
大家好!在本指南中,我們將深入探討 ControlNet 在 ComfyUI 中的精彩世界。讓我們一起探索它所帶來的優勢,以及如何為你的創作項目注入更多色彩與可控性!
我們將涵蓋以下內容:
- 3.1. 在 ComfyUI 中載入「Apply ControlNet」節點
- 3.2. 「Apply ControlNet」節點的輸入
- 3.3. 「Apply ControlNet」節點的輸出
- 3.4. 微調「Apply ControlNet」的參數
5. 各種 ControlNet / T2I Adapter 模型:詳細介紹#
- 5.1. ControlNet OpenPose
- 5.2. ControlNet Tile
- 5.3. ControlNet Canny
- 5.4. ControlNet Depth
- 5.5. ControlNet Lineart
- 5.6. ControlNet Scribbles
- 5.7. ControlNet Segmentation
- 5.8. ControlNet Shuffle
- 5.9. ControlNet Inpainting
- 5.10. ControlNet MLSD
- 5.11. ControlNet Normalmaps
- 5.12. ControlNet Soft Edge
- 5.13. ControlNet IP2P(Instruct Pix2Pix)
- 5.14. T2I Adapter
- 5.15. 其他熱門 ControlNet:QRCode Monster 和 IP-Adapter
6. 如何同時使用多個 ControlNet#
7. 立即體驗 ComfyUI ControlNet!#
🌟🌟🌟 ComfyUI 線上體驗 - 立即開啟 ControlNet 工作流程 🌟🌟🌟#
如果你有興趣探索 ControlNet 工作流程,請使用下方的 ComfyUI 網頁版本。它預載了所有必要的自訂節點與模型,讓你無需任何手動安裝即可無縫創作。馬上開始動手實驗 ControlNet 的強大功能,或者繼續閱讀本教學深入瞭解如何有效使用它!
更多進階與付費版 ComfyUI 工作流程,請造訪我們的 🌟ComfyUI 工作流程列表🌟#
1. 什麼是 ControlNet?#
ControlNet 是一項變革性技術,顯著增強了文字轉圖像擴散模型的能力,實現前所未有的圖像生成空間控制。作為一種神經網路架構,ControlNet 可以與大型預訓練模型(如 Stable Diffusion)無縫整合。它利用這些在數十億張圖像上訓練的模型 將空間條件引入圖像創建過程。這些條件涵蓋範圍廣泛,從邊緣與人體姿勢到深度與分割圖,讓使用者能以純文字提示難以實現的方式,引導圖像生成。
2. ControlNet 背後的技術原理#
ControlNet 的巧妙之處在於其獨特方法。首先,它固定原始模型參數,確保基礎訓練保持不變。然後,ControlNet 引入一個編碼層的複製模型進行訓練,並採用「零卷積」。這些特殊設計的卷積層以零權重起始,謹慎地整合新的空間條件。這種方式避免引入干擾噪聲,保留模型原有能力的同時,開啟新的學習路徑。
3. 如何使用 ComfyUI ControlNet:基本步驟#
傳統 Stable Diffusion 模型透過文字提示引導圖像生成,使輸出與提示語保持一致。ControlNet 則引入額外的條件機制,強化對生成圖像的精確控制。
3.1. 在 ComfyUI 中載入 "Apply ControlNet" 節點#
這一步將 ControlNet 整合進 ComfyUI 工作流程,讓它能在生成圖像時加入額外的控制條件,奠定結合視覺引導與文字提示的基礎。
3.2. "Apply ControlNet" 節點的輸入#
正面與負面條件:定義希望的輸出與應避免的特徵,需分別連接到正面提示與負面提示節點。
ControlNet 模型:連接至 "Load ControlNet Model" 節點。這是選擇 ControlNet 或 T2I Adaptor 模型並納入流程的關鍵。每個模型經過嚴格訓練,可根據特定數據或風格偏好影響圖像生成。我們主要聚焦 ControlNet,但會補充介紹熱門 T2I Adaptor。
預處理器:"image" 輸入必須連接 "ControlNet Preprocessor" 節點,這對於圖像與選定模型相容至關重要。必須使用正確的預處理器,如格式、大小、色彩或濾鏡的調整,以最佳化 ControlNet 引導效果。
3.3. "Apply ControlNet" 節點的輸出#
"Apply ControlNet" 輸出兩個主要條件:正面與負面條件,這些輸出融合了 ControlNet 視覺引導的影響,控制 ComfyUI 擴散模型的生成行為。
你可以接續進入 KSampler 進行採樣,或加入更多 ControlNet 進行進階操控。這讓對圖像屬性有高度精準需求的創作者,能透過多層控制打造更細膩的結果。
3.4. 微調 "Apply ControlNet" 參數#
- strength:控制 ControlNet 對輸出影響的強度。1.0 表示最大影響,0.0 表示關閉。
- start_percent:指定從擴散過程中幾%開始應用 ControlNet。
- end_percent:定義 ControlNet 停止影響的階段,例如 80% 表示在過程的後 20% 不再受 ControlNet 引導。
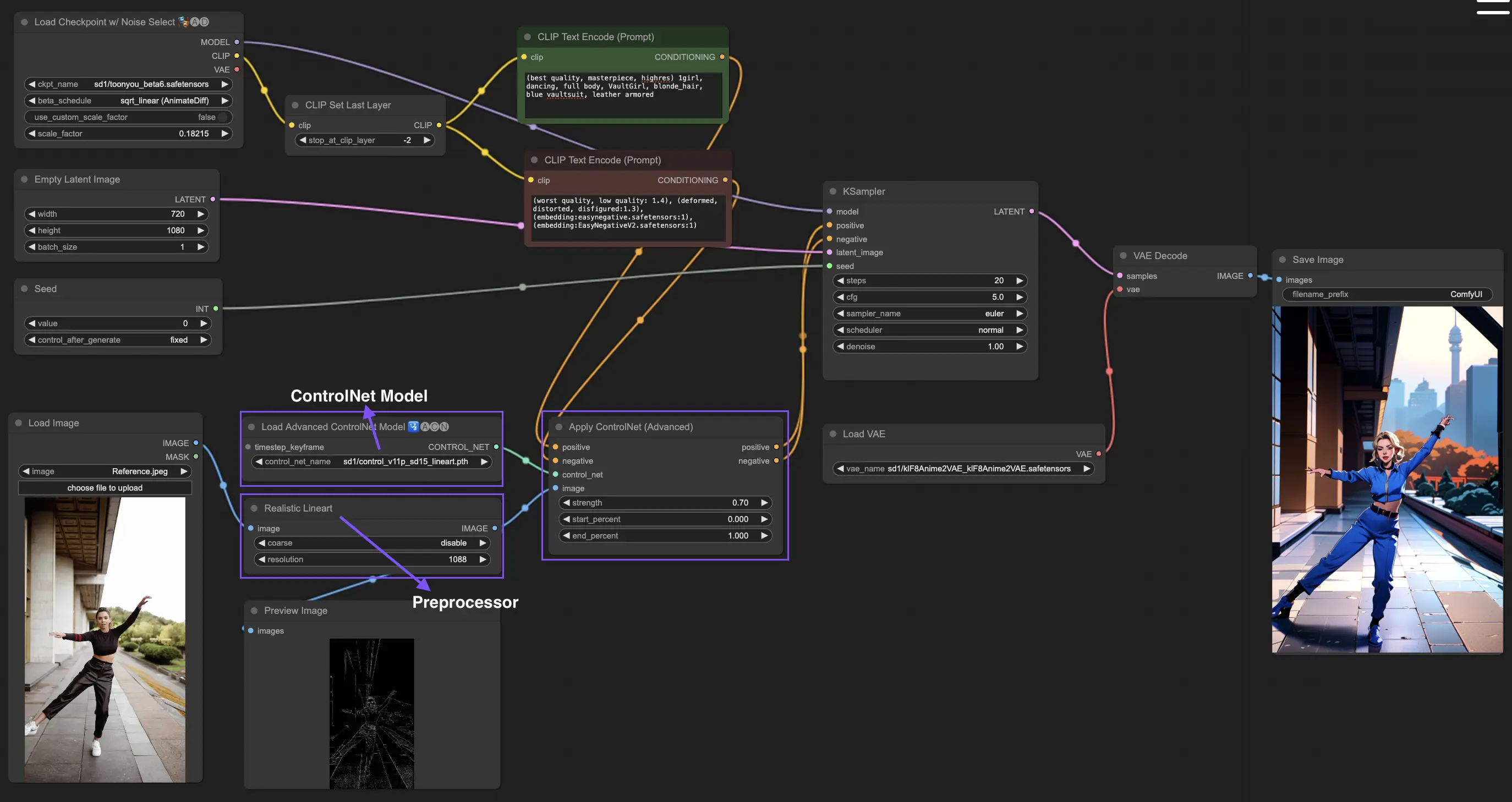
4. 如何使用 ComfyUI ControlNet:進階功能 - 時間步關鍵影格#
在 ControlNet 中,時間步關鍵影格為 AI 生成內容提供了細緻的行為控制,特別適用於時間與進展至關重要的情境,例如動畫製作或逐漸演變的視覺效果。以下是這些關鍵參數的詳細說明,幫助你有效且直觀地運用它們:
prev_timestep_kf:你可以把 prev_timestep_kf 想成是與序列中前一個關鍵影格的連結。透過串接這些關鍵影格,你能創造出平滑過渡的動畫流程,就像是導演逐格引導 AI 完成畫面,確保每個階段都能自然銜接下一段。
cn_weights:cn_weights 用於調整 ControlNet 在不同生成階段的特定特徵強度,讓你可以更加細緻地雕琢最終結果。
latent_keyframe:latent_keyframe 可在生成過程中的特定時間點調整 AI 模型內部潛變因素的影響程度。例如,如果你想讓畫面中的前景隨著進程變得更清晰,可在後期關鍵影格中提升前景細節相關潛變因素的強度。相反,若你希望某些元素隨時間淡出,可在接續的影格中逐步降低其強度。這對創作具有動態層次或需時間演進控制的作品尤其有用。
mask_optional:透過注意力遮罩 (Attention Mask),你可以如聚光燈般將 ControlNet 的影響聚焦於圖像中特定區域。無論是強調場景中的角色還是背景物件,你都能精準調整 AI 的注意力方向。這些遮罩既可統一套用,也能分別調整強度。
start_percent:此參數表示關鍵影格開始發揮作用的時機,以整個生成過程的百分比計算。就像安排演員在舞台的出場時間,設定得恰到好處能讓生成過程更具節奏與邏輯。
strength:控制該關鍵影格中 ControlNet 整體影響力的強度值。你可以依據需求精準微調此值,以達成理想的視覺控制。
null_latent_kf_strength:針對在此影格中未被明確定義的潛變因素,null_latent_kf_strength 就像是預設劇本,確保這些未明言指示的「演員」仍能以一致的方式在背景中運作,避免出現破圖或不連貫的畫面。
inherit_missing:啟用此參數可讓當前關鍵影格「繼承」前一影格未設定的屬性,就像弟妹穿哥哥姊姊的舊衣服一樣,這能減少重複設置,提升效率並保有生成連貫性。
guarantee_usage:這是你的保證書——無論如何,當前影格都會在生成過程中被實際應用到,哪怕只是極短的一瞬。這確保你為每個關鍵影格所做的設置都能發揮效果,並忠實地體現你的創作意圖。
關鍵影格為 AI 藝術創作提供了細膩的節奏安排與精確的時序控制。透過這些參數,你可以如導演般掌控生成流程,從第一幀到最後一幀,構築出與你構思完美契合的動畫敘事。
5. 各種 ControlNet/T2IAdaptor 模型:詳細概述#
鑑於許多 T2IAdaptor 模型的功能與 ControlNet 模型非常相似,我們後續討論的重點將主要放在 ControlNet 模型上。但為了完整性,我們也會介紹一些更受歡迎的 T2IAdaptor 模型。
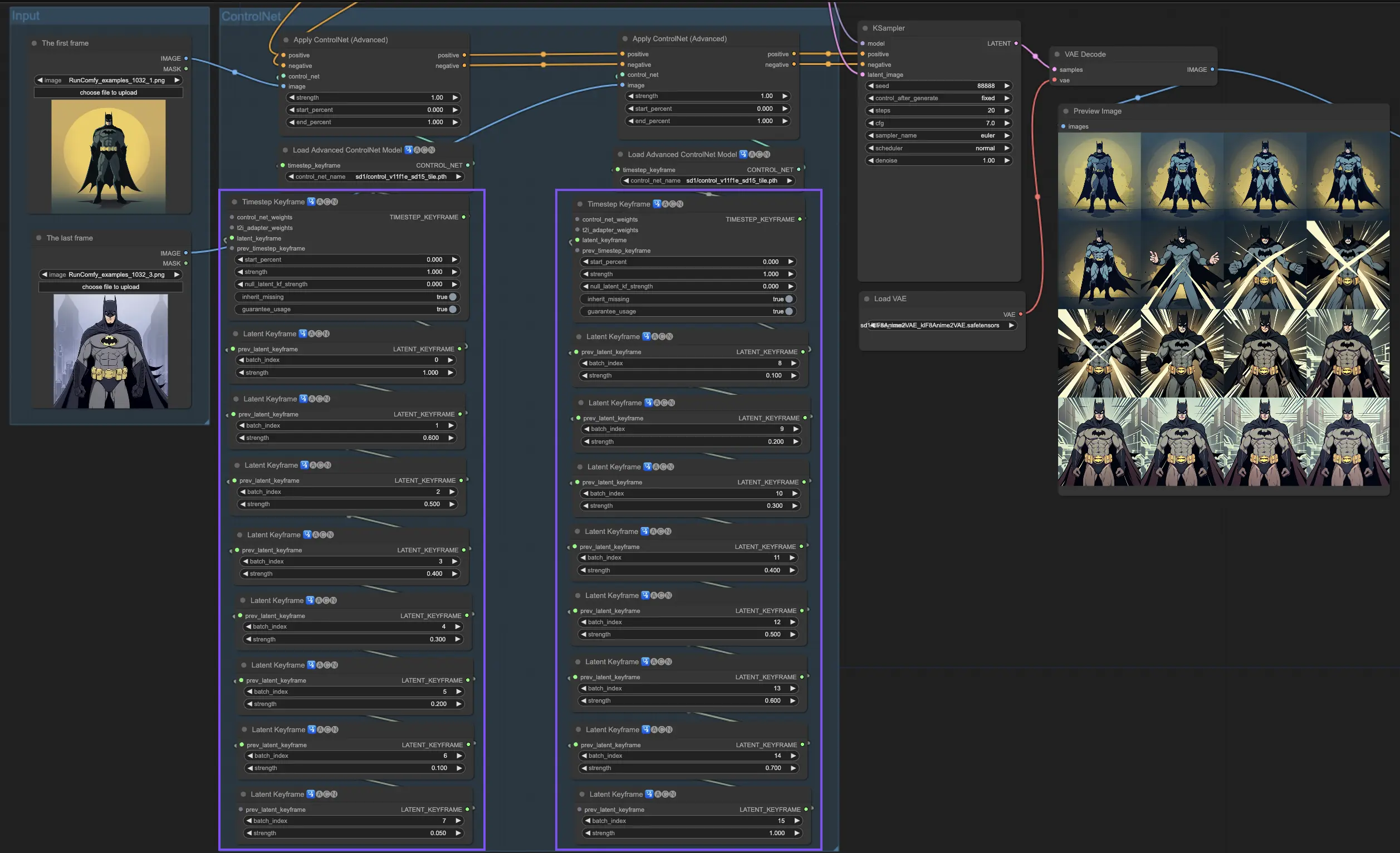
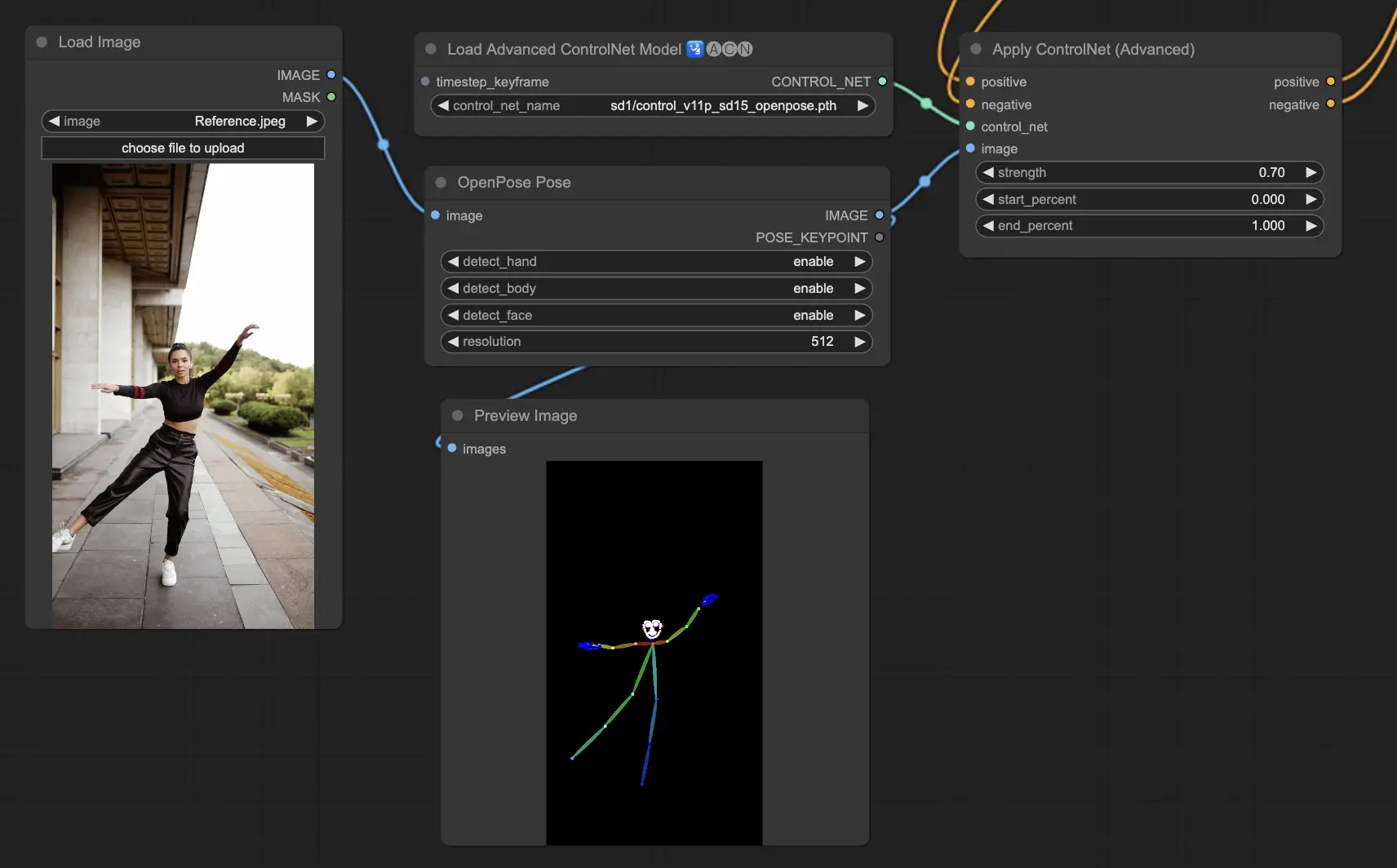
5.1. ComfyUI ControlNet Openpose#
- Openpose (=Openpose body):ControlNet 中的基礎模型,可識別眼睛、鼻子、脖子、肩膀、手肘、手腕、膝蓋與腳踝等人體關鍵點。非常適合進行基本姿勢複製。
- Openpose_face:在原有 Openpose 模型基礎上加入臉部關鍵點偵測,能更細緻分析表情與臉部方向。適用於聚焦表情的生成場景。
- Openpose_hand:強化模型對手部與手指細節的捕捉能力,專注於更精細的手勢與位置追蹤。
- Openpose_faceonly:專門針對臉部的 ControlNet 模型,省略身體部位,特別適用於表情動畫與面部特寫。
- Openpose_full:綜合 Openpose、Openpose_face 與 Openpose_hand,完整支援全身、臉部與手部姿勢識別,是全功能姿勢控制模型。
- DW_Openpose_full:Openpose_full 的增強版本,加入更多細節與姿勢準確性的改良,是目前 ControlNet 中最精細的姿勢偵測模型之一。
預處理器:Openpose 或 DWpose
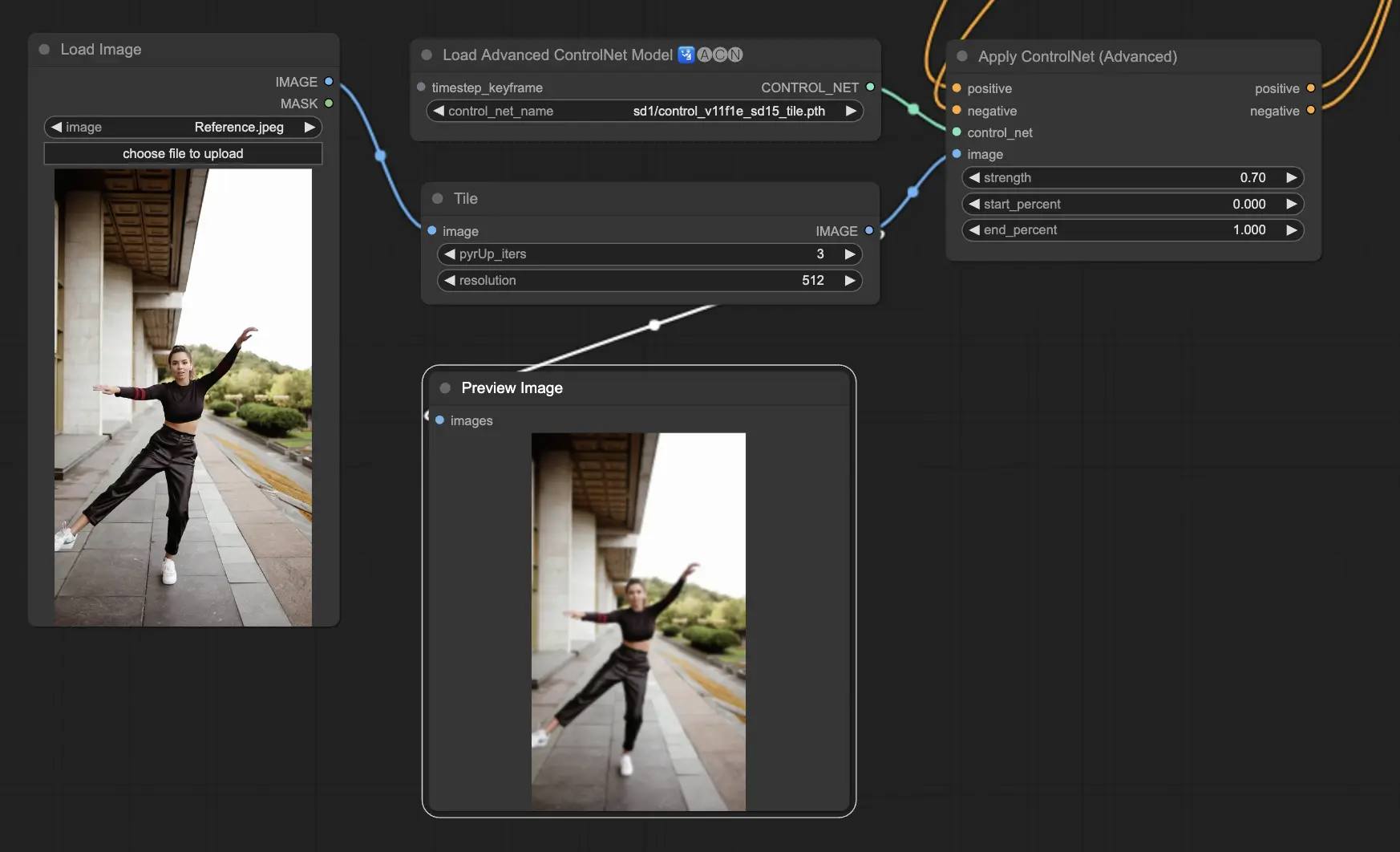
5.2. ComfyUI ControlNet Tile#
Tile Resample 模型用於圖像細節的增強。特別適合搭配上採樣器使用,能在提升解析度的同時增添更多紋理與細節,常用於銳化處理與視覺豐富化。
預處理器:Tile
5.3. ComfyUI ControlNet Canny#
Canny 模型應用經典的 Canny 邊緣偵測演算法,透過多階段過濾保留圖像結構輪廓。此模型適合用於程式化藝術創作或進一步處理前的預處理階段。
預處理器:Canny
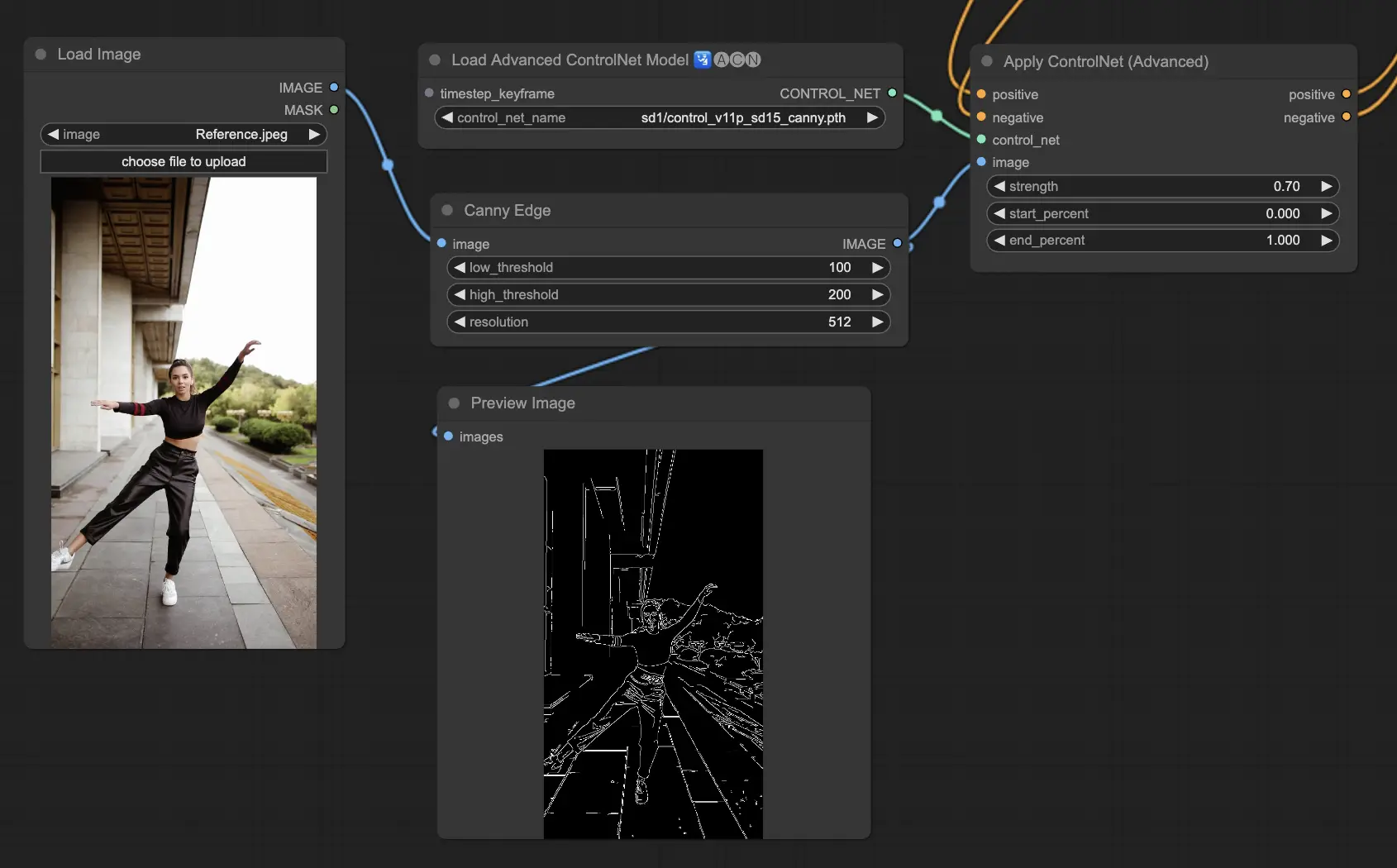
5.4. ComfyUI ControlNet Depth#
Depth 模型從 2D 圖像中推測深度資訊,並轉換為灰階深度圖像。不同版本提供細節強度與背景解析度上的平衡選擇:
- Depth Midas:平衡細節與背景的經典深度估計模型。
- Depth Leres:偏重細節呈現,包含更多背景資訊。
- Depth Leres++:提供極致細節的深度估計,適合複雜場景。
- Zoe:在 Midas 與 Leres 之間取得視覺與精準度的平衡。
- Depth Anything:最新進模型,能適應多種場景,具有強大泛用性。
- Depth Hand Refiner:專為增強手部深度細節設計,適合需要手部定位精確的場景。
預處理器:Depth_Midas、Depth_Leres、Depth_Zoe、Depth_Anything、MeshGraphormer_Hand_Refiner。此模型非常穩健,亦支援真實深度圖的處理。
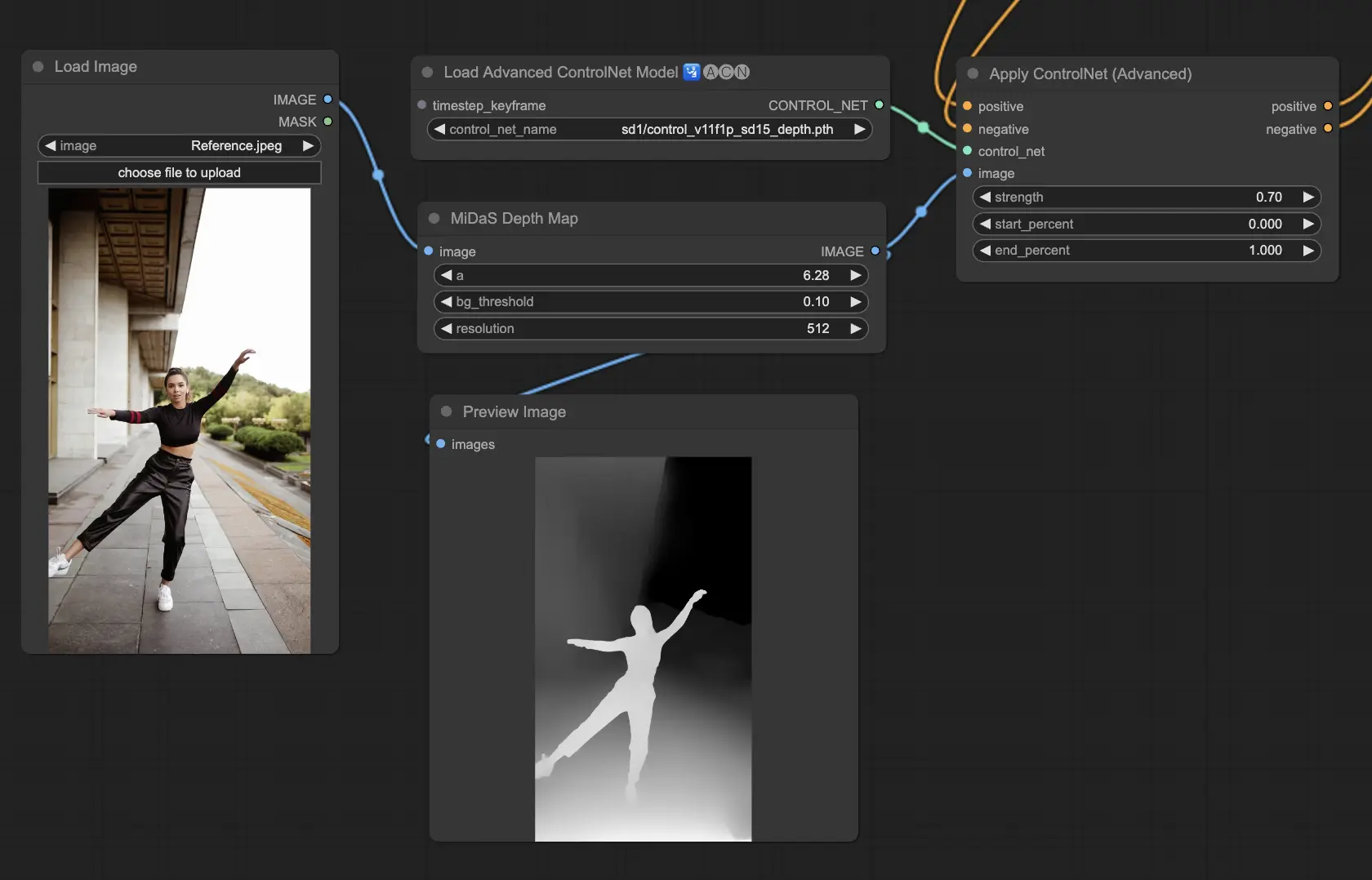
5.5. ComfyUI ControlNet Lineart#
Lineart 模型將圖片轉換為風格化的線條草圖,常作為藝術創作或動畫的基礎視覺草圖:
- Lineart:標準模型,輸出通用型風格化線條圖,適用於多數藝術創作。
- Lineart anime:專為動漫風格優化,線條乾淨俐落,適合需要日式漫畫風格的項目。
- Lineart realistic:轉換成更寫實風格的線稿,捕捉更多細節,適用於追求真實視覺的應用。
- Lineart coarse:生成粗重且醒目的線條,適合強烈風格化或大膽視覺效果的作品。
預處理器:Lineart 或 Lineart_Coarse
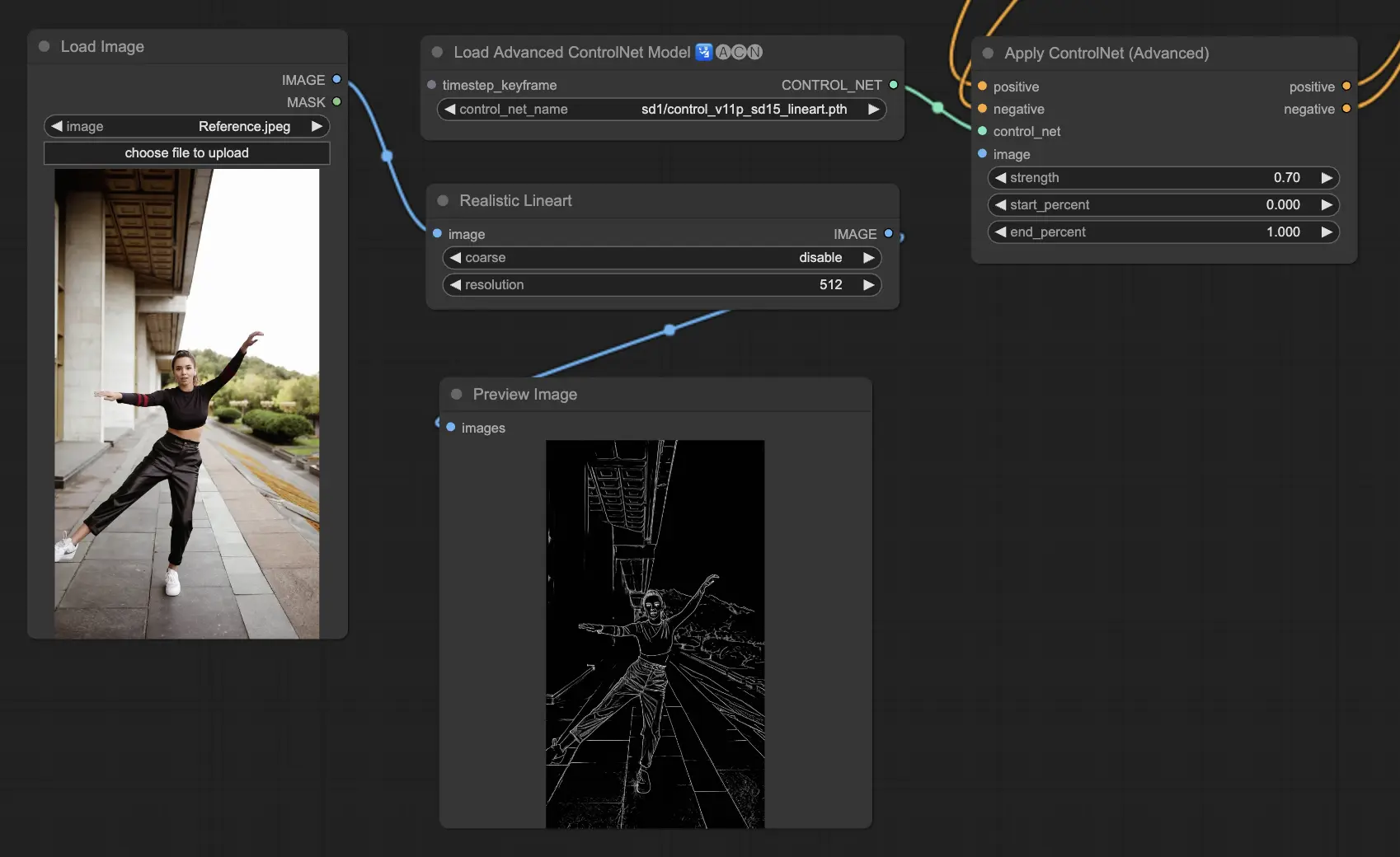
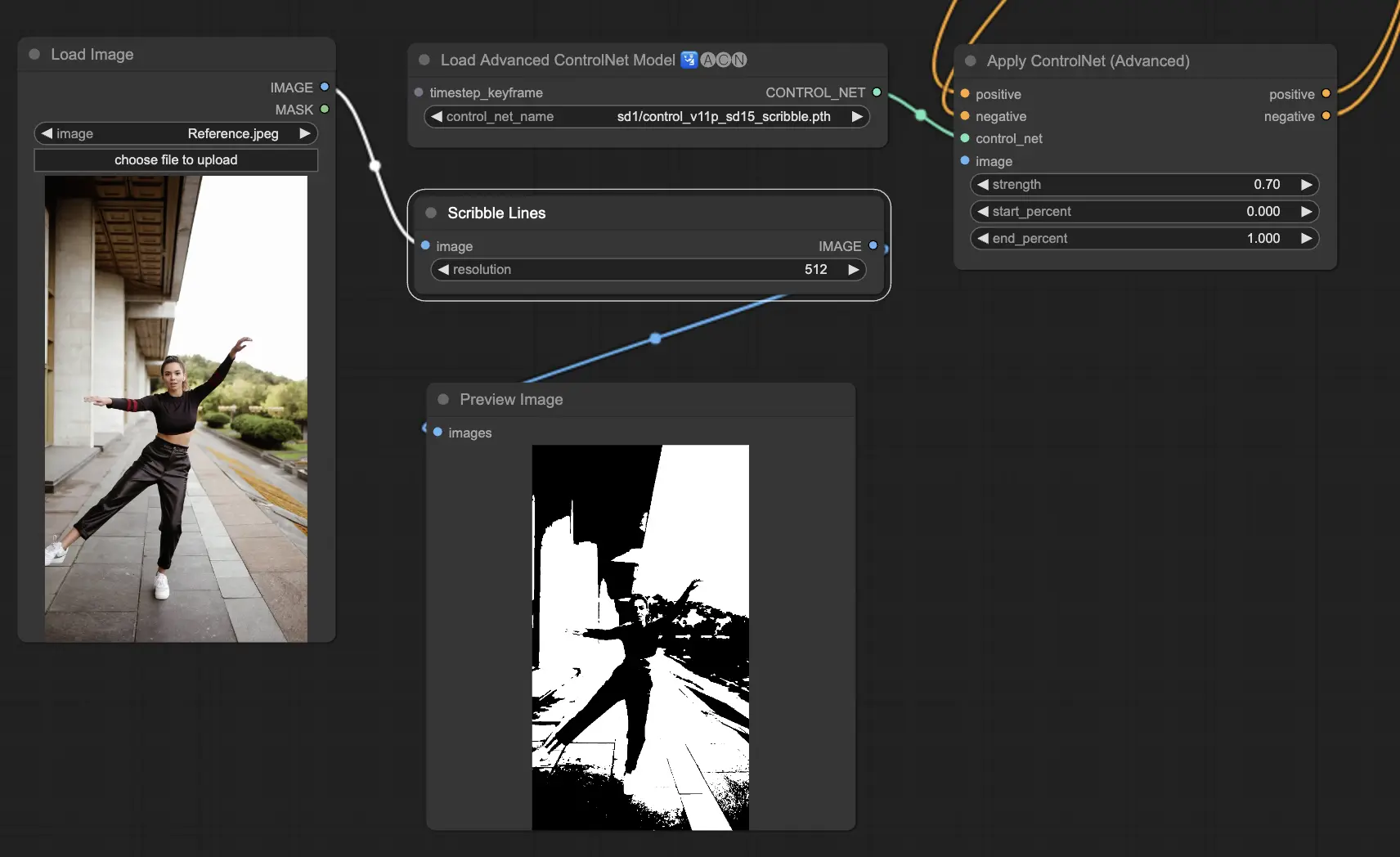
5.6. ComfyUI ControlNet Scribbles#
Scribble 模型旨在將圖像轉換為類似塗鴉的外觀,模擬手繪草圖的風格。它們特別適用於藝術重塑,或作為更大設計流程中的初步草圖階段:
- Scribble:將圖像轉換為詳細的藝術草圖,模仿手繪塗鴉風格。
- Scribble HED:使用 Holistically-Nested Edge Detection(HED)技術生成類似手繪的輪廓,適合圖像的重上色與風格化轉換。
- Scribble Pidinet:專注於像素差異偵測,生成更清晰、減少雜訊的線條,適合抽象化的藝術表現。
- Scribble xdog:應用擴展差分高斯(xDoG)方法進行邊緣檢測,可調整閾值微調塗鴉效果,提供高控制性與表現力。
預處理器:Scribble、Scribble_HED、Scribble_PIDI 和 Scribble_XDOG
5.7. ComfyUI ControlNet Segmentation#
Segmentation 模型將圖像像素分類為不同物件類別,每一類使用特定顏色標示,這在分離前景與背景或針對特定物件進行編輯時極為有用:
- Seg:基本模型,透過顏色區分圖像中的物件。
- ufade20k:基於 ADE20K 資料集的 UniFormer 分割模型,支援多種類別的物件分割。
- ofade20k:使用 OneFormer 架構,在 ADE20K 上訓練,提供不同角度的分割風格。
- ofcoco:在 COCO 資料集上訓練的 OneFormer 版本,適用於 COCO 類別定義下的物件分割與操作。
可用預處理器:Sam、Seg_OFADE20K、Seg_UFADE20K、Seg_OFCOCO,或手動建立遮罩。
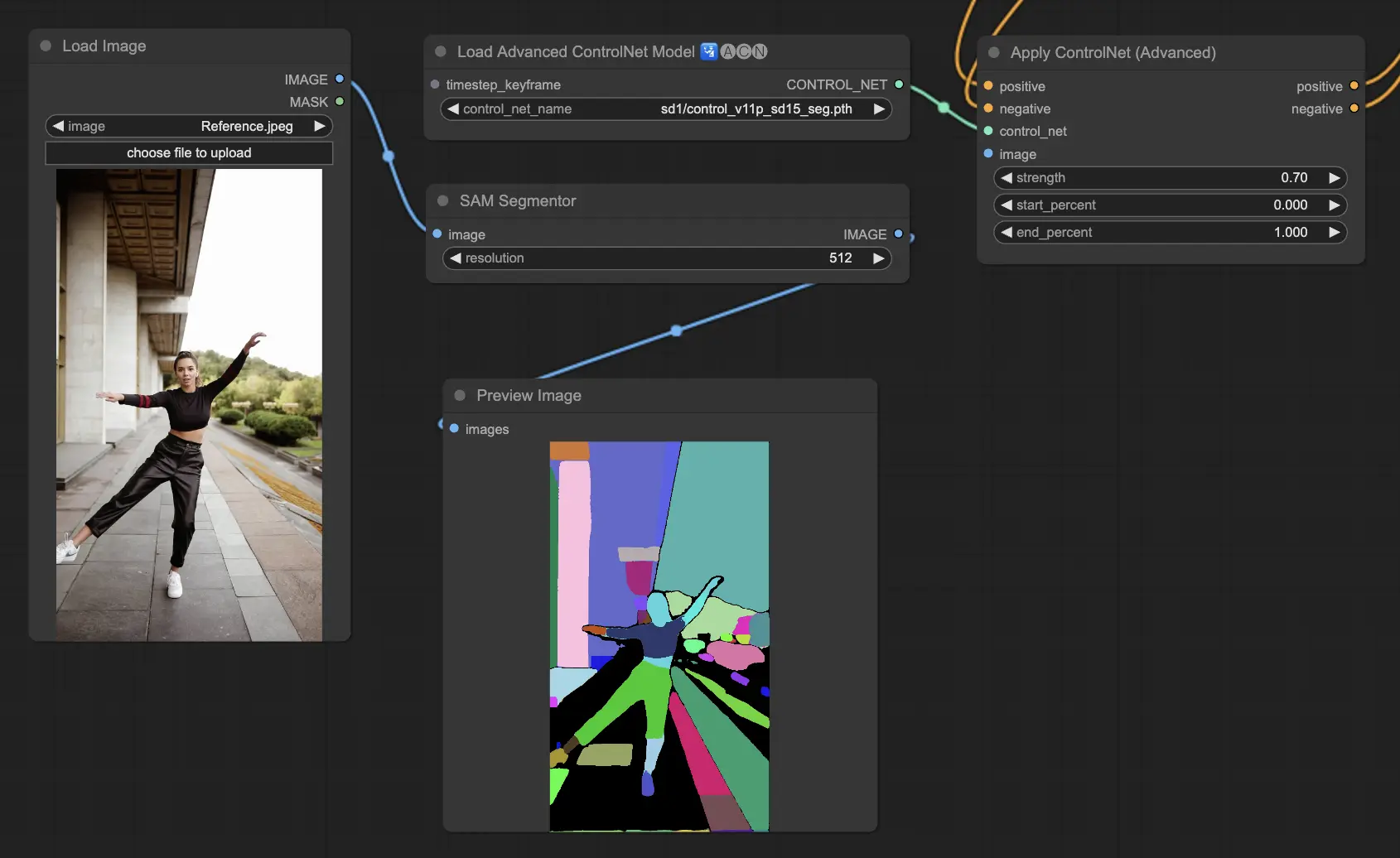
5.8. ComfyUI ControlNet Shuffle#
Shuffle 模型透過隨機改變輸入圖像的顏色方案與紋理,而不改變構圖,用於創造視覺變化或探索藝術變體。
每次輸出皆具唯一性,並受生成時種子值控制,適合藝術探索與視覺創新。
預處理器:Shuffle
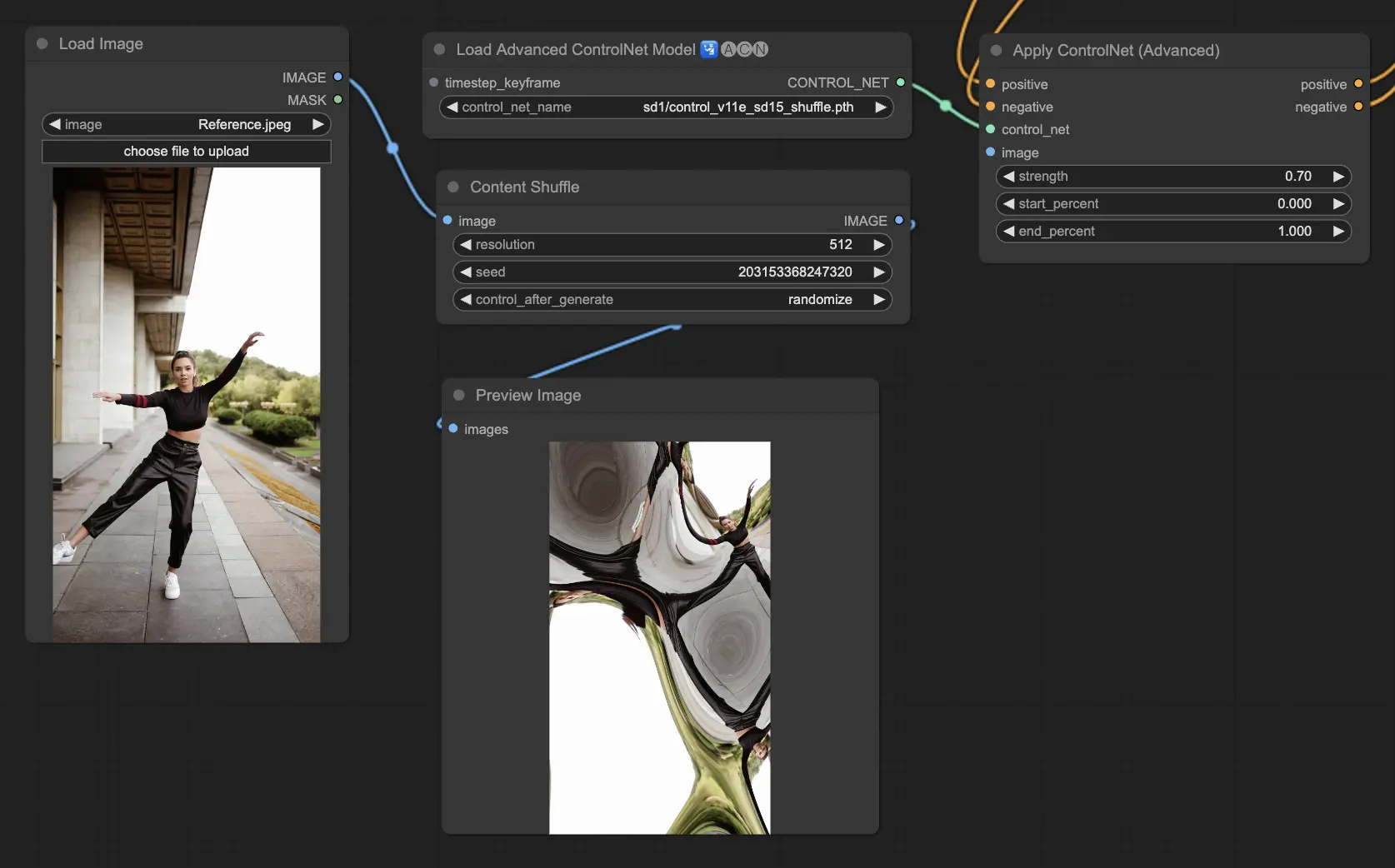
5.9. ComfyUI ControlNet Inpainting#
ControlNet 的 Inpainting 模型允許對圖像特定區域進行細部重建與更改,在保持整體一致性的同時做出局部變化。
使用方式如下:
- 利用遮罩工具(右鍵點擊圖像,選擇 "Open in MaskEditor")隔離欲修改區域。
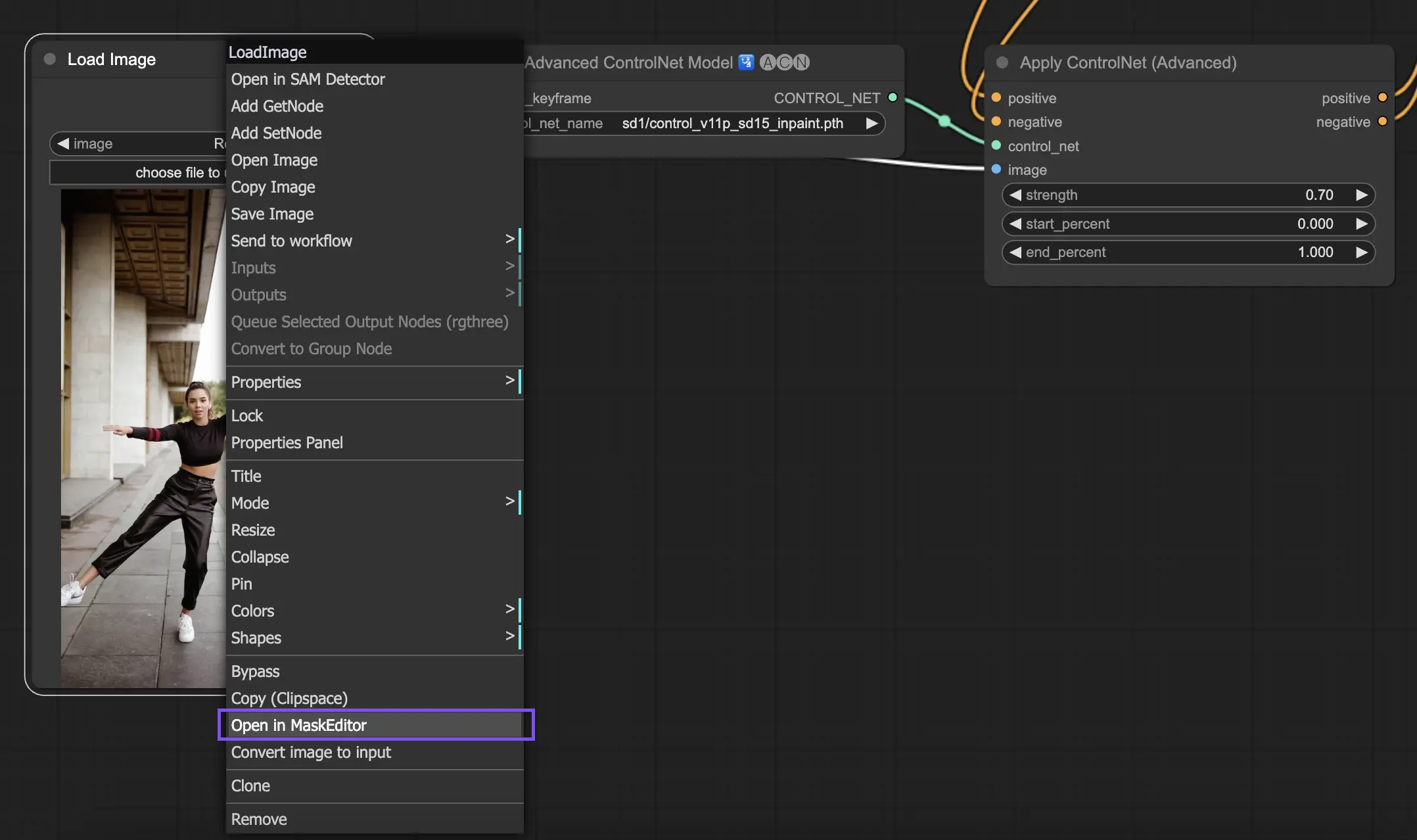
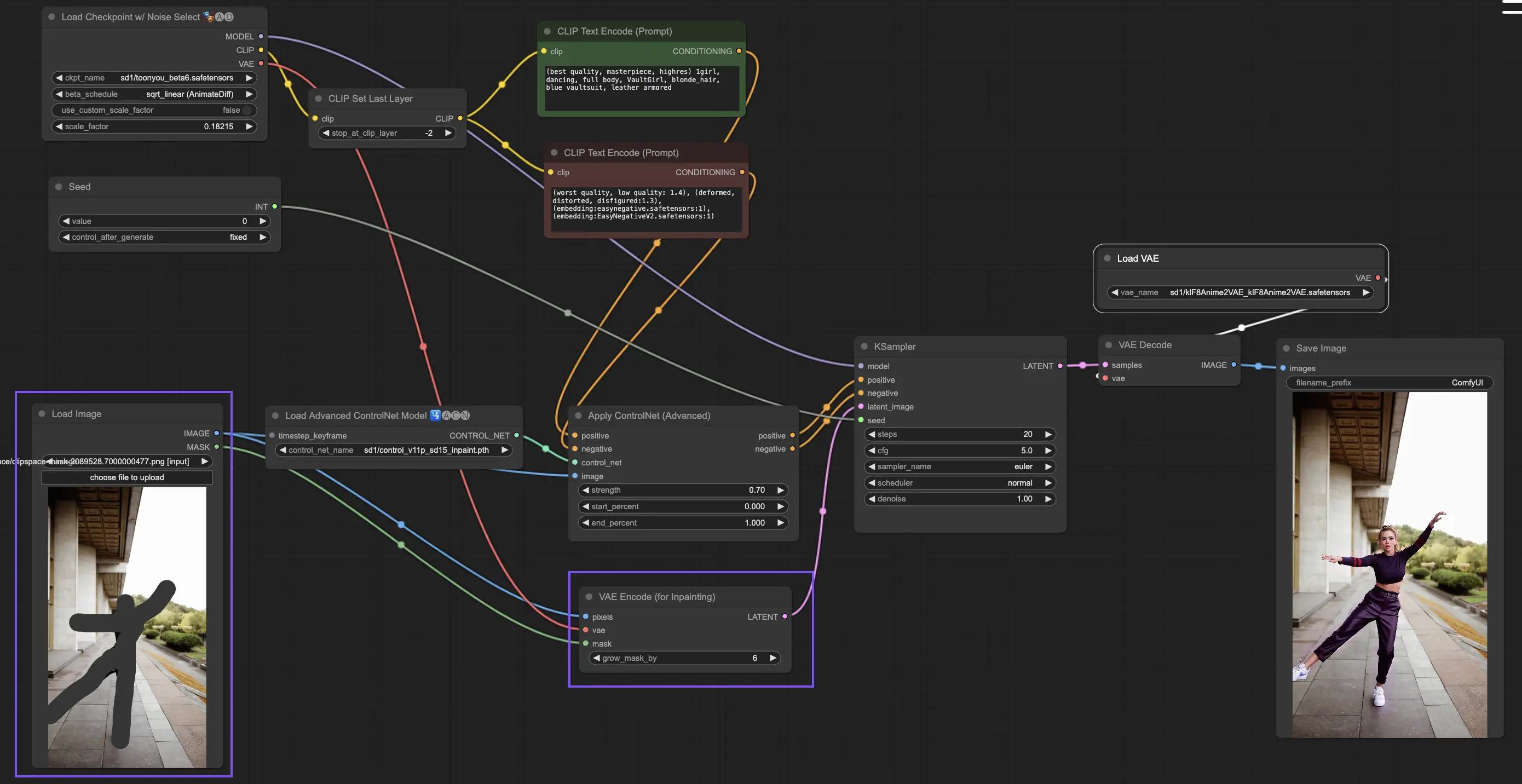
- 此模型不需要預處理器,而是直接將修改後的圖像透過 KSampler 導入潛在空間中進行推理。
這樣可以確保 ControlNet 僅專注於遮罩範圍內的生成,其餘部分保持不變。
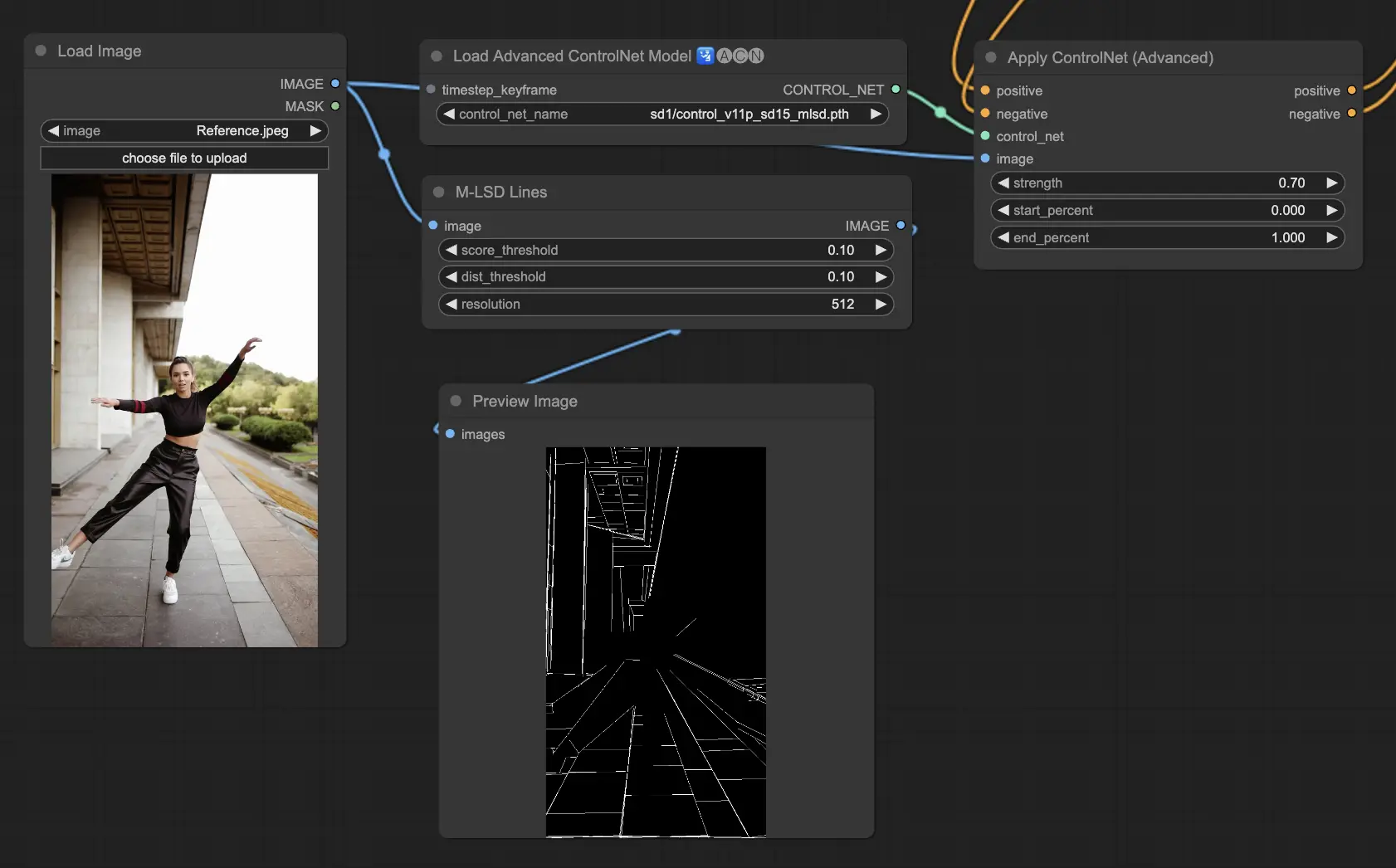
5.10. ComfyUI ControlNet MLSD#
M-LSD(Mobile Line Segment Detection)專為直線檢測設計,特別適合含有建築結構、室內佈局與幾何造型的圖像。
它可簡化場景至結構本質,有助於需要準確幾何視覺的創作。
預處理器:MLSD
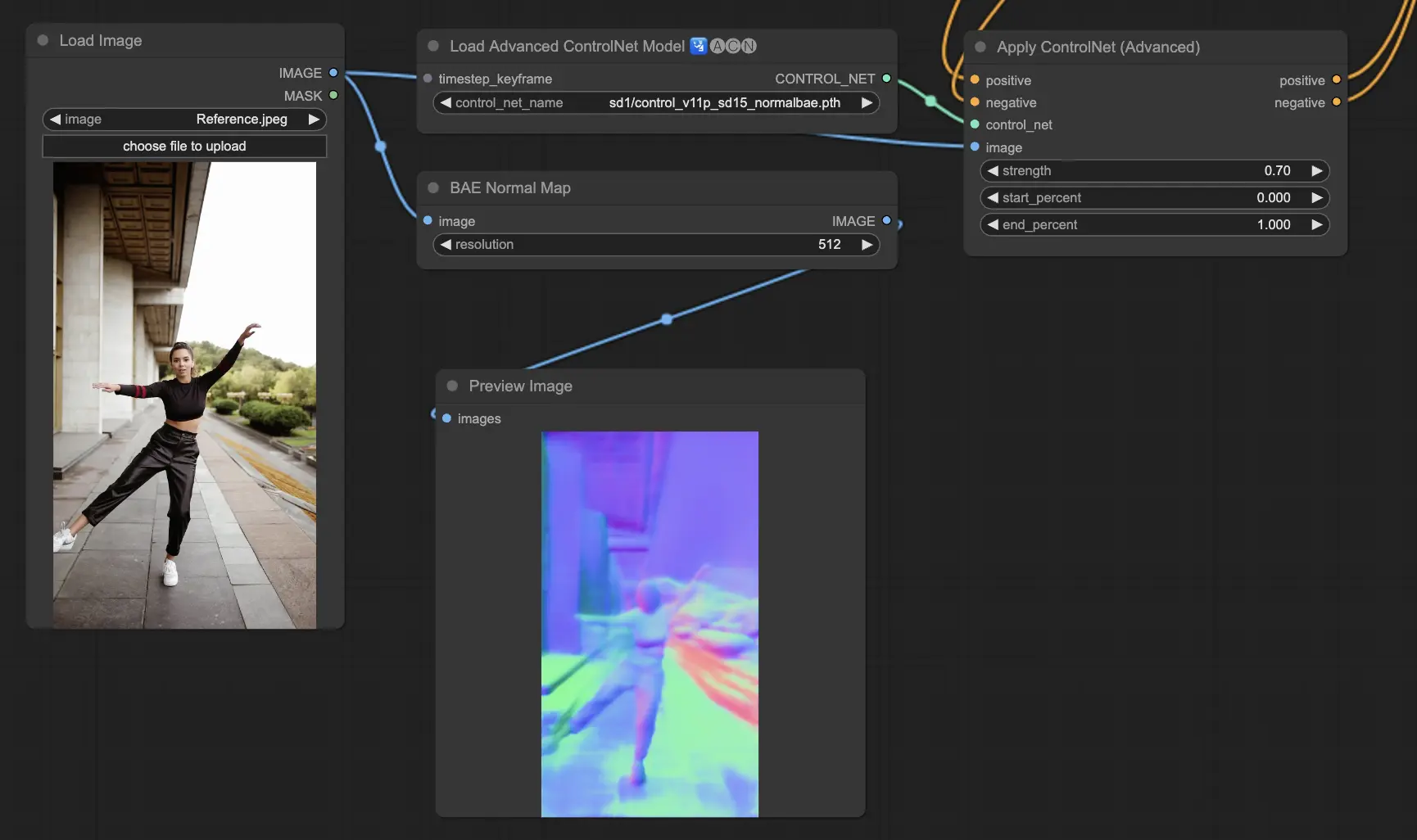
5.11. ComfyUI ControlNet Normalmaps#
Normalmap 模型透過模擬表面的法線方向(而非單靠顏色)來表現光影與材質細節,常見於 3D 模型或高擬真視覺模擬中。
- Normal BAE:使用法線不確定性方法,創造具物理邏輯的法線貼圖效果。
- Normal Midas:結合 Midas 深度圖轉換為法線貼圖,能在場景中準確模擬微觀紋理的光線效果。
預處理器:Normal BAE、Normal Midas
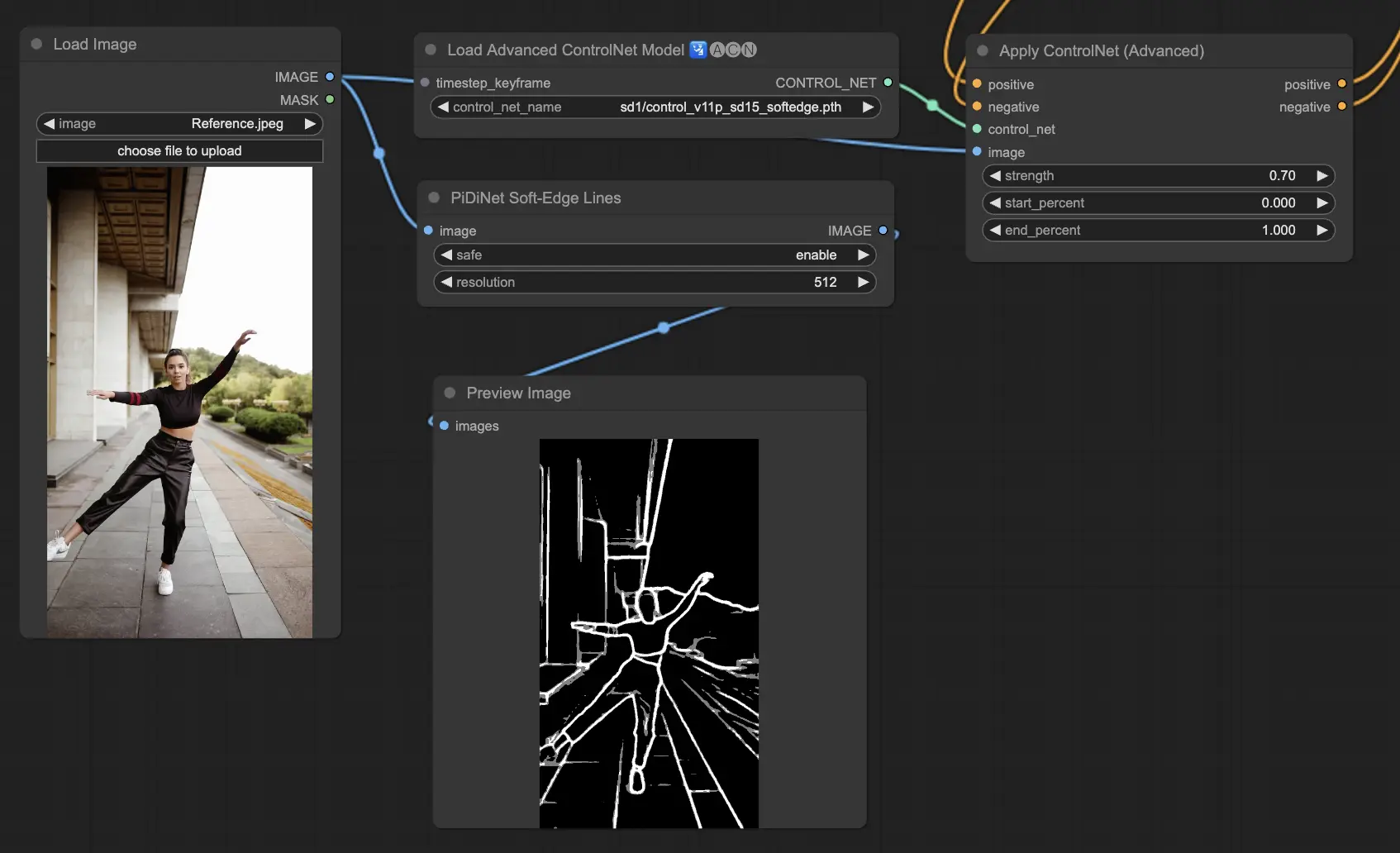
5.12. ComfyUI ControlNet Soft Edge#
Soft Edge 模型旨在產生邊緣更柔和的圖像,著重於細節掌控與自然視覺效果。它運用先進神經網絡進行高精度影像處理,實現無縫融合與更高創作自由度。
穩定性排序:SoftEdge_PIDI_safe > SoftEdge_HED_safe >> SoftEdge_PIDI > SoftEdge_HED
最大畫質排序:SoftEdge_HED > SoftEdge_PIDI > SoftEdge_HED_safe > SoftEdge_PIDI_safe
建議預設使用 SoftEdge_PIDI,它在多數場景下表現極佳。
預處理器:SoftEdge_PIDI、SoftEdge_PIDI_safe、SoftEdge_HED、SoftEdge_HED_safe
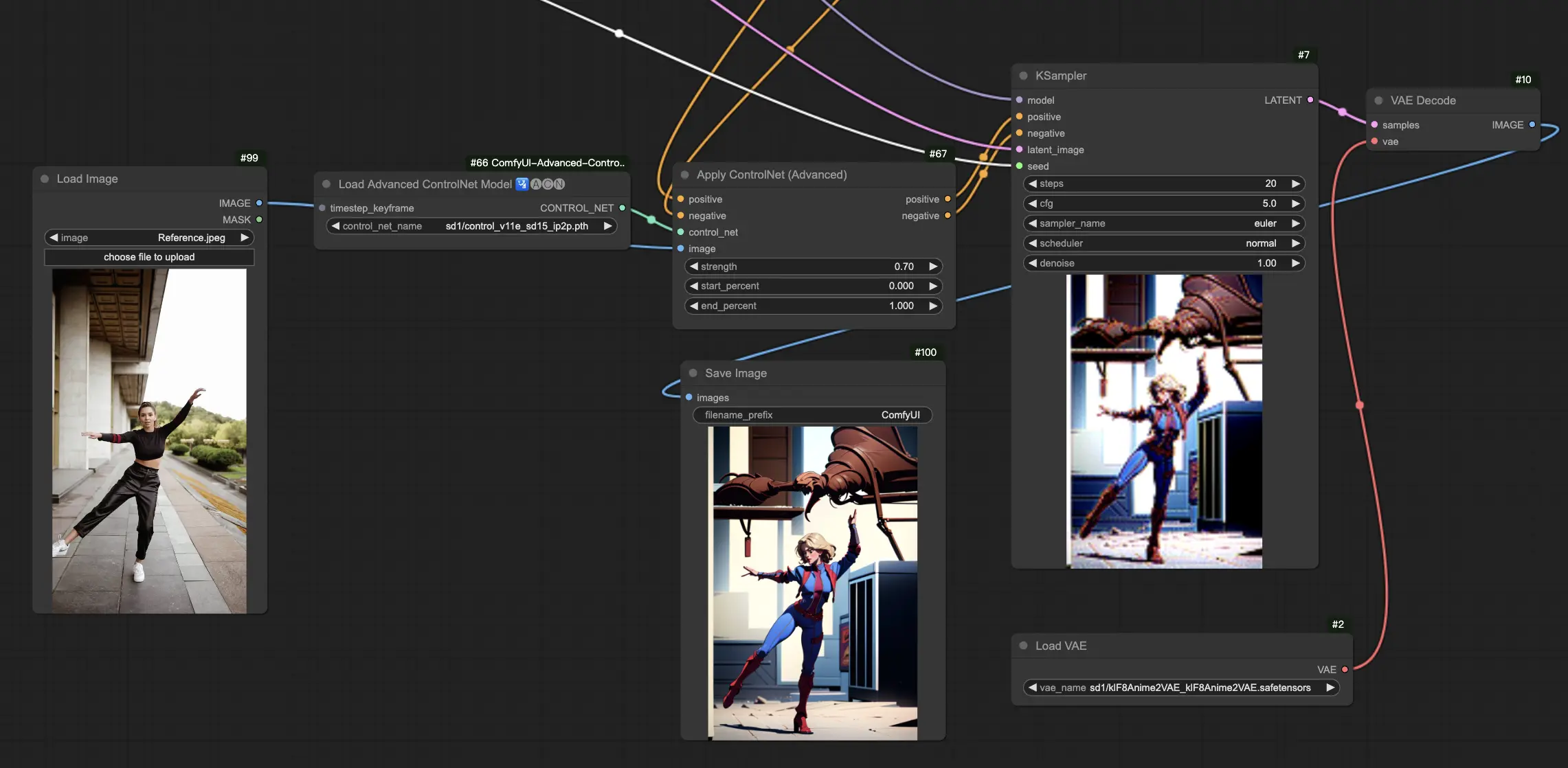
5.13. ComfyUI ControlNet IP2P (Instruct Pix2Pix)#
IP2P 模型(Instruct Pix2Pix)是 ControlNet 框架下的特別變體,專為圖像轉換設計,使用 Instruct Pix2Pix 數據集訓練。
與官方版本不同,ControlNet IP2P 在訓練中使用指令提示與描述提示的 50/50 混合,大幅提升模型靈活性與準確性。
5.14. ComfyUI T2I Adapter#
t2iadapter color:這個模型專為提升色彩再現與準確性設計,可協助生成更生動且貼合提示描述的色彩畫面,適合對色彩真實度要求較高的專案。
t2iadapter style:這個模型專注於藝術風格導引,可讓圖像生成結果呈現特定風格與美感,是融合傳統藝術與 AI 創作的重要工具。
5.15. 其他熱門模型:QRCode Monster 與 IP-Adapter#
這些模型將在單獨教學文章中進行深入探討,敬請期待!
6. 如何使用多個 ComfyUI ControlNet#
在 ComfyUI 中使用多個 ControlNet,需將不同模型以串接方式組合,達成更細緻的控制,例如同時調控姿勢(OpenPose)、輪廓(Canny)、風格與顏色等層面。
例如你可先應用 OpenPose 建立人體姿勢,接著加入 Canny 加強邊緣輪廓。每一層 ControlNet 負責不同轉換任務,讓整體影像在多個面向精細控制,實現更複雜與精確的創作。
✨✨✨ ComfyUI 線上體驗:立即探索 ControlNet 工作流程 ✨✨✨#
若你想親身體驗 ControlNet 工作流,歡迎使用下方的 ComfyUI 頁面,已預先載入所有所需節點與模型,免安裝即可無縫創作。