






Nunchaku Qwen Image 多圖像編輯和合成用於 ComfyUI#
Nunchaku Qwen Image 是一個提示驅動的多圖像編輯和合成工作流程,用於 ComfyUI。它接受最多三個參考圖像,讓您指定它們應如何融合或轉換,並產生由自然語言引導的連貫結果。典型用例包括合併主題、替換背景或從一張圖像轉移風格和細節到另一張圖像。
基於 Qwen 圖像系列,這個工作流程讓藝術家、設計師和創作者在保持快速和可預測的同時擁有精確的控制。它還包括單圖像編輯路線和純文本到圖像路線,因此您可以在一個 Nunchaku Qwen Image 管道中生成、精煉和合成。
注意:請選擇 Medium 到 2XLarge 範圍內的機器類型。使用 2XLarge Plus 或 3XLarge 機器類型不受支持,將導致運行失敗。
Comfyui Nunchaku Qwen Image 工作流程中的關鍵模型#
- Nunchaku Qwen Image Edit 2509。針對提示引導的圖像編輯和屬性轉移優化的編輯調諧擴散/DiT 權重。擅長局部編輯、物件交換和背景變更。Model card
- Nunchaku Qwen Image (base)。文本到圖像分支使用的基礎生成器,用於無源照片的創意合成。Model card
- Qwen2.5‑VL 7B 文本編碼器。多模態語言模型,解釋提示並將其與視覺特徵對齊,用於編輯和生成。Model page
- Qwen Image VAE。用於將源圖像編碼為潛在並以忠實的顏色和細節解碼最終結果的變分自編碼器。Assets
如何使用 Comfyui Nunchaku Qwen Image 工作流程#
此圖包含三個獨立路線,分享相同的視覺語言和取樣邏輯。根據您是編輯多張圖像、精煉單張圖像還是從文本生成,選擇一個分支一次使用。
Nunchaku‑qwen‑image‑edit‑2509 (多圖像編輯和合成)#
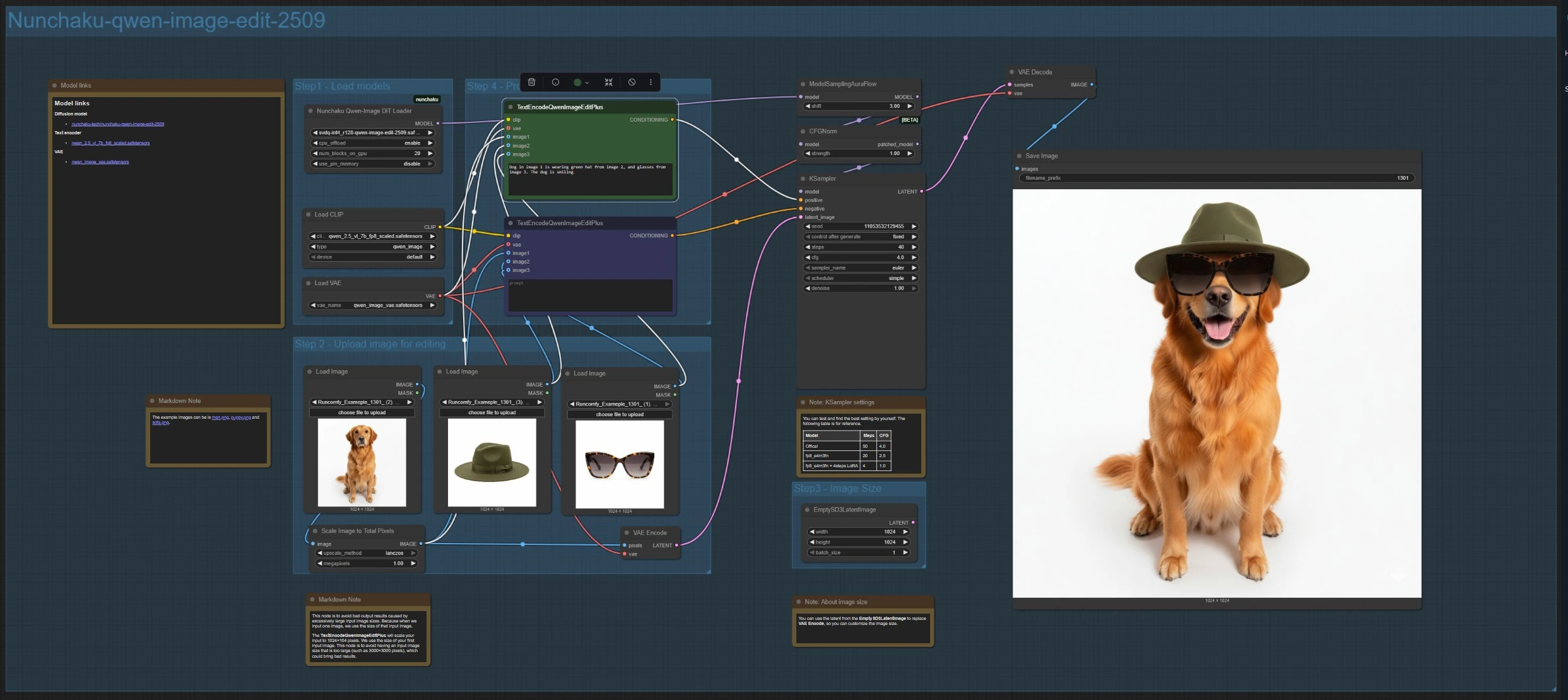
此分支加載編輯模型 NunchakuQwenImageDiTLoader (#115),通過 ModelSamplingAuraFlow (#66) 和 CFGNorm (#75) 路由,然後使用 KSampler (#3) 合成。使用 LoadImage (#78, #106, #108) 上傳最多三張圖像。主要參考由 VAEEncode (#88) 編碼以設置畫布,ImageScaleToTotalPixels (#93) 保持輸入在穩定的尺寸範圍內。
在 TextEncodeQwenImageEditPlus (#111) 中寫下您的指令,如有需要,將刪除或約束放在配對的 TextEncodeQwenImageEditPlus (#110) 中。明確引用來源,例如:“圖像 1 中的狗戴著圖像 2 的綠帽子和圖像 3 的眼鏡。”若需自定義輸出尺寸,您可以用 EmptySD3LatentImage (#112) 替換編碼的潛在。結果由 VAEDecode (#8) 解碼並使用 SaveImage (#60) 保存。
Nunchaku‑qwen‑image‑edit (單圖像精煉)#
當您需要對單張圖像進行目標清理、背景變更或風格調整時,選擇此選項。模型由 NunchakuQwenImageDiTLoader (#120) 加載,經 ModelSamplingAuraFlow (#125) 和 CFGNorm (#123) 調整,並由 KSampler (#127) 取樣。使用 LoadImage (#129) 導入您的照片;它由 ImageScaleToTotalPixels (#130) 正規化並由 VAEEncode (#131) 編碼。
在 TextEncodeQwenImageEdit (#121) 中提供您的指令,並在 TextEncodeQwenImageEdit (#122) 中提供可選的反引導以保留或移除元素。此分支由 VAEDecode (#124) 解碼,並通過 SaveImage (#128) 寫入文件。
Nunchaku‑qwen‑image (文本到圖像)#
使用此分支從頭創建新圖像,使用基礎模型。NunchakuQwenImageDiTLoader (#146) 提供給 ModelSamplingAuraFlow (#138)。在 CLIPTextEncode (#143) 和 CLIPTextEncode (#137) 中輸入您的正面和反面提示。設置您的畫布使用 EmptySD3LatentImage (#136),然後用 KSampler (#141) 生成,使用 VAEDecode (#142) 解碼,並用 SaveImage (#147) 保存。
Comfyui Nunchaku Qwen Image 工作流程中的關鍵節點#
NunchakuQwenImageDiTLoader (#115) 加載由分支使用的 Qwen 圖像權重和變體。選擇用於照片引導編輯的編輯模型或用於文本到圖像的基礎模型。當 VRAM 允許時,更高精度或更高解析度的變體可以提供更多細節;輕量變體優先速度。
TextEncodeQwenImageEditPlus (#111) 通過解析您的指令並將其綁定至最多三個參考,驅動多圖像編輯。保持指令明確,說明哪張圖像貢獻了哪個屬性。使用簡潔的措辭並避免衝突目標以保持編輯集中。
TextEncodeQwenImageEditPlus (#110) 作為多圖像分支的配對負面或約束編碼器。使用它排除您不想出現的物件、風格或人工品。這通常有助於在移除 UI 覆蓋或不需要的道具時保持構圖。
TextEncodeQwenImageEdit (#121) 單圖像編輯分支的正面指令。用清晰的語言描述期望的結果、表面特質和構圖。目標是用一到三句話指定場景和變更。
TextEncodeQwenImageEdit (#122) 單圖像編輯分支的負面或約束提示。列出要避免的項目或特徵,或描述要從源圖像中移除的元素。這對清除流浪文本、標誌或界面元素很有用。
ImageScaleToTotalPixels (#93) 通過縮放到目標總像素數來防止過大的輸入破壞結果。使用它來在合成之前協調不同來源的解析度。如果您注意到來源之間的清晰度不一致,請在此處將它們的有效大小拉得更近。
ModelSamplingAuraFlow (#66) 應用經過 Qwen 圖像模型調整的 DiT/流匹配取樣計劃。如果輸出看起來暗淡、模糊或缺乏結構,增加計劃的偏移以穩定全局色調;如果看起來平淡,減少偏移以追求額外細節。
KSampler (#3) 平衡速度、保真度和隨機多樣性的主要取樣器。調整步驟和指導比例以獲得一致性與創造性,選擇取樣方法,並在需要精確再現性時鎖定種子。
CFGNorm (#75) 正規化無分類器指導,以減少在更高指導比例下的過飽和或對比度爆炸。保持在提供的路徑中;它幫助在您迭代提示時保持穩定的顏色和曝光。
可選附加功能#
- 為了獲得最佳多圖像結果,選擇具有相似透視和照明的來源;Nunchaku Qwen Image 編輯模型然後專注於內容而不是修正幾何。
- 按順序參考來源(“圖像 1”,“圖像 2”,“圖像 3”),並明確說明哪些屬性轉移到哪裡。
- 當輸出偏暗或模糊時,將
ModelSamplingAuraFlow偏移向上調整;當您需要額外紋理時,嘗試稍微降低偏移。 - 要設置特定解析度,請在您使用的分支中用
EmptySD3LatentImage替換編碼的潛在。 - 使用負面提示在您投入詳細風格之前移除 UI 文本、水印或不需要的物件;這樣可以從一開始就保持 Nunchaku Qwen Image 編輯的清潔。
致謝#
此工作流程實現並建立在以下作品和資源的基礎上。我們對 Nunchaku 的 Qwen-Image 工作流程(ComfyUI-nunchaku)的貢獻和維護表示感謝。欲了解權威詳情,請參閱下方鏈接的原始文檔和存儲庫。
資源#
- Nunchaku/Qwen-Image
- GitHub: nunchaku-tech/ComfyUI-nunchaku
- Hugging Face: nunchaku-tech/nunchaku-qwen-image
- arXiv: SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
- Docs / Release Notes: Nunchaku Qwen Image Source
注意:引用的模型、數據集和代碼的使用受其作者和維護者提供的各自許可和條款約束。



