
ComfyUI F5 TTS: Zero-Shot-Text-zu-Sprache und Stimmklonung in einem Workflow#
Dieser ComfyUI F5 TTS-Workflow ermöglicht es Ihnen, natürliche Sprache aus Text zu generieren und Stimmen direkt in ComfyUI zu klonen. Er wird von den ComfyUI-F5-TTS benutzerdefinierten Nodes angetrieben und enthält einen vollständigen Pfad für referenzbasiertes Klonen: Geben Sie ein kurzes WAV plus ein passendes Transkript an, um das Modell zu konditionieren, und synthetisieren Sie dann neue Zeilen, die dem Timbre und Stil des Referenzsprechers folgen. Der Graph wird auch mit einsatzbereiten Tests für mehrere Modellvarianten, Sprachen und Vocoder geliefert, sodass Sie Ausgaben schnell vergleichen und entscheiden können, was am besten für Erzählungen, Voiceovers, Charakterdialoge oder Produktdemos geeignet ist.
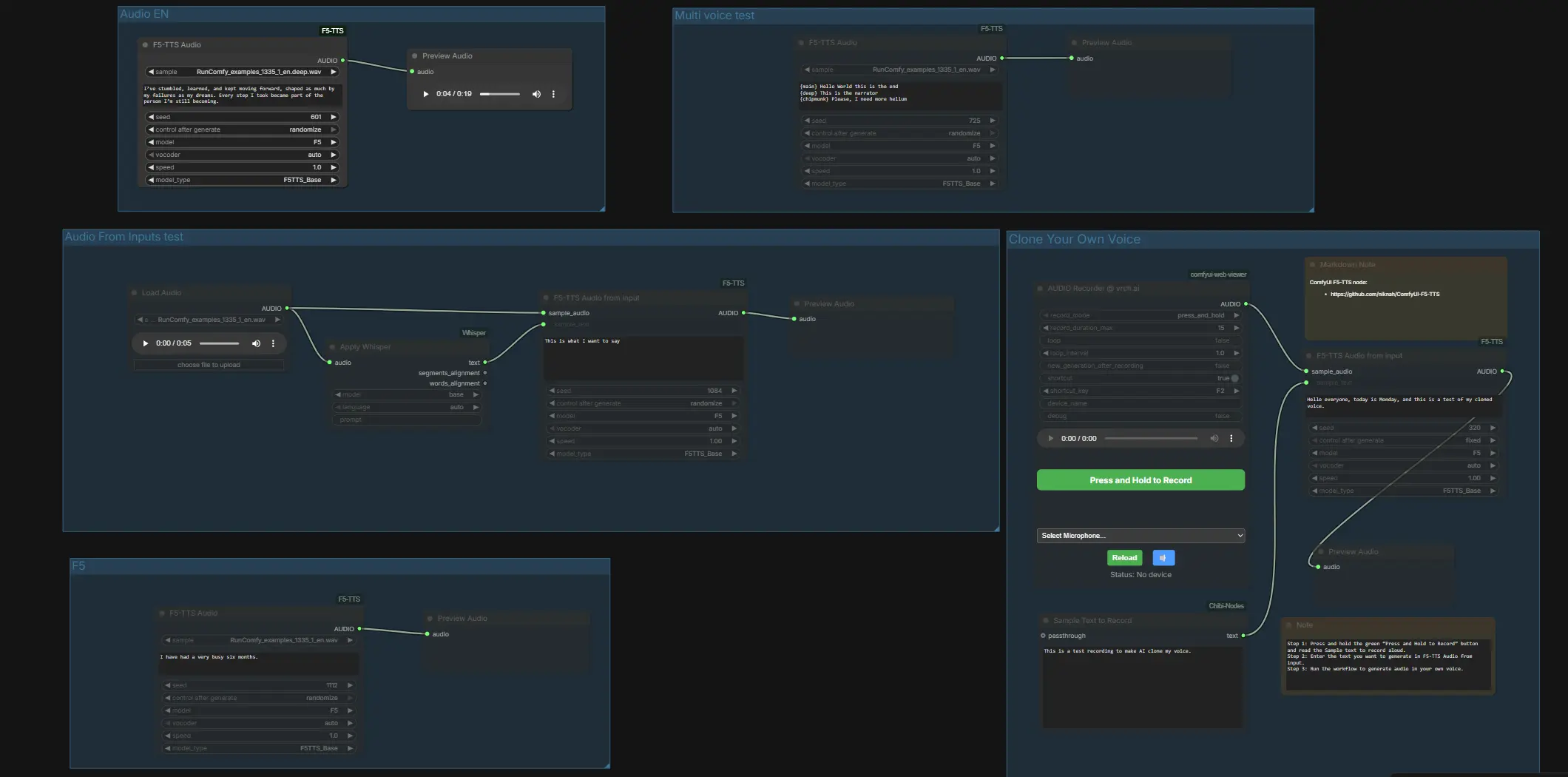
Alles ist in klare Gruppen unterteilt, sodass Sie ComfyUI F5 TTS auf zwei Arten nutzen können: schnelles, One-Click-TTS in Englisch, Französisch, Deutsch und Japanisch oder Stimmklonung über einen eingebauten Rekorder oder gepaarte Dateien. Ein kompakter Whisper-Transkriptionspfad ist enthalten, um Ihnen zu helfen, ein genaues Beispieltranskript zu erhalten, wenn Sie bereits eine saubere Aufnahme haben.
Wichtige Modelle im ComfyUI F5 TTS-Workflow#
- Fish Audio F5-TTS. Zero-Shot-TTS, das die Merkmale eines Sprechers aus einer kurzen Referenz lernt und hochwertige Sprache in mehreren Sprachen produziert. Siehe das Projekt für Modelldetails und Trainingshintergründe. GitHub
- OpenAI Whisper. Spracherkennung, die hier verwendet wird, um Ihren Referenzclip automatisch zu transkribieren, sodass der Beispieltext genau übereinstimmt, was die Klonqualität verbessert. GitHub
- BigVGAN. Ein hochauflösender neuronaler Vocoder verfügbar als Dekodierungsoption für schärfere, knackigere Ausgaben. GitHub
- Vocos. Eine schnelle, leichte neuronale Vocoder-Alternative, die auf Geschwindigkeit und niedrige Latenz ausgerichtet ist. GitHub
- ComfyUI-F5-TTS benutzerdefinierte Nodes. Die ComfyUI-Integration, die F5-TTS und kompatible Backends in Nodes verdrahtet, die in diesem Graph verwendet werden. GitHub
Verwendung des ComfyUI F5 TTS-Workflows#
Auf hoher Ebene bietet der Workflow unabhängige Gruppen für schnelle Modellvergleiche und eine dedizierte Klonspur. Beginnen Sie mit dem Ausprobieren der vorkonfigurierten Gruppen, um die gewünschte Stimme und den Vocoder zu bestätigen, und wechseln Sie dann zum Klonen mit Ihrem eigenen Beispiel. Jeder Unterabschnitt unten erklärt, was die Gruppe tut und die wenigen Eingaben, die wichtig sind.
Audio From Inputs Test#
Diese Spur demonstriert Referenztranskription plus Konditionierung. LoadAudio (#4) bringt ein WAV herein, Apply Whisper (#13) transkribiert es, und F5TTSAudioInputs (#26) verwendet sowohl das Beispielaudio als auch den Whisper-Text, um die Stimme vor der Vorschau zu konditionieren. Stellen Sie ein sauberes, gesprochenes Beispiel bereit und lassen Sie Whisper den Transkriptport ausfüllen, damit das Paar genau übereinstimmt. Wenn Sie Dateien direkt bereitstellen möchten, platzieren Sie ein gepaartes .wav und .txt mit demselben Dateinamen in ComfyUI/input und starten Sie ComfyUI neu, damit der Graph sie sehen kann.
Multi Voice Test#
Diese Gruppe zeigt stilistische Wechsel innerhalb einer Zeile mit einem einzigen Syntheseknoten. F5TTSAudio (#17) liest ein Skript mit markierten Segmenten, sodass Sie mehrere Charakterstile oder Betonungsänderungen in einem Durchgang ausprobieren können. Es ist eine schnelle Möglichkeit, zu hören, wie ComfyUI F5 TTS kontrastierende Klangfarben oder Erzähler-gegen-Charakter-Taktung handhabt.
Audio EN#
Verwenden Sie F5TTSAudio (#15) für einfaches englisches TTS. Geben Sie Ihr Skript ein und sehen Sie sich die Vorschau an, um die grundlegende Aussprache und Taktung mit dem Standard-F5-Preset zu bewerten. Diese Spur ist ideal für schnelle Iterationen, bevor Sie sich zum Klonen oder Mischen mehrerer Stimmen verpflichten.
F5v1#
Dieser Pfad führt den F5TTSAudio (#33) Knoten gegen die F5 v1 Variante aus, sodass Sie Ton und Prosodie mit dem Haupt-F5-Preset vergleichen können. Verwenden Sie denselben Text wie die EN-Spur, um Unterschiede leicht beurteilen zu können. Es ist hilfreich bei der Wahl eines Standardmodells für ein längeres Projekt.
Audio FR#
Diese Spur zielt auf französische Synthese mit F5TTSAudio (#27), das für ein französisches Preset konfiguriert ist. Geben Sie ein französisches Skript ein und sehen Sie sich die Ausgabe an, um Nasenvokale und Liaison-Handhabung zu überprüfen. Wechseln Sie zwischen der EN-Spur hin und her, um Klarheit und Geschwindigkeit zu vergleichen.
Audio DE bigvgan#
Hier verwendet F5TTSAudio (#30) ein deutsches Preset und den BigVGAN-Vocoder für eine hellere, knackigere Dekodierung. Verwenden Sie diese Spur, wenn Sie mehr Präsenz oder einen Studio-ähnlichen Glanz wünschen. Wenn Sie eine weichere Wiedergabe bevorzugen, vergleichen Sie sie mit einer Vocos-Spur.
Audio JP#
Dieser Pfad verwendet F5TTSAudio (#25) mit einem japanischen Preset. Fügen Sie ein japanisches Skript ein, um Tonhöhe und Mora-Timing zu bewerten. Es ist ein guter Ausgangspunkt für Anime-Stil-Lesungen oder Produktlinien, die für ein japanisches Publikum bestimmt sind.
E2 Test#
Diese Gruppe testet F5TTSAudio (#29) mit einem E2-kompatiblen Preset und dem Vocos-Vocoder, um ein alternatives Backend auszuprobieren. Verwenden Sie es, um Latenz- und Klangfarbenmerkmale mit Ihren F5-Läufen zu vergleichen.
Klonen Sie Ihre eigene Stimme#
Nehmen Sie direkt in ComfyUI auf, paaren und klonen Sie. Drücken Sie das Mikrofon in VrchAudioRecorderNode (#43) und lesen Sie den im "Sample Text to Record"-Feld Textbox (#42) angezeigten Prompt vor. Der Rekorder leitet Ihr WAV an F5TTSAudioInputs (#44) zusammen mit dem genauen Text, den Sie gesprochen haben, weiter, was das Modell auf Ihr Timbre und Ihren Stil konditioniert, bevor es in PreviewAudio (#45) in der Vorschau angezeigt wird. Für beste Ergebnisse sprechen Sie in einem ruhigen Raum und stellen Sie sicher, dass der Referenztext genau dem entspricht, was Sie gesagt haben; dann geben Sie alle neuen Zeilen ein, die die geklonte Stimme sagen soll, und führen Sie den Graph aus.
Wichtige Nodes im ComfyUI F5 TTS-Workflow#
F5TTSAudio (#15)#
Der zentrale Single-Pass-TTS-Knoten, der in den EN-, FR-, DE-, JP-, F5v1- und E2-Gruppen verwendet wird. Geben Sie Ihr Skript ein und wählen Sie das Modell-Preset und den Vocoder, der Ihrer Sprache und Ihrem Vortrag entspricht. Wenn Sie reproduzierbare Takes möchten, halten Sie den Seed fest; wenn Sie Vielfalt möchten, randomisieren Sie zwischen den Läufen. Die Implementierung wird durch die ComfyUI-F5-TTS-Erweiterung bereitgestellt. GitHub GitHub - FishAudio/F5-TTS
F5TTSAudioInputs (#44)#
Der Kloneinstiegspunkt, der ein Referenz-WAV und sein passendes Transkript verwendet, um eine Sprecherrepräsentation zu erstellen und dann neue Zeilen in dieser Stimme zu synthetisieren. Verwenden Sie ein sauberes Beispiel mit gleichmäßiger Lautstärke und stellen Sie sicher, dass das Transkript genau ist, um Ähnlichkeiten zu maximieren und Artefakte zu reduzieren. Wechseln Sie hier die Modell-Presets oder Vocoder, wenn Sie eine hellere oder neutralere Dekodierung benötigen. GitHub - FishAudio/F5-TTS
Apply Whisper (#13)#
Automatische Transkription für Ihr Referenzbeispiel. Wählen Sie eine Whisper-Größe, die Geschwindigkeit und Genauigkeit für Ihre Hardware und Sprache ausbalanciert, und geben Sie dann den Textausgang an den Klon-Knoten weiter, sodass Audio und Text perfekt aufeinander abgestimmt sind. Dies verhindert Konditionierungsfehler, die auftreten können, wenn der Beispieltext von dem abweicht, was tatsächlich gesprochen wurde. GitHub
VrchAudioRecorderNode (#43)#
Ein integrierter Rekorder, der einen kurzen gesprochenen Prompt für das Klonen aufzeichnet und die Notwendigkeit externer Werkzeuge beseitigt. Halten Sie zum Aufnehmen, lassen Sie los, um zu stoppen, und hören Sie sofort, wie ComfyUI F5 TTS in Ihrer eigenen Stimme klingt. Halten Sie das Mikrofon nah und reduzieren Sie Raumgeräusche für das sauberste Ergebnis.
Optionale Extras#
- Verwenden Sie 5 bis 15 Sekunden saubere Sprache für die Referenz, ohne Musik oder Effekte.
- Stellen Sie sicher, dass das Beispieltranskript genau mit der Aufnahme übereinstimmt; selbst kleine Abweichungen können die Klontreue verringern.
- Vergleichen Sie Vocos und BigVGAN in derselben Zeile, um zwischen Geschwindigkeit und Detail zu entscheiden.
- Halten Sie einen festen Seed, wenn Sie konsistente Wiederholungen benötigen; randomisieren Sie beim Erkunden von Stilen.
- Für mehrsprachige Projekte testen Sie zuerst die EN-, FR-, DE- und JP-Spuren und finalisieren Sie das Klonen, wenn Sie mit Aussprache und Taktung zufrieden sind.
Danksagungen#
Dieser Workflow implementiert und baut auf den folgenden Arbeiten und Ressourcen auf. Wir danken niknah für den ComfyUI-F5-TTS-Knoten, niknah für das F5TTS-test-all.json Beispiel-Workflow und der r/StableDiffusion-Community für den "Voice Cloning with F5-TTS in ComfyUI"-Leitfaden für ihre Beiträge und Wartung. Für autoritative Details verweisen Sie bitte auf die Originaldokumentation und die unten verlinkten Repositories.
Ressourcen#
- niknah/ComfyUI-F5-TTS
- GitHub: niknah/ComfyUI-F5-TTS
- niknah/ComfyUI-F5-TTS (Beispiel-Workflow: F5TTS-test-all.json)
- r/StableDiffusion/Community Guide (Voice Cloning with F5-TTS in ComfyUI)
Hinweis: Die Nutzung der referenzierten Modelle, Datensätze und Codes unterliegt den jeweiligen Lizenzen und Bedingungen der Autoren und Maintainer.
