
SkyReels V3 ComfyUI:忠於身份的圖像、視頻和音頻轉視頻創作#
SkyReels V3 ComfyUI 是一個生產就緒的工作流程,將 SkyReels V3 多模態視頻模型引入 ComfyUI,使您可以為靜止圖像添加動畫、擴展現有鏡頭並構建具有精確唇形同步的音頻驅動說話頭像。它專為希望在靈活的節點圖中保持電影運動、強大主題身份和時間一致性的創作者而設計。
該工作流程附帶四條可獨立運行或鏈接的專注管道:圖像到視頻角色動畫、視頻到視頻續集、音頻到視頻說話頭像和故事流的下一鏡頭生成。每個路徑都包含明確的輸入點和合理的默認值,因此您可以快速插入您的資產並渲染高質量的 SkyReels V3 輸出。
注意 2X 大型及更大機器(R2V 工作流程): 在運行之前,請將
Patch Sage Attention KJ(#240)sage_attention設置為disabled。啟用它可能會觸發SM90 kernel is not available錯誤。
Comfyui SkyReels V3 ComfyUI 工作流程中的關鍵模型#
- 來自 WanVideo FP8 包的 SkyReels V3 視頻骨幹 (R2V, V2V Shot, A2V)。這些是處理身份感知運動、視頻續集和音頻條件唇形同步的核心生成器。請參閱 Hugging Face 上 WanVideo 包中的 SkyReels V3 權重 here。
- 用於圖像指導和參考嵌入的 OpenCLIP Vision ViT 模型。它們提供強大的視覺特徵,有助於在幀之間保持外觀和風格。項目頁面:open_clip。
- 用於提示理解的 UMT5 文本編碼器。它提供豐富的語言條件以引導風格、場景和動作。倉庫:umt5。
- 用於唇形同步和音頻分析的 Wav2Vec2 語音特徵。中國基變體開箱即用,類似的英語變體也適用。模型卡:TencentGameMate/chinese-wav2vec2-base。
- 用於語音轉文本的 Qwen3‑ASR‑1.7B。用於轉錄參考音頻並引導語音克隆 TTS 提示。模型卡:Qwen/Qwen3-ASR-1.7B。
- 用於聲音分離的 MelBandRoFormer。在嵌入唇形同步之前,當您需要乾淨的語音軌道時非常有用。模型卡:Kijai/MelBandRoFormer_comfy。
- 用於鏡頭感知提示生成的 MiniCPM‑V。它分析先前的畫面並提出下一鏡頭以保持故事連貫性。模型中心:OpenBMB/MiniCPM-V。
如何使用 Comfyui SkyReels V3 ComfyUI 工作流程#
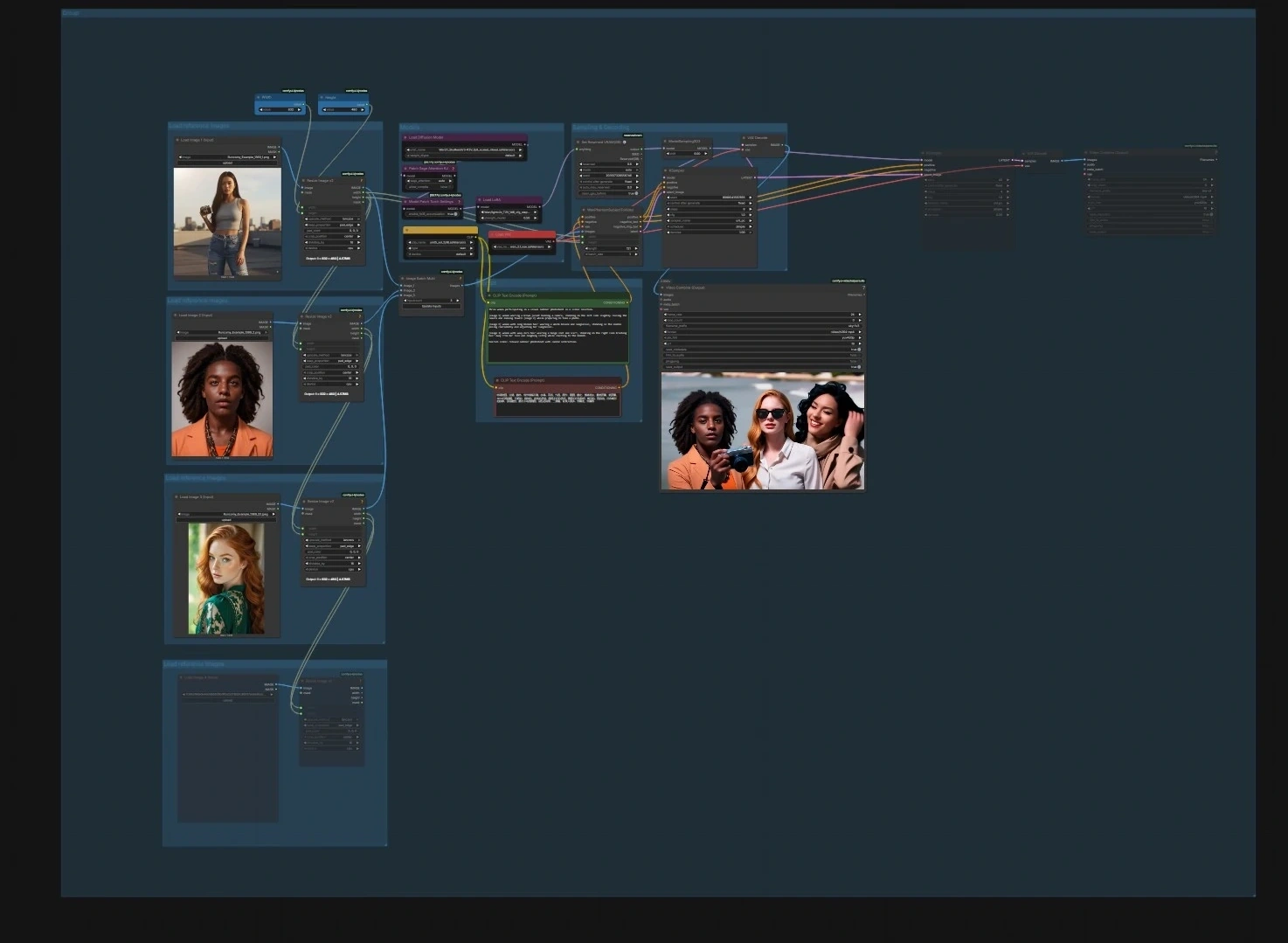
圖表分為四條管道。您可以單獨運行任何一個或按順序運行以構建更長的編輯。
圖像到視頻角色動畫#
- 模型。使用
UNETLoader(#241)、CLIPLoader(#242) 和VAELoader(#194) 在模型組中加載 UNet、CLIP 和 VAE。模型補丁節點PathchSageAttentionKJ(#240) 和ModelPatchTorchSettings(#239) 優化注意力和數學設置,而LoraLoaderModelOnly(#250) 讓您可選地將風格或運動 LoRA 混入 SkyReels 模型。 - 加載參考圖像。使用三個 "加載參考圖像" 組導入 1–3 個肖像或姿勢。調整大小助手
ImageResizeKJv2(#291, #298, #299, #304) 對齊縱橫比並批量處理它們;更乾淨的身份照片可以產生更穩定的結果。 - 提示。在提示組中使用
CLIPTextEncode(#6) 輸入場景和動作文本,並使用可選的負文本編碼器CLIPTextEncode(#7) 來排除不需要的特徵。保持語言簡潔,專注於動作和構圖。 - 取樣和解碼。
WanPhantomSubjectToVideo(#249) 將您的參考和提示融合成一個身份感知的潛在,該潛在通過ModelSamplingSD3(#48) 餵給KSampler(#149)。從VAEDecode(#264) 解碼的幀由VHS_VideoCombine(#280) 打包成電影;在此設置目標幀速率和文件格式。
視頻到視頻擴展循環#
- 輸入視頻和設置。使用
VHS_LoadVideo(#329) 導入您的源剪輯。使用整數助手 “Number of Extend” (#342) 和 “Overlapping Frames” (#341) 設置要生成的額外段數和段之間的重疊量。ImageResizeKJv2(#327) 標準化取樣器的分辨率。 - 循環取樣擴展視頻。循環對
easy forLoopStart(#331) 和easy forLoopEnd(#332) 在窗口中遍歷剪輯以穩定過渡。每個窗口都由WanVideoEncode(#326) 編碼,通過WanVideoEmptyEmbeds(#328) 接收中性或控制嵌入,並由WanVideoSampler(#320) 從WanVideoModelLoader(#319) 去噪。幀由WanVideoDecode(#321) 解碼,並可使用VHS_VideoCombine(#322, #335) 預覽或保存。 - 性能助手。
WanVideoTorchCompileSettings(#323) 和WanVideoBlockSwap(#325) 為更長或更高分辨率的運行啟用編譯和內存技巧。
音頻到視頻說話頭像#
- 1 – 創建音頻。您可以使用
FB_Qwen3TTSVoiceClonePrompt(#416) 和FB_Qwen3TTSVoiceClone(#412) 生成語音克隆的語音軌道,或使用LoadAudio(#417) 加載任何預錄語音。Qwen3ASRLoader(#414) 加上Qwen3ASRTranscribe(#413) 幫助您從參考剪輯中提取文本以種子 TTS 提示(如果需要)。 - 2 – 音頻特徵。
DownloadAndLoadWav2VecModel(#348) 將MultiTalkWav2VecEmbeds(#350) 餵給您創建的唇形運動嵌入;長度與音頻對齊,並可用PreviewAudio(#422) 預覽。使用Any Switch (rgthree)(#435) 選擇 TTS 輸出或導入文件作為驅動軌道。 - 3 – 輸入圖像。在 “3 - 輸入圖像” 組中加載說話的面孔,並使用
ImageResizeKJv2(#370) 調整其大小。乾淨、正面的肖像,光線一致效果最佳。 - 參考視頻生成。首先,使用
WanVideoImageToVideoEncode(#392) 從靜止圖像創建一個短的視覺錨點。來自CLIPVisionLoader(#352) 和WanVideoClipVisionEncode(#351) 的 CLIP-Vision 特徵穩定身份跨越下一階段;在取樣設置組中準備調度器WanVideoSchedulerv2(#385)。 - 生成音頻唇形同步。
WanVideoImageToVideoSkyreelsv3_audio(#383) 將開始圖像、可選的參考幀和 CLIP-Vision 嵌入合併成圖像條件。然後WanVideoSamplerv2(#384) 使用 SkyReels A2V 模型去噪,而WanVideoSamplerExtraArgs(#386) 則注入MultiTalk唇形同步嵌入以獲得準確的口形。WanVideoPassImagesFromSamples(#381) 將解碼幀流到VHS_VideoCombine(#346),在那裡您的音頻與最終視頻合併。
視頻到視頻下一鏡頭生成#
- 視頻幀預處理。使用
VHS_LoadVideo(#443) 導入上一鏡頭,並通過ImageResizeKJv2(#441) 調整其大小。GetImageRangeFromBatch(#445) 選擇一個上下文片段,WanVideoEncode(#440) 將其轉換為潛在;WanVideoEmptyEmbeds(#442) 準備條件窗口。 - 自動視頻提示。
CreateVideo(#450) 從上下文幀組裝一個緊湊的代理剪輯,AILab_MiniCPM_V_Advanced(#449) 分析它以起草下一鏡頭提示。在ShowText|pysssss(#447) 中檢查或細化草案,然後在取樣前將其嵌入WanVideoTextEncodeCached。 - 模型和取樣。使用
WanVideoModelLoader(#436) 和WanVideoVAELoader(#438) 加載 V2V Shot 模型;可選的WanVideoBlockSwap(#439) 處理 VRAM。WanVideoSampler(#451) 生成續集,WanVideoDecode(#437) 渲染幀,VHS_VideoCombine(#446) 輸出最終鏡頭。這條 SkyReels V3 ComfyUI 路徑非常適合故事板和預覽,其中每個新剪輯都應尊重上一個。
Comfyui SkyReels V3 ComfyUI 工作流程中的關鍵節點#
WanPhantomSubjectToVideo(#249)。從您的批量參考圖像加上文本提示構建一個身份感知的潛在,然後驅動取樣器。調整引用的數量和多樣性以平衡相似鎖定與創意運動;保持提供給它的調整節點一致以避免漂移。參考:WanVideo Wrapper 在 GitHub 上包含實施說明和預期輸入 ComfyUI‑WanVideoWrapper。WanVideoImageToVideoEncode(#392)。將靜止圖像編碼為穩定的鏡頭種子,並可選地混合 CLIP-Vision 指導以獲得姿勢和構圖。在音頻驅動階段之前使用它來創建錨點幀,以便身份和相機設置在各管道中保持一致。包裝器文檔:ComfyUI‑WanVideoWrapper。WanVideoImageToVideoSkyreelsv3_audio(#383)。準備專為 A2V 取樣器量身定制的圖像嵌入,並合併可選的參考視頻幀。確保其寬度和高度與取樣器路徑匹配;將其與WanVideoSamplerv2和MultiTalkWav2VecEmbeds配對以獲得精確的唇形同步。WanVideoSamplerv2(#384, #387)。SkyReels V3 的主要去噪器,接受圖像和文本嵌入加上調度設置。WanVideoSamplerExtraArgs節點 (#386, #409) 是注入唇形同步、循環或上下文特徵的地方;在 A2V 和 I2V 模型之間切換時保持這些連接。實施細節:ComfyUI‑WanVideoWrapper。MultiTalkWav2VecEmbeds(#350)。將語音轉換為驅動口形運動的時間對齊嵌入。匹配預期的幀預算並確保乾淨的語音顯著提高音素準確性。Wav2Vec 參考模型:TencentGameMate/chinese-wav2vec2-base。AILab_MiniCPM_V_Advanced(#449)。分析上一鏡頭並起草角色、背景、動作、情緒和照明的結構化提示。使用此功能在使用 V2V 下一鏡頭路徑時保持敘述連續性;生成的文本流入WanVideoTextEncodeCached。模型家族:OpenBMB/MiniCPM-V。
可選額外功能#
- 保持圖像、視頻和取樣器分辨率在連接的節點之間一致,以避免縱橫比變形和身份閃爍。
- 對於更長的擴展,增加 V2V 擴展循環中的窗口重疊以平滑段之間的過渡。
- 如果 GPU 記憶體緊張,則保持啟用保留的 VRAM 節點 (
ReservedVRAMSetter(#312, #448)) 並在取樣前使用編譯設置塊。 - 當說話頭像不合拍時,優先使用乾淨的語音或在創建
MultiTalk嵌入之前使用 MelBandRoFormer 分離聲音。 - 最終交付設置,如幀速率、像素格式和 CRF,皆由
VHS_VideoCombine輸出節點控制;匹配您的來源幀速率以進行無縫編輯。
此 README 涵蓋完整的 SkyReels V3 ComfyUI 圖表,因此您可以選擇適合您項目的路徑,根據需要將它們結合起來,並以最小的試錯渲染出一致的、故事準備好的視頻。
致謝#
此工作流程實施並建立在以下作品和資源之上。我們感謝 @Benji’s AI Playground 和 SkyReels 提供的 SkyReels V3 ComfyUI 工作流程的貢獻和維護。欲了解權威詳情,請參閱下方鏈接的原始文檔和倉庫。
資源#
- SkyReels/V3 ComfyUI 來源
注意:引用的模型、數據集和代碼的使用受其作者和維護者提供的相應許可json
和條款的約束。