
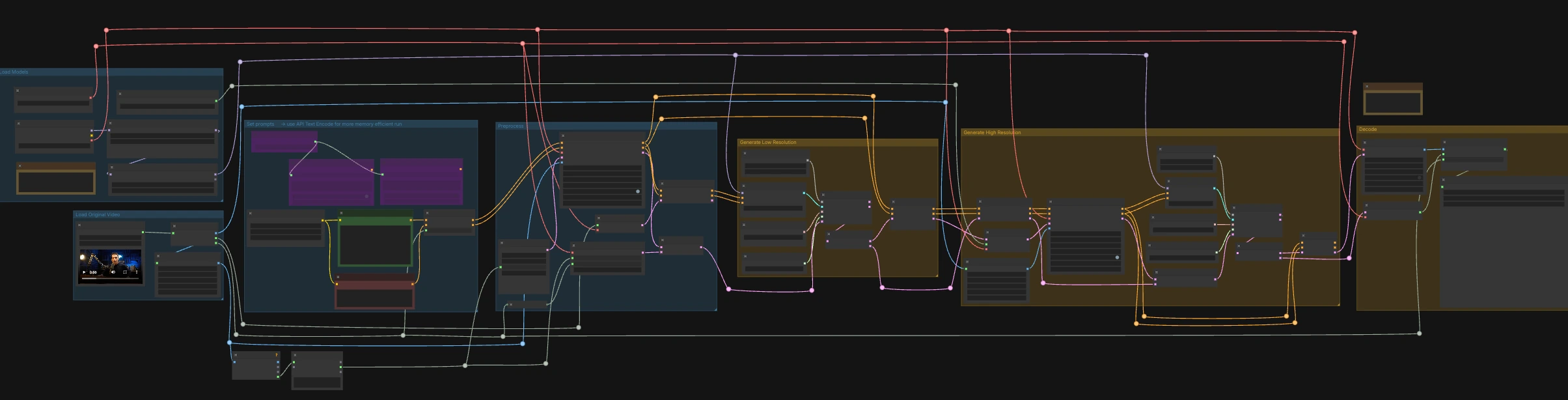
LTX-2.3 ICLoRA LipDub for ComfyUI#
LTX-2.3 ICLoRA LipDub 是一個雙通道的影片和音頻控制的 ComfyUI 工作流程,在保持身份和運動一致的情況下,為說話者配音。它結合了 Lightricks LTX-2.3 文本和影片條件與 LipDub IC-LoRA,精確地將嘴部運動與提供的語音對齊,然後在更高解析度下細化結果以獲得清晰的細節。圖表為 RunComfy 準備了標準化的輸入/輸出名稱,因此您可以可靠地替換媒體和重複運行。
這個 ComfyUI LTX-2.3 ICLoRA LipDub 工作流程非常適合需要多語言配音、重述或類似 ADR 修正的創作者,同時保留原始表演。提供已包含目標語音的來源影片,描述場景和人物應說的話,工作流程將合成同步的視覺和音頻成為完成的剪輯。
Comfyui LTX-2.3 ICLoRA LipDub 工作流程中的關鍵模型#
- LTX-2.3 22B 基本影片模型。生成影片的基礎擴散模型,決定提示如何引導外觀、運動和風格。
- LTX-2.3 IC-LoRA LipDub。專門用於唇形配音的 LoRA,將模型條件化以遵循提供的語音並將嘴形對齊到音素,同時保持身份和頭部運動。Model card
- LTX-2.3 Audio VAE。將輸入語音編碼為可注入文本條件的音頻潛在向量,然後解碼回波形,確保時間與幀保持同步。
- LTX-2.3 空間升頻器 x2。在高解析度細化通過前,將影片潛在向量升級到更高的空間解析度,改善紋理而不改變運動。
- LTX-2.3 Distilled LoRA (384)。一種強化的 LoRA,用於增強基本檢查點的細節和時間穩定性,而不過度適應參考幀。
如何使用 Comfyui LTX-2.3 ICLoRA LipDub 工作流程#
此工作流程分為兩個協調階段運行:低解析度通過以鎖定時間和唇形到音頻,然後是高解析度通過以升級和細化細節,同時保持同步。首先加載已包含所需語音的來源影片,然後寫下您希望人物說的文本行。
加載原始影片#
LoadVideo (#5002) 節點導入嵌入音頻的來源剪輯。GetVideoComponents (#5010) 提取幀、音頻和幀速率;幀速率在整個圖表中共享,因此影片和音頻保持對齊。兩個調整器,Resize Image/Mask (s1 size) (#5009) 和 Resize Image/Mask (s2 size) (#5003),準備低解析度和高解析度通過的工作圖像流。幀數測量並四捨五入以便於採樣器友好的長度,因此解碼保持穩定。
加載模型#
CheckpointLoaderSimple (#5017) 加載 LTX-2.3 22B 基本模型和 VAE 用於整個圖表。兩個加載器,LoraLoaderModelOnly (#5018) 和 LTXICLoRALoaderModelOnly (#5012),在基本模型上添加蒸餾 LoRA 和 IC-LoRA LipDub,使生成器遵循語音,同時保持身份。LTXVAudioVAELoader (#4010) 提供音頻 VAE 用於編碼/解碼音軌。IC-LoRA 加載器的 latent_downscale_factor 輸出在此故意未使用,因為 LipDub 訓練假設全解析度參考幀,與附帶的說明相符。
設置提示#
在 CLIP Text Encode (Positive Prompt) (#2483) 中寫下您的場景描述和精確的講話行。使用 CLIP Text Encode (Negative Prompt) (#2612) 來最小化不需要的特徵或工件。這些被輸入到 LTXVConditioning (#1241),適應影片領域的條件並將幀速率上下文向前傳遞。對於低 VRAM 運行,圖表還包括基於 API 的編碼器 (🅛🅣🅧 Gemma API Text Encode - POSITIVE (#4980) 和 ... - NEGATIVE (#4981)) 由 LTX API KEY 字符串 (#4979) 控制;默認接線使用本地編碼器。
預處理#
LTXVAudioVAEEncode (#5005) 將來源語音轉換為音頻潛在向量,LTXVSetAudioRefTokens (#5006) 將該潛在向量注入文本條件,使生成器“聽到”時間和音素。EmptyLTXVLatentVideo (#3059) 準備一個具有正確空間大小和對齊輸入幀數的佔位符影片潛在向量。LTXAddVideoICLoRAGuide (#5004) 使用 s1 幀附加 IC-LoRA 參考指導,在採樣前建立身份和嘴部區域注意力。
生成低解析度#
標準擴散循環由 CFGGuider (#4828)、KSamplerSelect (#4831)、ManualSigmas (#4984) 和 SamplerCustomAdvanced (#4829) 組成。採樣器在 LTXVConcatAVLatent (#4528) 組成的音頻+影片潛在向量上運行,確保音頻條件參與每一步。採樣後,LTXVSeparateAVLatent (#4845) 分離潛在向量,使 LTXVSetAudioRefTokens (#5013) 可以凍結相同的語音表示以進行高解析度通過。此階段將唇形鎖定到語音並在 s1 大小設定運動基線。
生成高解析度#
LTXVLatentUpsampler (#4975) 使用 Spatial Upscaler x2 提升影片潛在向量,保持運動同時增加空間細節容量。LTXAddVideoICLoRAGuide (#5014) 使用更高解析度的幀在 s2 大小再應用 IC-LoRA,以便在細化通過中保持相同的說話者身份和準確的嘴形。如果更改高解析度幀大小,請重新訪問此節點以保持參考指導與目標輸出一致。第二個擴散循環 (CFGGuider (#4964)、KSamplerSelect (#4976)、ManualSigmas (#4985)、SamplerCustomAdvanced (#4971)) 細化升級的潛在向量,同時 LTXVConcatAVLatent (#4969) 保持凍結的語音潛在向量同步。LTXVCropGuides (#5011, #5015) 管理安全裁剪和區域指導,以便面部在兩個通過中保持適當框架。
解碼#
LTXVTiledVAEDecode (#4995) 使用平鋪將最終影片潛在向量解碼為圖像,以提高 VRAM 效率,LTXVAudioVAEDecode (#4848) 返回同步音頻。CreateVideo (#4849) 以原始幀速率組裝幀和音頻,SaveVideo (#4852) 使用預填充的 RunComfy 名稱寫入文件;更改此值以標記您的輸出。結果是一個完全同步的 LTX-2.3 ICLoRA LipDub 剪輯,準備供審查或交付。
Comfyui LTX-2.3 ICLoRA LipDub 工作流程中的關鍵節點#
LTXICLoRALoaderModelOnly (#5012)#
加載 LipDub IC-LoRA 並將其附加到基本模型,使唇形運動遵循輸入語音而不覆蓋身份。如果需要更強或更細微的唇控,請在此調整 LoRA 權重;保持與您在堆疊中應用的任何其他 LoRA 協調,以避免過度條件化。
LTXAddVideoICLoRAGuide (#5004)#
在低解析度階段使用縮小的參考幀應用 IC-LoRA 指導。這是工作流程首次鎖定身份和嘴部區域注意力的地方;通過切換指導進行 A/B 測試以查看參考指導對時間和發音的影響。
LTXAddVideoICLoRAGuide (#5014)#
在高解析度下使用 s2 幀再應用 IC-LoRA 指導,以便細化通過中保持相同的講者身份和準確的嘴形。如果更改高解析度幀大小,請重新訪問此節點以保持參考指導與目標輸出一致。
LTXVSetAudioRefTokens (#5006)#
將編碼的語音綁定到您的文本條件,使採樣器將視音符與音素對齊。跨通過使用相同的音頻潛在向量以獲得穩定的結果;此圖表自動處理此問題,但如果在運行中更換音頻,您應刷新條件和串聯潛在向量。
LTXVLatentUpsampler (#4975)#
使用 LTX-2.3 空間升頻器 x2 升級影片潛在向量,以便在高解析度採樣器之前為細節提供空間。如果 VRAM 緊張,將其與較小的 s2 尺寸或解碼器中的輕型平鋪配對,以平衡質量和吞吐量。
LTXVTiledVAEDecode (#4995)#
使用平鋪將最終潛在向量解碼為幀,以便在有限的 GPUs 上適應大輸出。在此調整平鋪數量和重疊以在速度和內存佔用之間進行權衡;較少的平鋪速度更快,但需要更多的 VRAM,而更多的平鋪會降低 VRAM,但成本時間更長。
可選附加功能#
- 配音提示:包括您想要說的確切詞語;模型不會自動翻譯。使用目標語言的本地腳本,保持單一講者,並儘量與原始行長度相似,以保持自然節奏。
- 性能提示:如果遇到 VRAM 限制,減少
Resize Image/Mask (s2 size)(#5003) 中的 s2 調整,並增加LTXVTiledVAEDecode(#4995) 中的平鋪。為了重複性,保持RandomNoise種子在兩個通過中固定。 - 工作流程默認值:示例輸入文件名在
LoadVideo(#5002) 中預填充,保存器設置了一個一致的輸出名稱。替換這兩者以批量運行多個 LTX-2.3 ICLoRA LipDub,而不會覆蓋結果。 - 框架:如果面部漂移到邊緣附近,調整
LTXVCropGuides(#5011, #5015) 以便嘴部區域在兩個通過中保持穩定裁剪。
致謝#
此工作流程實現並基於以下作品和資源構建。我們對 Lightricks 的 LTX-2.3-22b-IC-LoRA-LipDub 模型和 RunComfy 的共享 ComfyUI 工作流程 (Cloud Save source) 的貢獻和維護表示感謝。欲了解權威細節,請參閱以下鏈接的原始文檔和存儲庫。
資源#
- Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- arXiv: arXiv:2601.22143
- RunComfy/Cloud Save source
- Docs / Release Notes: RunComfy shared workflow
注意:使用參考的模型、數據集和代碼需遵循其作者和維護者提供的相應許可和條款。