
InfiniteTalk: lippensynchronisiertes Porträtvideo aus einem einzelnen Bild in ComfyUI#
Dieser ComfyUI InfiniteTalk-Workflow erstellt natürliche, sprachsynchronisierte Porträtvideos aus einem einzigen Referenzbild plus einem Audioclip. Er kombiniert WanVideo 2.1 Bild-zu-Video-Generierung mit dem MultiTalk Talking-Head-Modell, um ausdrucksstarke Lippenbewegungen und stabile Identität zu erzeugen. Wenn Sie kurze Social-Clips, Video-Dubs oder Avatar-Updates benötigen, verwandelt InfiniteTalk ein Standbild in ein flüssiges Sprechvideo in Minuten.
InfiniteTalk baut auf der hervorragenden MultiTalk-Forschung von MeiGen-AI auf. Für Hintergrundinformationen und Zuweisungen siehe das Open-Source-Projekt: MeiGen-AI/MultiTalk.
Wichtige Modelle im ComfyUI InfiniteTalk-Workflow#
- MultiTalk (GGUF, InfiniteTalk-Variante): Steuert phonem-bewusste Gesichtsbewegungen aus Audio, sodass Mund- und Kieferbewegungen die Sprache natürlich verfolgen. Referenz: Kijai/WanVideo_comfy_GGUF › InfiniteTalk und Ursprungsidee: MeiGen-AI/MultiTalk.
- WanVideo 2.1 I2V 14B (GGUF): Der primäre Bild-zu-Video-Generator, der Identität, Beleuchtung und Pose bewahrt, während er die Frames animiert. Empfohlene Gewichte: city96/Wan2.1-I2V-14B-480P-gguf.
- Wan 2.1 VAE (bf16): Dekodiert latente Frames zu RGB mit minimaler Farbverschiebung; bereitgestellt in den oben genannten WanVideo-Paketen.
- UMT5-XXL Text-Encoder: Interpretiert Ihre positiven und negativen Prompts, um Stil, Szene und Bewegungszusammenhang zu beeinflussen. Modellfamilie: google/umt5-xxl.
- CLIP Vision: Extrahiert visuelle Einbettungen aus Ihrem Referenzbild, um Identität und Gesamterscheinung zu sichern.
- Wav2Vec2 (Tencent GameMate): Wandelt rohe Sprache in robuste Audio-Features für MultiTalk-Einbettungen um, verbessert die Synchronisation und Prosodie: TencentGameMate/chinese-wav2vec2-base.
Tipp: Dieses InfiniteTalk-Diagramm ist für GGUF gebaut. Halten Sie die InfiniteTalk MultiTalk-Gewichte und das WanVideo-Rückgrat in GGUF, um Inkompatibilitäten zu vermeiden. Optionale fp8/fp16-Builds sind ebenfalls verfügbar: Kijai/WanVideo_comfy_fp8_scaled und Kijai/WanVideo_comfy.
Wie man den ComfyUI InfiniteTalk-Workflow verwendet#
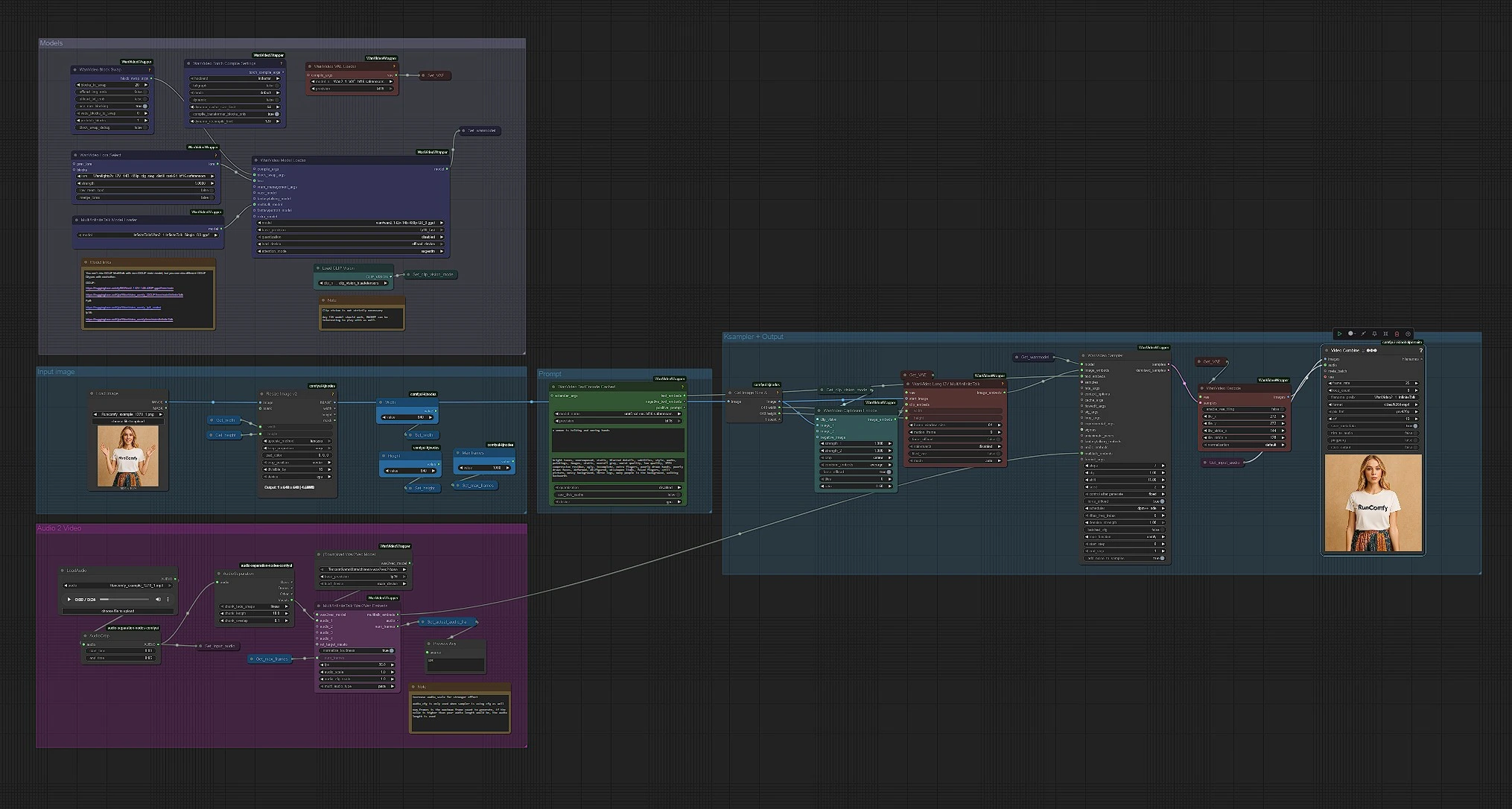
Der Workflow läuft von links nach rechts. Sie stellen drei Dinge bereit: ein sauberes Porträtbild, eine Sprach-Audiodatei und einen kurzen Prompt, um den Stil zu lenken. Das Diagramm extrahiert dann Text-, Bild- und Audiohinweise, fusioniert sie in bewegungsbewusste Video-Latenten und rendert ein synchronisiertes MP4.
Modelle#
Diese Gruppe lädt WanVideo, VAE, MultiTalk, CLIP Vision und den Text-Encoder. WanVideoModelLoader (#122) wählt das Wan 2.1 I2V 14B GGUF-Rückgrat, während WanVideoVAELoader (#129) das passende VAE vorbereitet. MultiTalkModelLoader (#120) lädt die InfiniteTalk-Variante, die sprachgesteuerte Bewegungen antreibt. Sie können optional ein Wan LoRA in WanVideoLoraSelect (#13) anhängen, um Aussehen und Bewegung zu beeinflussen. Lassen Sie diese unangetastet für einen schnellen ersten Durchlauf; sie sind vorverkabelt für eine 480p-Pipeline, die den meisten GPUs freundlich ist.
Prompt#
WanVideoTextEncodeCached (#241) nimmt Ihre positiven und negativen Prompts und kodiert sie mit UMT5. Verwenden Sie den positiven Prompt, um das Thema und den Szenenton zu beschreiben, nicht die Identität; die Identität kommt aus dem Referenzfoto. Halten Sie den negativen Prompt auf Artefakte fokussiert, die Sie vermeiden möchten (Unschärfen, zusätzliche Gliedmaßen, graue Hintergründe). Prompts in InfiniteTalk formen hauptsächlich Beleuchtung und Bewegungsenergie, während das Gesicht konsistent bleibt.
Eingabebild#
CLIPVisionLoader (#238) und WanVideoClipVisionEncode (#237) betten Ihr Porträt ein. Verwenden Sie ein scharfes, frontales Kopf-und-Schultern-Foto mit gleichmäßigem Licht. Bei Bedarf sanft zuschneiden, damit das Gesicht Raum für Bewegung hat; starkes Zuschneiden kann die Bewegung destabilisieren. Die Bild-Einbettungen werden weitergegeben, um Identität und Kleidungsdetails zu bewahren, während das Video animiert wird.
Audio zu MultiTalk#
Laden Sie Ihre Sprache in LoadAudio (#125); schneiden Sie sie mit AudioCrop (#159) für schnelle Vorschauen. DownloadAndLoadWav2VecModel (#137) lädt Wav2Vec2 herunter, und MultiTalkWav2VecEmbeds (#194) verwandelt den Clip in phonembewusste Bewegungsmerkmale. Kurze 4–8 Sekunden Schnitte sind großartig für Iterationen; Sie können längere Takes ausführen, sobald Ihnen das Aussehen gefällt. Saubere, trockene Sprachtracks funktionieren am besten; starke Hintergrundmusik kann das Lippentiming verwirren.
Bild-zu-Video, Sampling und Ausgabe#
WanVideoImageToVideoMultiTalk (#192) verschmilzt Ihr Bild, CLIP Vision-Einbettungen und MultiTalk in bildweise Bild-Einbettungen, die durch Width und Height Konstanten dimensioniert sind. WanVideoSampler (#128) generiert die latenten Frames mit dem WanVideo-Modell von Get_wanmodel und Ihren Texteingaben. WanVideoDecode (#130) wandelt Latenten in RGB-Frames um. Schließlich kombiniert VHS_VideoCombine (#131) Frames und Audio in ein MP4 mit 25 fps bei einer ausgewogenen Qualitätseinstellung und erzeugt den finalen InfiniteTalk-Clip.
Wichtige Knoten im ComfyUI InfiniteTalk-Workflow#
WanVideoImageToVideoMultiTalk (#192)#
Dieser Knoten ist das Herzstück von InfiniteTalk: Er konditioniert die Talking-Head-Animation, indem er das Startbild, die CLIP Vision-Features und die MultiTalk-Leitlinien bei Ihrer Zielauflösung zusammenführt. Passen Sie width und height an, um das Seitenverhältnis festzulegen; 832×480 ist ein guter Standard für Geschwindigkeit und Stabilität. Verwenden Sie es als Hauptstelle, um Identität mit Bewegung vor dem Sampling auszurichten.
MultiTalkWav2VecEmbeds (#194)#
Wandelt Wav2Vec2-Features in MultiTalk-Bewegungsembeddings um. Wenn die Lippenbewegung zu subtil ist, erhöhen Sie ihren Einfluss (Audio-Skalierung) in dieser Phase; wenn sie übertrieben ist, verringern Sie den Einfluss. Stellen Sie sicher, dass das Audio sprachdominant ist, um eine zuverlässige Phonem-Timing zu gewährleisten.
WanVideoSampler (#128)#
Generiert die Video-Latenten, gegeben Bild-, Text- und MultiTalk-Einbettungen. Für erste Durchläufe halten Sie den Standard-Scheduler und die Schritte bei. Wenn Sie Flackern sehen, kann eine Erhöhung der Gesamtschritte oder das Aktivieren von CFG helfen; wenn sich die Bewegung zu steif anfühlt, reduzieren Sie CFG oder die Sampler-Stärke.
WanVideoTextEncodeCached (#241)#
Kodiert positive und negative Prompts mit UMT5-XXL. Verwenden Sie prägnante, konkrete Sprache wie "Studio-Licht, weiche Haut, natürliche Farbe" und halten Sie negative Prompts fokussiert. Denken Sie daran, dass Prompts das Framing und den Stil verfeinern, während die Mundsynchronisation von MultiTalk kommt.
Optionale Extras#
- Halten Sie MultiTalk und WanVideo in derselben Bereitstellungsfamilie (alle GGUF oder alle nicht-GGUF), um Inkompatibilitäten zu vermeiden.
- Iterieren Sie mit einem 5–8 Sekunden Audio-Crop und der Standard-480p-Größe; skalieren Sie später bei Bedarf hoch.
- Wenn die Identität wackelt, versuchen Sie ein saubereres Quellfoto oder ein milderes LoRA. Starke LoRAs können die Ähnlichkeit überschreiben.
- Nehmen Sie Sprache in einem ruhigen Raum auf und normalisieren Sie die Pegel; InfiniteTalk verfolgt Phoneme am besten mit klarer, trockener Stimme.
Danksagungen#
Der InfiniteTalk-Workflow stellt einen großen Fortschritt in der KI-gestützten Videogenerierung dar, indem er das flexible Knotensystem von ComfyUI mit dem MultiTalk AI-Modell kombiniert. Diese Implementierung wurde dank der ursprünglichen Forschung und Veröffentlichung von MeiGen-AI ermöglicht, deren MultiTalk-Projekt die natürliche Sprachsynchronisation von InfiniteTalk antreibt. Besonderer Dank geht auch an das InfiniteTalk-Projektteam für die Bereitstellung der Referenzquelle und an die ComfyUI-Entwicklergemeinschaft für die nahtlose Workflow-Integration.
Darüber hinaus geht der Dank an Kijai, der InfiniteTalk in den Wan Video Sampler-Knoten implementiert hat und es Schöpfern erleichtert, hochwertige sprechende und singende Porträts direkt in ComfyUI zu erstellen. Der ursprüngliche Ressourcenlink für InfiniteTalk ist hier verfügbar: InfiniteTalk Example Workflow.
Zusammen ermöglichen diese Beiträge Schöpfern, einfache Porträts in lebensechte, kontinuierlich sprechende Avatare zu verwandeln und neue Möglichkeiten für KI-gesteuertes Storytelling, Dubbing und Performance-Inhalte zu erschließen.