
InfiniteTalk: 在 ComfyUI 中從單一圖像生成口型同步的肖像影片#
這個 ComfyUI InfiniteTalk 工作流程從單一參考圖像加上一段音頻剪輯創建自然、語音同步的肖像影片。它結合了 WanVideo 2.1 圖像到影片的生成技術與 MultiTalk 說話頭模型,以產生豐富的口腔動作和穩定的身份。如果您需要短社交剪輯、影片配音或化身更新,InfiniteTalk 能在幾分鐘內將靜態照片轉化為流暢的講話影片。
InfiniteTalk 基於 MeiGen-AI 的卓越 MultiTalk 研究。背景和歸屬請參見開源項目:MeiGen-AI/MultiTalk。
Comfyui InfiniteTalk 工作流程中的關鍵模型#
- MultiTalk (GGUF, InfiniteTalk 變體): 從音頻驅動音素感知的面部動作,讓口和下巴的動作自然跟隨語音。參考:Kijai/WanVideo_comfy_GGUF › InfiniteTalk 和上游想法:MeiGen-AI/MultiTalk。
- WanVideo 2.1 I2V 14B (GGUF): 主要的圖像到影片生成器,能在動畫幀中保留身份、光照和姿勢。推薦權重:city96/Wan2.1-I2V-14B-480P-gguf。
- Wan 2.1 VAE (bf16): 將潛在幀解碼為 RGB,顏色偏移最小;在上述 WanVideo 包中提供。
- UMT5-XXL 文本編碼器: 解析您的正面和負面提示以推動風格、場景和動作上下文。模型家族:google/umt5-xxl。
- CLIP Vision: 從您的參考圖像中提取視覺嵌入,鎖定身份和整體外觀。
- Wav2Vec2 (Tencent GameMate): 將原始語音轉化為強大的音頻特徵以改進 MultiTalk 嵌入的同步和韻律:TencentGameMate/chinese-wav2vec2-base。
提示:此 InfiniteTalk 圖表是為 GGUF 構建的。保持 InfiniteTalk MultiTalk 權重和 WanVideo 主體在 GGUF 中以避免不兼容。也可選擇使用 fp8/fp16 構建:Kijai/WanVideo_comfy_fp8_scaled 和 Kijai/WanVideo_comfy。
如何使用 Comfyui InfiniteTalk 工作流程#
該工作流程從左到右運行。您需要提供三樣東西:乾淨的肖像圖像、一個語音音頻文件和一個簡短的提示來引導風格。然後圖表提取文本、圖像和音頻提示,將它們融合成動作感知的影片潛在變量,並渲染一個同步的 MP4。
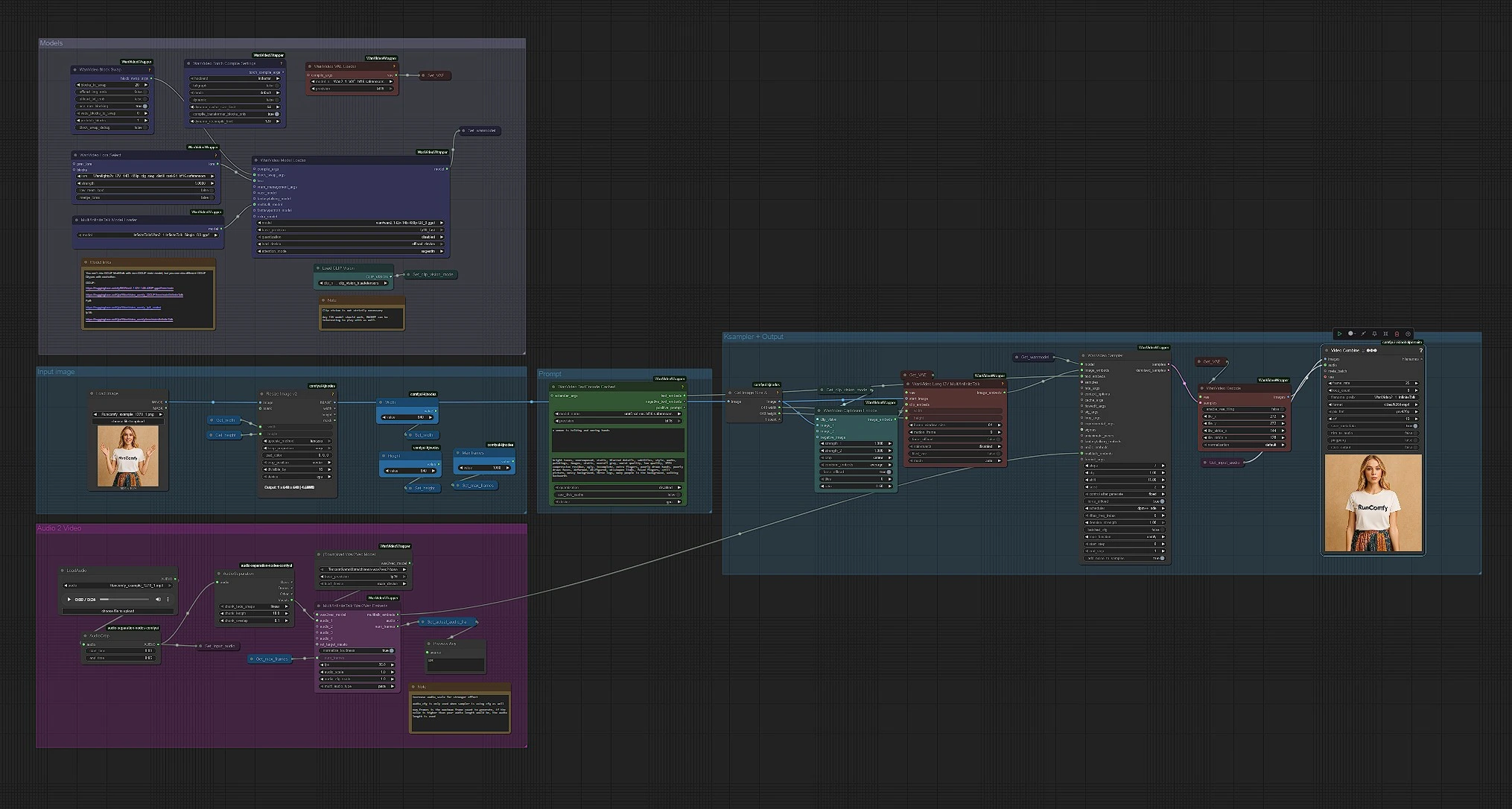
模型#
這一組加載 WanVideo、VAE、MultiTalk、CLIP Vision 和文本編碼器。WanVideoModelLoader (#122) 選擇 Wan 2.1 I2V 14B GGUF 主體,而 WanVideoVAELoader (#129) 準備匹配的 VAE。MultiTalkModelLoader (#120) 加載驅動語音驅動動作的 InfiniteTalk 變體。您可以選擇性地在 WanVideoLoraSelect (#13) 中附加 Wan LoRA 以偏向外觀和動作。保持這些不變以進行快速首次運行;它們已預先連接到對大多數 GPU 友好的 480p 管道。
提示#
WanVideoTextEncodeCached (#241) 接受您的正面和負面提示並使用 UMT5 進行編碼。使用正面提示描述主題和場景基調,而不是身份;身份來自參考照片。將負面提示集中在您想要避免的人工製品上(模糊、多餘的肢體、灰色背景)。InfiniteTalk 中的提示主要塑造光線和運動能量,而面部保持一致。
輸入圖像#
CLIPVisionLoader (#238) 和 WanVideoClipVisionEncode (#237) 嵌入您的肖像。使用清晰、正面的頭肩照片,光線均勻。如有需要,輕輕裁剪使面部有活動空間;過度裁剪可能會使動作不穩定。圖像嵌入被向前傳遞,以在影片動畫中保留身份和服裝細節。
音頻到 MultiTalk#
在 LoadAudio (#125) 中加載您的語音;使用 AudioCrop (#159) 修剪以進行快速預覽。DownloadAndLoadWav2VecModel (#137) 獲取 Wav2Vec2,MultiTalkWav2VecEmbeds (#194) 將剪輯轉化為音素感知的動作特徵。短的 4-8 秒剪輯非常適合迭代;一旦您喜歡外觀,可以運行較長的剪輯。乾淨、無背景音樂的聲音效果最佳;強烈的背景音樂可能會混淆口型時序。
圖像到影片、採樣和輸出#
WanVideoImageToVideoMultiTalk (#192) 將您的圖像、CLIP Vision 嵌入和 MultiTalk 融合到由 Width 和 Height 常數設定大小的幀圖像嵌入中。WanVideoSampler (#128) 使用 Get_wanmodel 和您的文本嵌入生成潛在幀。WanVideoDecode (#130) 將潛在變量轉換為 RGB 幀。最後,VHS_VideoCombine (#131) 將幀和音頻混合成每秒 25 幀的 MP4,並設置平衡的質量設置,生成最終的 InfiniteTalk 剪輯。
Comfyui InfiniteTalk 工作流程中的關鍵節點#
WanVideoImageToVideoMultiTalk (#192)#
這個節點是 InfiniteTalk 的核心:它通過合併起始圖像、CLIP Vision 特徵和 MultiTalk 指導來調節說話頭動畫,達到您的目標分辨率。調整 width 和 height 設置比例;832×480 是速度和穩定性的良好默認值。用它作為主要位置來在採樣之前對齊身份和運動。
MultiTalkWav2VecEmbeds (#194)#
將 Wav2Vec2 特徵轉化為 MultiTalk 動作嵌入。如果口腔動作過於微妙,請在此階段提高其影響力(音頻縮放);如果過度誇張,則降低影響力。確保音頻以語音為主,以獲得可靠的音素時序。
WanVideoSampler (#128)#
給定圖像、文本和 MultiTalk 嵌入生成影片潛在變量。對於首次運行,保持默認的調度器和步驟。如果看到閃爍,增加總步驟或啟用 CFG 可以幫助;如果運動感覺太僵硬,則減少 CFG 或採樣器強度。
WanVideoTextEncodeCached (#241)#
使用 UMT5-XXL 編碼正面和負面提示。使用簡潔、具體的語言,如 “工作室光、柔和的皮膚、自然色彩”,並將負面提示集中。記住提示細化框架和風格,而口型同步來自 MultiTalk。
可選附加項#
- 保持 MultiTalk 和 WanVideo 在同一部署家族中(全部 GGUF 或全部非 GGUF)以避免不兼容。
- 使用 5-8 秒的音頻剪輯和默認的 480p 大小進行迭代;如果需要,稍後進行升級。
- 如果身份不穩定,請嘗試更乾淨的來源照片或較溫和的 LoRA。強 LoRA 可能會覆蓋相似性。
- 在安靜的房間中錄製語音並標準化音量;InfiniteTalk 在清晰、乾燥的聲音下能最佳追蹤音素。
致謝#
InfiniteTalk 工作流程代表了 AI 驅動的影片生成的一大飛躍,將 ComfyUI 靈活的節點系統與 MultiTalk AI 模型相結合。這一實現得益於 MeiGen-AI 的原始研究和發布,其 MultiTalk 項目驅動了 InfiniteTalk 的自然語音同步。特別感謝 InfiniteTalk 項目團隊提供的源參考,並感謝 ComfyUI 開發者社區使工作流程無縫集成成為可能。
此外,還要感謝 Kijai,他將 InfiniteTalk 實現於 Wan Video Sampler 節點 中,使創作者能夠直接在 ComfyUI 中製作高質量的講話和演唱肖像。InfiniteTalk 的原始資源鏈接在此提供:InfiniteTalk 範例工作流程。
這些貢獻使得創作者能夠將簡單的肖像轉化為生動、連續的講話化身,為 AI 驅動的敘事、配音和表演內容開啟了新的機會。
