
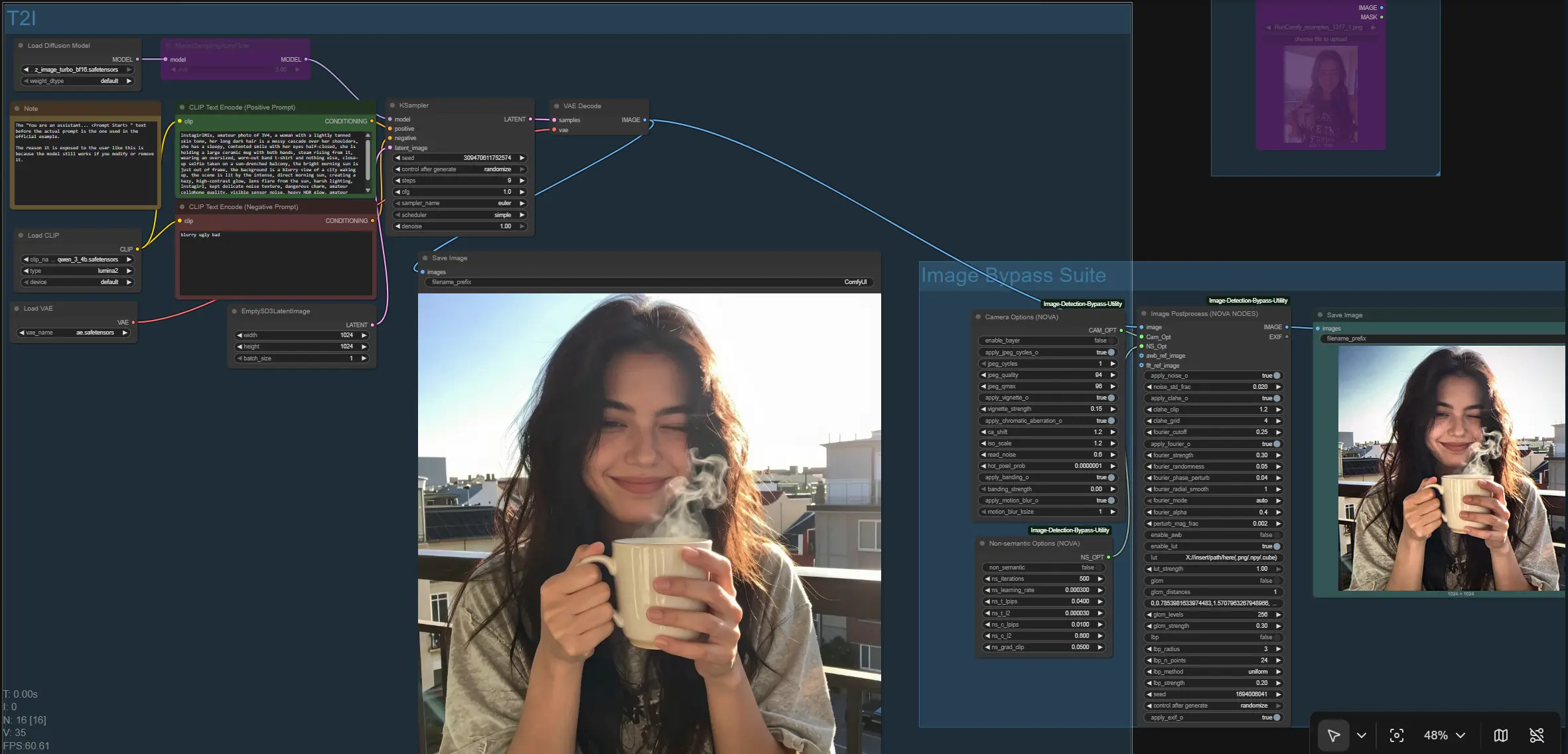







ComfyUI Image Bypass 工作流程#
此工作流程提供了一個模塊化的 ComfyUI 圖像繞過管道,結合了非語義正規化、FFT‑域控制和相機管道模擬。它專為創作者和研究人員設計,他們需要一種可靠的方式通過圖像繞過階段處理圖像,同時保持對輸入路由、預處理行為和輸出一致性的完全控制。
在其核心,圖表生成或攝取圖像,然後將其路由通過一個圖像繞過套件,該套件可以應用傳感器樣工件、頻率塑形、紋理匹配和感知優化器。結果是一個乾淨、可配置的路徑,適合批處理、自動化和在消費者 GPU 上的快速迭代。圖像繞過邏輯由此存儲庫的開源實用程序提供支持:PurinNyova/Image-Detection-Bypass-Utility。
Comfyui 圖像繞過工作流程中的關鍵模型#
- z_image_turbo_bf16 (UNet checkpoint)。用於 T2I 分支的快速文本到圖像擴散主幹,用於快速原型設計和基線圖像生成。可以替換為您偏好的檢查點。參考:Comfy-Org/z_image_turbo on Hugging Face。
- VAE (ae.safetensors)。處理潛在解碼回像素,以便抽樣的輸出可以被圖像繞過階段可視化和進一步處理。如果您偏好不同的重建配置文件,可以切換任何兼容的 VAE。
- Prompt encoder (通過 CLIPLoader 加載)。將您的正面和負面提示編碼為抽樣器的條件向量。圖表對您加載的特定文本編碼文件不敏感,因此您可以根據需要替換模型以用於您的基礎生成器。
如何使用 Comfyui 圖像繞過工作流程#
從高層次來看,工作流程提供了兩種生成進入圖像繞過套件的圖像的方法:文本到圖像分支 (T2I) 和圖像到圖像分支 (I2I)。兩者都匯聚到一個應用圖像繞過邏輯的單一處理節點,並將最終結果寫入磁盤。圖表還保存繞過前的基線,以便您可以比較輸出。
組:T2I#
當您想從提示合成新圖像時,使用此路徑。您的提示編碼器由 CLIPLoader (#164) 加載,並由 CLIP Text Encode (Positive Prompt) (#168) 和 CLIP Text Encode (Negative Prompt) (#163) 讀取。UNet 由 UNETLoader (#165) 加載,選擇性地由 ModelSamplingAuraFlow (#166) 修補以調整模型的抽樣行為,然後從 EmptySD3LatentImage (#162) 開始用 KSampler (#167) 抽樣。解碼的圖像從 VAEDecode (#158) 出來,並通過 SaveImage (#159) 保存為基線,然後進入圖像繞過套件。對於此分支,您的主要輸入是正面/負面提示,如果需要,還有 KSampler (#167) 中的種子策略。
組:I2I#
當您已經有圖像要處理時,選擇此路徑。通過 LoadImage (#157) 加載它,並將 IMAGE 輸出路由到 NovaNodes (#146) 上的圖像繞過套件輸入。這完全繞過文本調節和抽樣。它非常適合批量後處理、現有數據集上的實驗或標準化其他工作流程的輸出。根據您是想生成還是嚴格轉換,可以自由在 T2I 和 I2I 之間切換。
組:圖像繞過套件#
這是圖表的核心處理器 NovaNodes (#146) 接收傳入的圖像和兩個選項塊:CameraOptionsNode (#145) 和 NSOptionsNode (#144)。節點可以在流線型自動模式或手動模式下運行,手動模式會暴露頻率塑形 (FFT 平滑/匹配)、像素和相位擾動、局部對比度和色調處理、可選的 3D LUT 和紋理統計調整的控制。兩個可選輸入讓您插入自動白平衡參考和 FFT/紋理參考圖像以指導正規化。最終的圖像繞過結果由 SaveImage (#147) 寫入,讓您同時獲得基線和處理後的輸出以進行並排評估。
Comfyui 圖像繞過工作流程中的關鍵節點#
NovaNodes (#146)#
核心圖像繞過處理器。它協調頻域塑形、空間擾動、局部色調控制、LUT 應用和可選的紋理正規化。如果您提供 awb_ref_image 或 fft_ref_image,它們將在管道的早期用於指導顏色和光譜匹配。從自動模式開始,以獲得合理的基線,然後切換到手動模式以微調效果強度和混合,以適合您的內容和下游任務。為了進行一致的比較,設置並重用種子;為了探索,隨機化以多樣化微變化。
NSOptionsNode (#144)#
控制非語義優化器,該優化器在保持感知相似性的同時微調像素。它暴露迭代次數、學習率和感知/正規化權重 (LPIPS 和 L2) 以及梯度裁剪。當您需要微妙的分佈移動而沒有明顯的工件時使用它;保持更改保守,以維持自然紋理和邊緣。完全禁用它,以測量圖像繞過管道在沒有優化器的情況下的幫助程度。
CameraOptionsNode (#145)#
模擬傳感器和鏡頭特性,例如去馬賽克和 JPEG 循環、暈影、色差、運動模糊、帶狀和讀取噪聲。將其視為現實層,可以為您的圖像添加合理的獲取工件。僅啟用與目標捕獲條件匹配的組件;堆疊太多可能會過度限制外觀。為了可重複的輸出,保持相同的相機選項,同時改變其他參數。
ModelSamplingAuraFlow (#166)#
在模型到達 KSampler (#167) 之前修補其抽樣行為。當您選擇的主幹從替代步驟軌跡中受益時,這很有用。當您注意到提示意圖和樣本結構之間的不匹配時進行調整,並將其與您的抽樣器和調度器選擇一起對待。
KSampler (#167)#
執行擴散抽樣,給定模型、正面和負面條件以及起始潛在。關鍵槓桿是種子策略、步驟、抽樣器類型和整體去噪強度。較低的步驟有助於提高速度,而較高的步驟可以穩定結構,如果您的基礎模型需要它。保持此節點的行為穩定,同時在圖像繞過設置上進行迭代,以便您可以將更改歸因於後處理而非生成器。
可選附加項#
- 自由更換模型。圖像繞過套件對模型不敏感;您可以替換
z_image_turbo_bf16並仍然通過相同的處理堆棧路由結果。 - 謹慎使用參考。提供與目標領域共享光照和內容特徵的
awb_ref_image和fft_ref_image;不匹配的參考會降低現實感。 - 公平比較。保持
SaveImage(#159) 作為基線,SaveImage(#147) 作為圖像繞過輸出,以便您可以 A/B 測試設置並跟踪改進。 - 小心批處理。僅在 VRAM 允許的情況下增加
EmptySD3LatentImage(#162) 批量大小,並在測量小的參數更改時偏好固定種子。 - 學習實用程序。欲了解圖像繞過組件的功能詳細信息和持續更新,請參閱上游項目:PurinNyova/Image-Detection-Bypass-Utility。
貢獻者#
- ComfyUI,這一工作流程使用的圖表引擎:comfyanonymous/ComfyUI。
- 示例基礎檢查點:Comfy-Org/z_image_turbo。
感謝#
此工作流程實現並基於以下工作和資源。我們誠摯感謝 PurinNyova 在 Image-Detection-Bypass-Utility 中的貢獻和維護。有關權威詳細信息,請參閱下方鏈接的原始文檔和存儲庫。
資源#
- PurinNyova/Image-Detection-Bypass-Utility
- GitHub: PurinNyova/Image-Detection-Bypass-Utility
- 文檔 / 發行說明: Repository (tree/main)
注意:所引用的模型、數據集和代碼的使用受其作者和維護者提供的各自許可和條款的約束。