
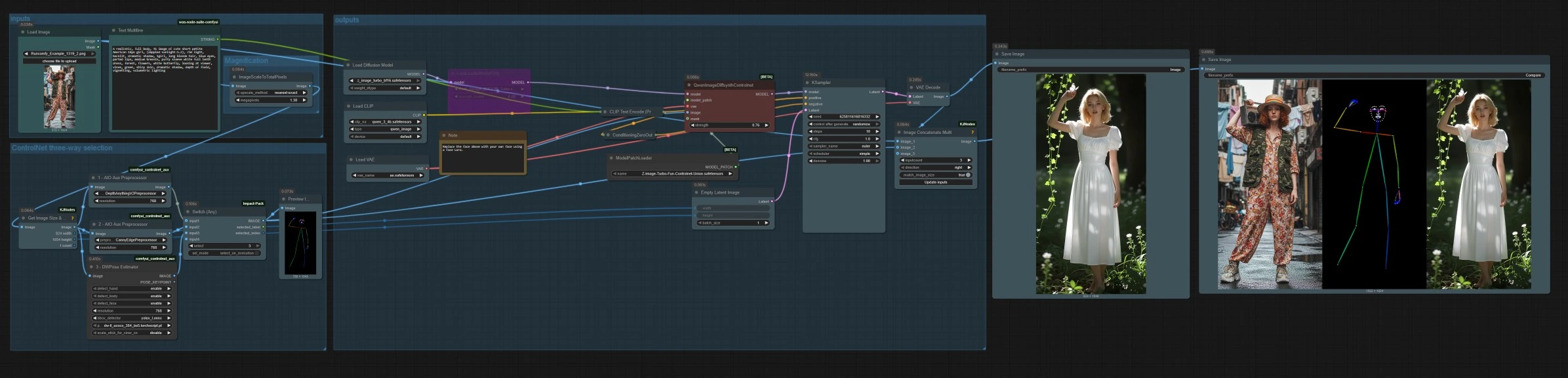








Z Image ControlNet 工作流程,用於在 ComfyUI 中的結構指導圖像生成#
此工作流程將 Z Image ControlNet 引入 ComfyUI,讓您可以使用參考圖像的精確結構來引導 Z‑Image Turbo。它將三種指導模式結合在一個圖中:深度、Canny 邊緣和人體姿勢,並允許您在它們之間切換以匹配您的任務。結果是快速、高品質的文本或圖像到圖像生成,佈局、姿勢和構圖在迭代時保持受控。
專為藝術家、概念設計師和佈局規劃者設計,該圖支持雙語提示和可選的 LoRA 風格。您可以獲得所選控制信號的清晰預覽,並自動比較條帶以評估深度、Canny 或姿勢與最終輸出的對比。
Comfyui Z Image ControlNet 工作流程中的關鍵模型#
- Z-Image Turbo 擴散模型 6B 參數。主要生成器,能夠從提示和控制信號中快速生成逼真的圖像。 alibaba-pai/Z-Image-Turbo
- Z Image ControlNet Union 補丁。為 Z-Image Turbo 添加多條件控制,並在一個模型補丁中啟用深度、邊緣和姿勢指導。 alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
- Depth Anything v2。產生用於深度模式結構指導的密集深度圖。 LiheYoung/Depth-Anything-V2 on GitHub
- DWPose。估計人體關鍵點和身體姿勢以進行姿勢指導生成。 IDEA-Research/DWPose
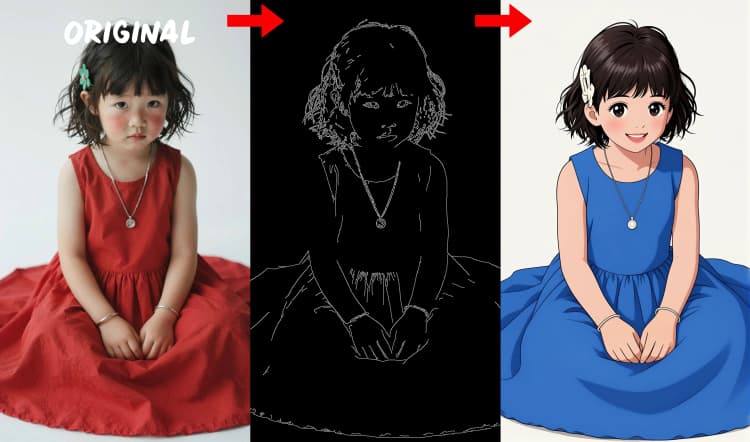
- Canny 邊緣檢測器。提取乾淨的線條藝術和邊界以進行佈局驅動的控制。
- ControlNet Aux 預處理器用於 ComfyUI。提供深度、邊緣和姿勢的統一包裝器,用於此圖。 comfyui_controlnet_aux
如何使用 Comfyui Z Image ControlNet 工作流程#
在高層次上,您加載或上傳參考圖像,選擇一個控制模式(深度、Canny 或姿勢),然後使用文本提示生成。該圖將參考圖像按比例縮放以進行高效採樣,構建匹配的長寬比的潛在圖像,並保存最終圖像及並排比較條帶。
輸入#
使用 LoadImage (#14) 選擇參考圖像。在 Text Multiline (#17) 中輸入您的文本提示,Z-Image 堆疊支持雙語提示。提示由 CLIPLoader (#2) 和 CLIPTextEncode (#4) 編碼。如果您更喜歡純粹的結構驅動圖像到圖像,可以將提示保持簡單,依賴選擇的控制信號。
ControlNet 三路選擇#
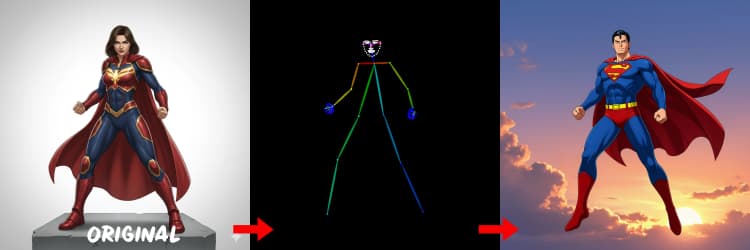
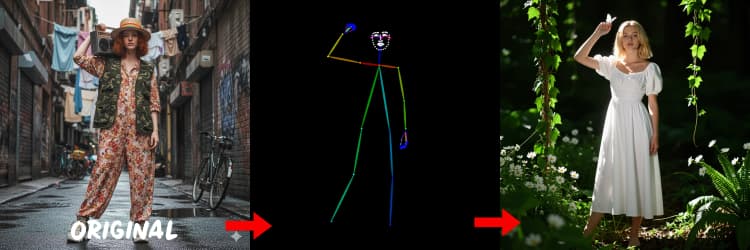
三個預處理器將您的參考圖像轉換為控制信號。AIO_Preprocessor (#45) 使用 Depth Anything v2 生成深度,AIO_Preprocessor (#46) 提取 Canny 邊緣,DWPreprocessor (#56) 估計全身姿勢。使用 ImpactSwitch (#58) 選擇哪個信號驅動 Z Image ControlNet,並檢查 PreviewImage (#43) 確認選定的控制圖。選擇深度時,您需要場景幾何,Canny 用於清晰的佈局或產品拍攝,姿勢用於角色工作。
OpenPose 提示: 1. 適合全身: 當您在提示中包含 "全身" 時,OpenPose 效果最佳(約 70-90% 準確率)。 2. 避免特寫: 面部的準確率顯著下降。對於特寫,請改用 Depth 或 Canny(低/中強度)。 3. 提示很重要: 提示對 ControlNet 影響很大。避免空提示以防止結果模糊。
放大#
ImageScaleToTotalPixels (#34) 將參考圖像調整到實用的工作分辨率,以平衡質量和速度。GetImageSizeAndCount (#35) 讀取縮放的大小並向前傳遞寬度和高度。EmptyLatentImage (#6) 創建一個潛在畫布,匹配您調整後輸入的長寬比,以保持構圖一致。
輸出#
QwenImageDiffsynthControlnet (#39) 將基本模型與 Z Image ControlNet 聯合補丁和選定的控制圖像融合,然後 KSampler (#7) 根據您的正面和負面條件生成結果。VAEDecode (#8) 將潛在圖像轉換為圖像。工作流程保存兩個輸出,SaveImage (#31) 寫入最終圖像,SaveImage (#42) 通過 ImageConcatMulti (#38) 寫入比較條帶,其中包括來源、控制圖和結果,以便快速質量檢查。
Comfyui Z Image ControlNet 工作流程中的關鍵節點#
ImpactSwitch (#58)#
選擇哪個控制圖像驅動生成深度、Canny 或姿勢。切換模式以比較每個約束如何塑造構圖和細節。在迭代佈局時使用它,快速測試哪種指導最適合您的目標。
QwenImageDiffsynthControlnet (#39)#
連接基本模型、Z Image ControlNet 聯合補丁、VAE 和所選控制信號。strength 參數決定模型如何嚴格遵循控制輸入與提示。對於緊密的佈局匹配,提高強度;對於更具創造性的變化,降低它。
AIO_Preprocessor (#45)#
運行 Depth Anything v2 管道以創建密集深度圖。提高分辨率以獲得更詳細的結構,或降低以獲得更快的預覽。非常適合建築場景、產品拍攝和幾何重要的景觀。
DWPreprocessor (#56)#
生成適合人和角色的姿勢圖。當肢體可見且未被嚴重遮擋時效果最佳。如果手或腿缺失,請嘗試使用更清晰的參考或不同的幀,顯示更完整的身體。
LoraLoaderModelOnly (#54)#
將可選的 LoRA 應用於基本模型,以獲得風格或身份提示。調整 strength_model 以溫和或強烈地混合 LoRA。您可以替換面部 LoRA 來個性化主題,或使用風格 LoRA 鎖定特定外觀。
KSampler (#7)#
使用您的提示和控制進行擴散採樣。調整 seed 以獲得可重複性,steps 以獲得精煉預算,cfg 以符合提示,denoise 以決定輸出偏離初始潛在圖像的程度。對於圖像到圖像的編輯,降低去噪以保留結構;更高的值允許更大的變化。
可選附加功能#
- 要緊密控制構圖,使用深度模式和乾淨、均勻照明的參考圖像;Canny 偏好強對比,姿勢偏好全身拍攝。
- 對於源圖像的細微編輯,保持適度去噪,並提高 ControlNet 強度以保持忠實的結構。
- 當您需要更多細節時,增加放大組中的目標像素,然後再次減少以獲得快速草稿。
- 使用比較輸出快速 A/B 測試深度與 Canny 與姿勢,並選擇最可靠的控制以適應您的主題。
- 用您自己的面部或風格 LoRA 替換示例 LoRA,以在不重新訓練的情況下納入身份或藝術指導。
致謝#
此工作流程實現並建立在以下作品和資源之上。我們對 Alibaba PAI 的 Z Image ControlNet 的貢獻和維護表示感謝。有關權威詳情,請參閱下面鏈接的原始文檔和存儲庫。
資源#
- Alibaba PAI/Z Image ControlNet
- Hugging Face: alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
注意:使用所引用的模型、數據集和代碼需遵循其作者和維護者提供的相應許可和條款。


