

ComfyUI Vid2Vid 工作流程,由 **YVANN** 創建,介紹了兩種不同的工作流程,以實現高品質、專業的動畫。
- 第一個 ComfyUI 工作流程:ComfyUI Vid2Vid 第1部分 | 組成與遮罩
- 第二個工作流程:ComfyUI Vid2Vid 第2部分 | SDXL 風格轉換
ComfyUI Vid2Vid 第1部分 | 組成與遮罩#
此工作流程通過專注於原始視頻的組成與遮罩來增強創造力。
步驟1:模型加載器 | ComfyUI Vid2Vid 工作流程 第1部分#
選擇適合您動畫的模型,包括選擇檢查點模型、VAE(變分自編碼器)模型和 LoRA(低秩適應)模型。這些模型對於定義動畫的能力和風格至關重要。
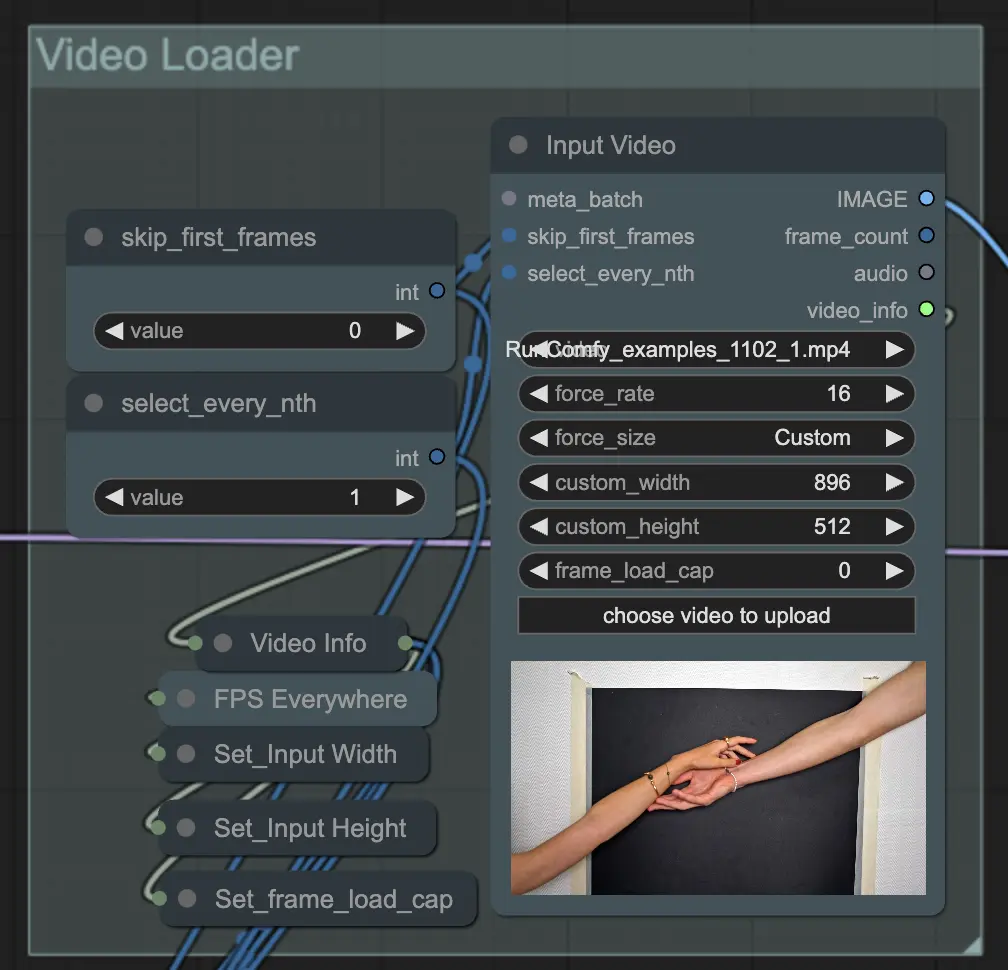
步驟2:視頻加載器 | ComfyUI Vid2Vid 工作流程 第1部分#
輸入視頻節點負責導入將用於動畫的視頻文件。該節點會讀取視頻並將其轉換為單獨的幀,然後在後續步驟中進行處理。這允許詳細的逐幀編輯和增強。
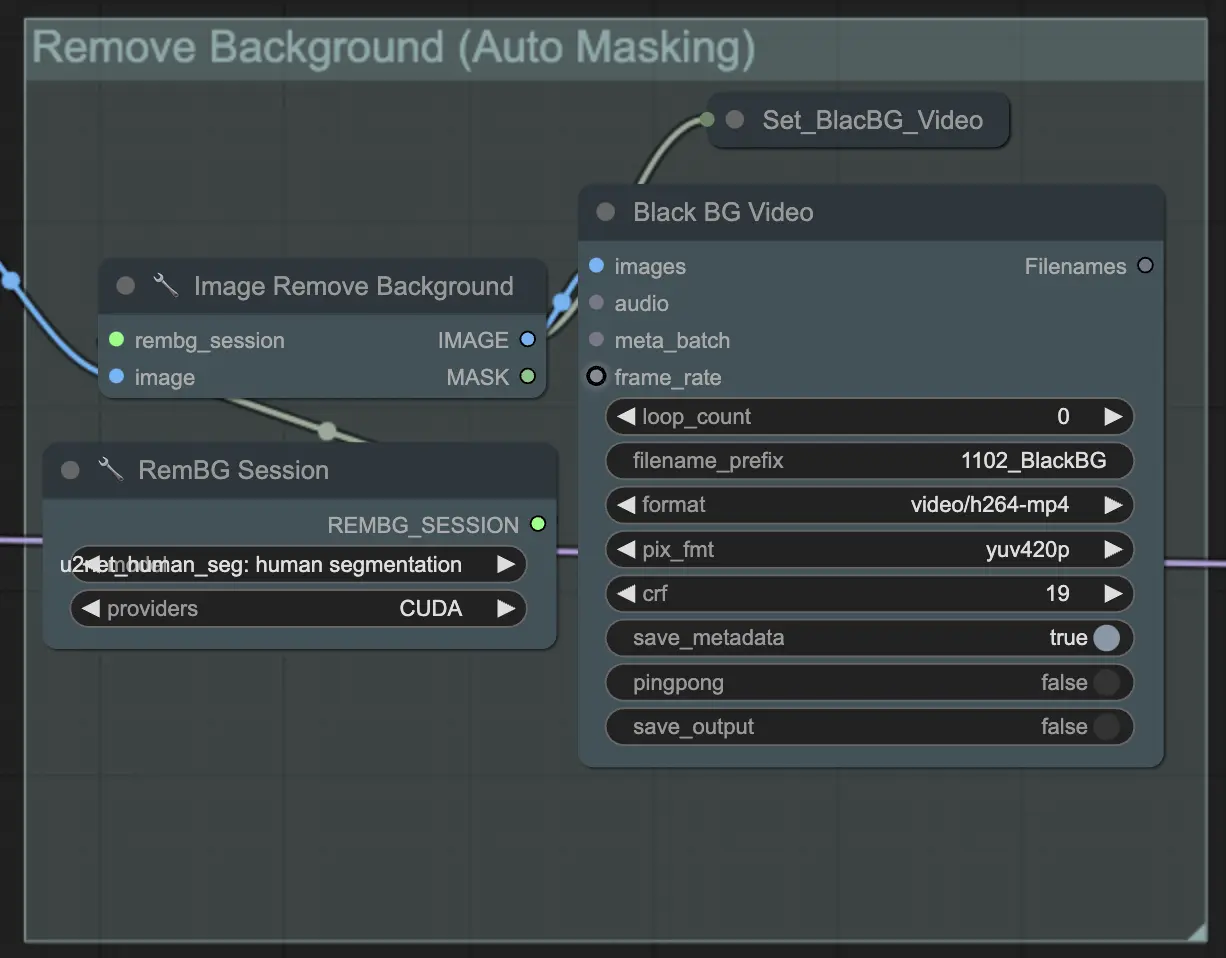
步驟3:移除背景(自動遮罩) | ComfyUI Vid2Vid 工作流程 第1部分#
移除背景(自動遮罩)使用自動遮罩技術將主體從背景中分離出來。這涉及使用模型來檢測和分離前景主體與背景,創建二進制遮罩。這一步對於確保主體可以獨立於背景進行操作至關重要。
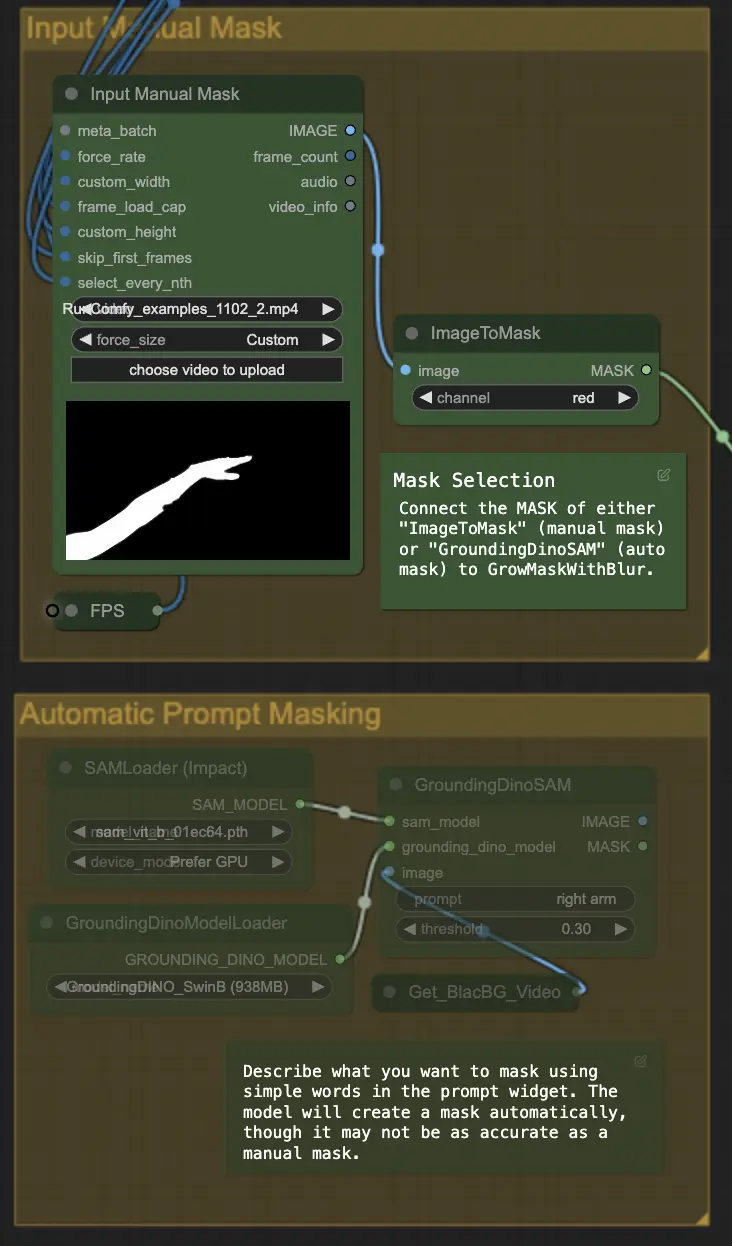
步驟4:遮罩特定區域(手動遮罩或自動遮罩) | ComfyUI Vid2Vid 工作流程 第1部分#
這一步允許對上一步創建的遮罩進行精細化。您可以使用其他軟件手動遮罩特定區域,或者依賴 ComfyUI 的 'Segment Anything' 自動遮罩功能。
- 手動遮罩: 需要在 ComfyUI 之外的其他軟件中進行精確控制。
- 自動遮罩: 使用自動遮罩功能,您可以在提示小部件中使用簡單的詞語描述您想要遮罩的內容。模型會自動創建遮罩,雖然可能不如手動遮罩準確。
默認版本使用手動遮罩。如果您想嘗試自動遮罩,請繞過手動遮罩組並啟用自動遮罩組。此外,將 'GroundingDinoSAM'(自動遮罩)的 MASK 連接到 'GrowMaskWithBlur',而不是將 'ImageToMask'(手動遮罩)連接到 'GrowMaskWithBlur'。
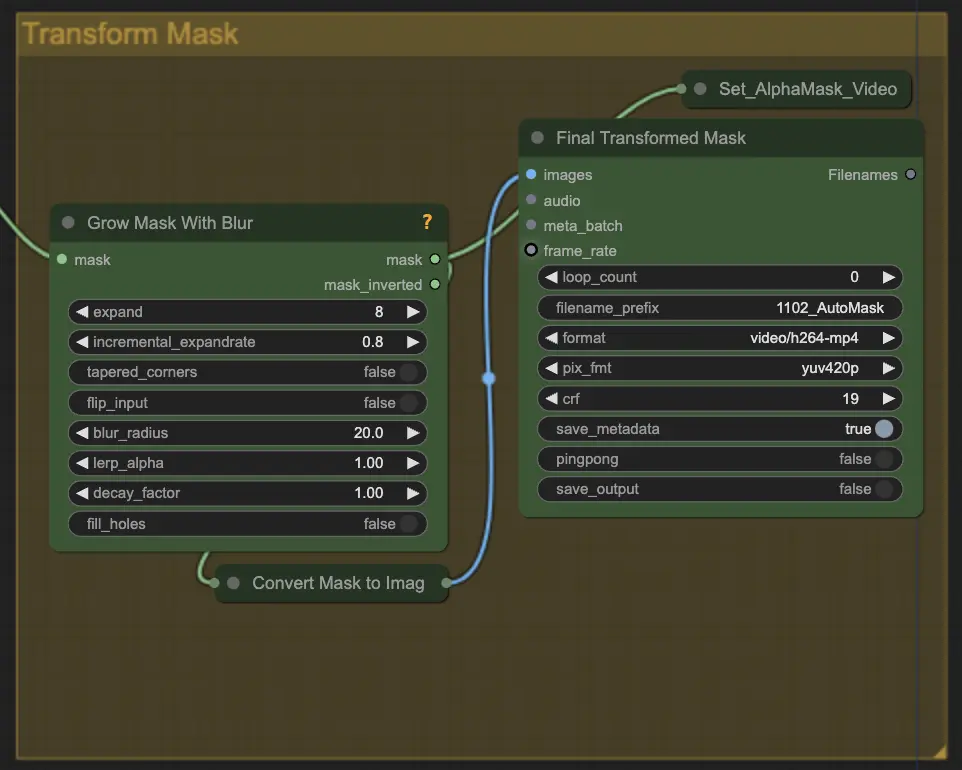
步驟5:遮罩轉換 | ComfyUI Vid2Vid 工作流程 第1部分#
遮罩轉換將遮罩轉換為圖像,並允許進行額外的調整,例如在原始遮罩上添加模糊。這有助於柔化邊緣,讓遮罩更自然地與圖像的其他部分融合。
步驟6:輸入提示 | ComfyUI Vid2Vid 工作流程 第1部分#
輸入文本提示以引導動畫過程。提示可以描述主體的所需風格、外觀或動作。這對於定義動畫的創意方向至關重要,確保最終輸出符合預期的藝術風格。
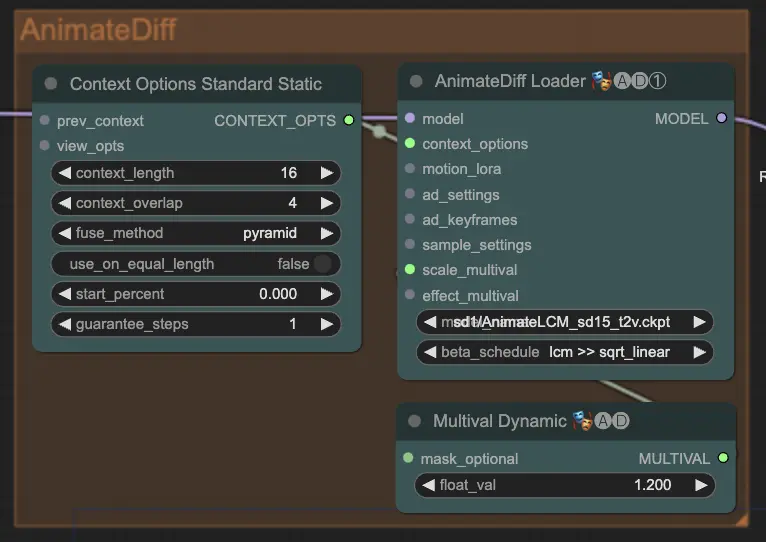
步驟7:AnimateDiff | ComfyUI Vid2Vid 工作流程 第1部分#
AnimateDiff 節點通過識別連續幀之間的差異並逐步應用這些更改來創建平滑的動畫。這有助於保持運動的一致性並減少動畫中的突變,從而使其看起來更流暢和自然。
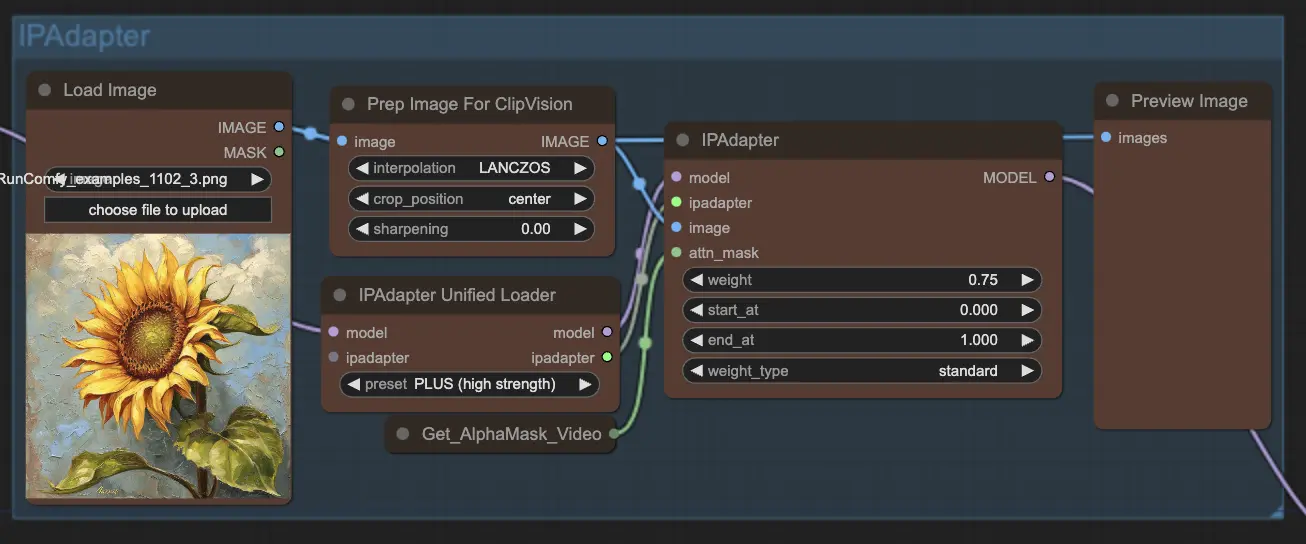
步驟8:IPAdapter | ComfyUI Vid2Vid 工作流程 第1部分#
IPAdapter 節點將輸入圖像調整為符合所需的輸出風格或特徵。這包括上色和風格轉換等任務,確保動畫的每一幀都保持一致的外觀和風格。
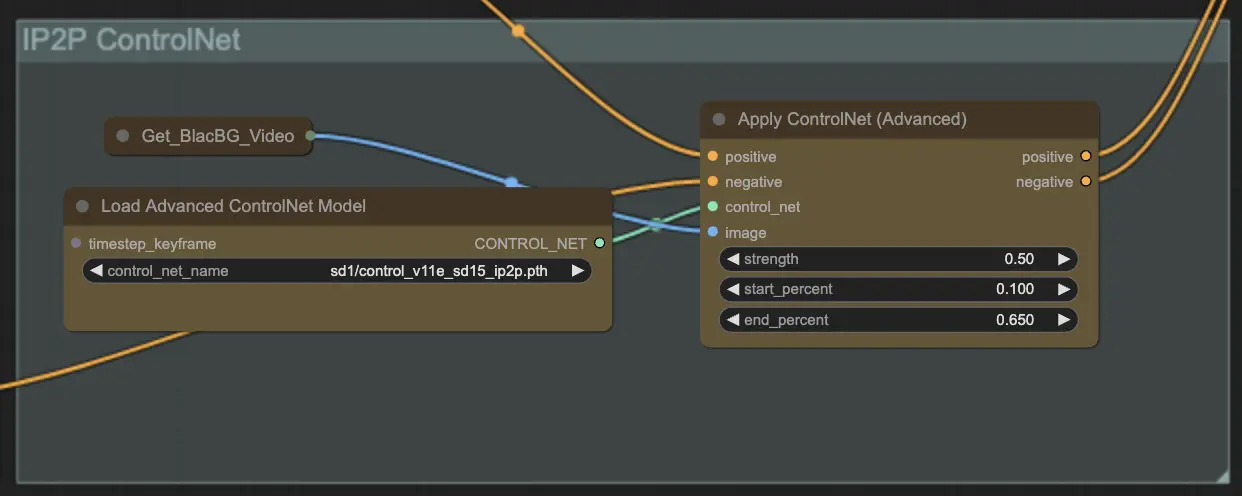
步驟9:ControlNet | ComfyUI Vid2Vid 工作流程 第1部分#
使用 ControlNet - v1.1 - Instruct Pix2Pix Version model 增強擴散模型,讓它們能夠處理額外的輸入條件(例如,邊緣圖、分割圖)。它通過在端到端方式下控制這些預訓練模型的任務特定條件來促進文本到圖像的生成,即使在較小的數據集上也允許穩健的學習。
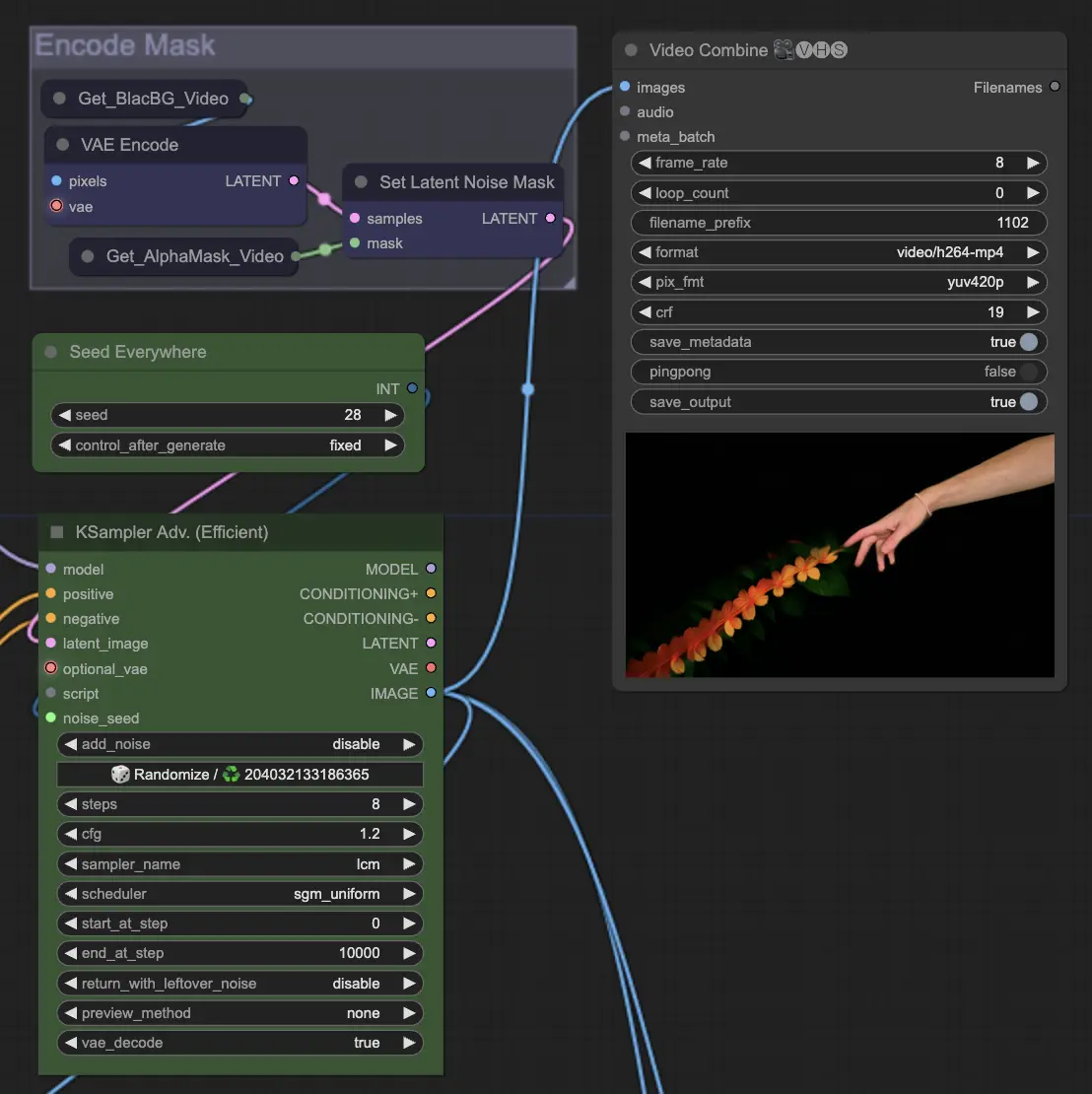
步驟10:渲染 | ComfyUI Vid2Vid 工作流程 第1部分#
在 渲染 步驟中,處理過的幀被編譯成最終的視頻輸出。這一步確保所有單獨的幀無縫地組合成一致的動畫,準備導出和進一步使用。
步驟11:背景合成 | ComfyUI Vid2Vid 工作流程 第1部分#
這涉及將動畫主體與背景合成。您可以為動畫添加靜態或動態背景,確保主體能夠順利地與新背景融合,創造出視覺上吸引人的最終產品。
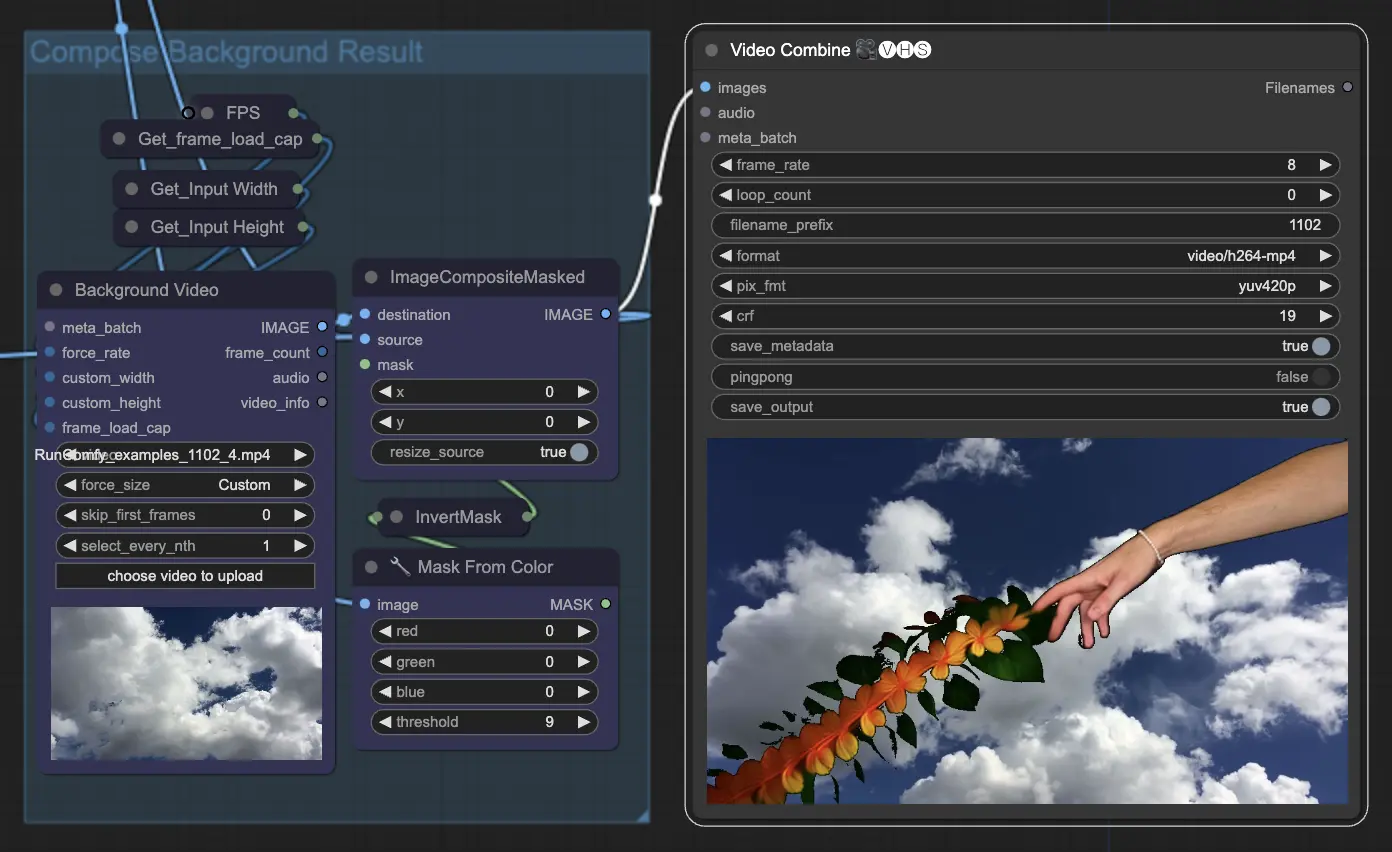
通過利用 ComfyUI Vid2Vid 工作流程 第1部分,您可以創建複雜的動畫,對過程中的每一個方面進行精確控制,從組成和遮罩到最終渲染。