenzclip pro Sprecher mit den LoadAudio-Knoten, und verbinden Sie sie dann mit FishS2MultiSpeakerTTS (#41). Geben Sie ein Dialogskript an, das jede Wendung mit [speaker_1], [speaker_2] usw. kennzeichnet. Diese Vorlage enthält standardmäßig zwei Sprecher, und der Knoten unterstützt die Skalierung auf bis zu acht verschiedene Stimmen, wenn entsprechend konfiguriert. Sie können erzählerische Prosa, Tags und Dialoge mischen, um den Fluss und die Emotion für jeden Charakter zu steuern. Der endgültige Mix wird zur Überprüfung von Timing und Klarheit präsentiert.
Whisper STT für die Stimmklonung (optional)#
Load Whisper (mtb) (#6) mit large-v3 versorgt Audio To Text (mtb) (#7), um einen Referenzclip automatisch zu transkribieren. Der erkannte Text wird von ShowText|pysssss (#8) angezeigt. Ein kleiner Umschalter, der mit ComfySwitchNode (#34) und einer booleschen Steuerung gebaut wurde, lässt Sie zwischen STT-Ausgabe (true) oder Ihrem eigenen eingegebenen Text aus Text Box line spot (#31) (false) wählen. Dies ist nützlich, wenn Sie ein schnelles Baseline-Transkript möchten oder wenn Sie einen präzisen Prompt für die Klonung erstellen.
Wichtige Knoten im ComfyUI Fish Audio S2 TTS-Workflow#
FishS2TTS (#42)#
Erzeugt Einzelsprecher-Sprache aus Text mit optionalen Stil-Tags und automatischer Spracherkennung. Passen Sie die Modellvariante an Ihre Hardware an, indem Sie zum Beispiel fp8 wählen, wenn der VRAM knapp ist. Verwenden Sie die Seed-Steuerung für wiederholbare Takes und führen Sie kleine Änderungen ein, wenn Sie alternative Lieferungen erkunden. Für lange Skripte wählen Sie ein Aufmerksamkeits-Backend, das auf Stabilität optimiert ist.
FishS2VoiceCloneTTS (#14)#
Erstellt eine geklonte Stimme, indem auf reference_audio und reference_text konditioniert wird. Bessere Ergebnisse resultieren aus sauberer Sprache mit konsistentem Ton und einem Transkript, das den beabsichtigten Rhythmus widerspiegelt. Stil-Tags können in den endgültigen Text gemischt werden, um die Stimmung zu lenken, ohne die Identität zu beeinträchtigen. Präzisions- und Aufmerksameits-Einstellungen helfen, Qualität und Speicher für längere Zeilen auszugleichen.
FishS2MultiSpeakerTTS (#41)#
Synthesisiert Mehrsprecher-Konversationen, indem jedes Sprecher-Referenzaudio mit einem Dialog, der durch [speaker_n]-Labels gekennzeichnet ist, gepaart wird. Erhöhen Sie bei Bedarf die Anzahl der Sprecher und weisen Sie unterschiedliche Clips für eine stärkere Trennung zu. Halten Sie die Referenz jedes Sprechers konsistent im Ton, um ein Vermischen zu vermeiden. Verwenden Sie den Seed für deterministisches Mischen beim Rendern von Multi-Take-Szenen.
Optionale Extras#
- Verwenden Sie Stil-Tags durchdacht. Beginnen Sie mit ein paar wie [excited], [whisper], [emphasis], [pause] und bauen Sie nur bei Bedarf für Klarheit auf.
- Beim Klonen von Stimmen schneiden Sie Stille am Anfang und Ende des Referenztons ab und vermeiden Sie Hintergrundgeräusche, um den Klang zu bewahren.
- Wenn der GPU-Speicher begrenzt ist, bevorzugen Sie S2-Pro fp8 oder zur Laufzeit quantisierte Optionen. Für maximale Wiedergabetreue verwenden Sie höhere Präzision.
- Interpunktion ist wichtig. Kommas und Punkte verbessern die Phrasierung, und Tags, die an Satzgrenzen platziert werden, klingen natürlicher.
- Für Mehrsprecher-Skripte halten Sie eine Äußerung pro Zeile und prefixen Sie immer mit dem richtigen [speaker_n]-Label, um die Trennung zu wahren.
Ressourcen:
- Fish Audio S2-Pro Modellkarte: Hugging Face
- S2-Pro fp8 Variante: Hugging Face
- Fish-Speech Projekt: GitHub
- ComfyUI Fish Audio S2 Knoten: GitHub
- Whisper large-v3: GitHub
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken Saganaki22 für ComfyUI-FishAudioS2 Custom Nodes und Fish Audio für das S2-Pro Modell für ihre Beiträge und Wartung. Für autoritative Details verweisen wir auf die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- Saganaki22/ComfyUI-FishAudioS2 Custom Nodes
- GitHub: Saganaki22/ComfyUI-FishAudioS2
- Fish Audio/S2-Pro Model
- Hugging Face: fishaudio/s2-pro
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen ihrer Autoren und Betreiber.

