

通過將您的主題(例如舞者)轉變為具有隨著節拍同步擴張和收縮的動態光環,創造出驚人的視頻動畫。此工作流程可用於單一主題或多個主題,如示例中所示。
如何使用音頻反應面具擴張工作流程:#
- 在輸入部分上傳主題視頻
- 選擇最終視頻的所需寬度和高度,以及應從輸入視頻中跳過多少幀,使用 'every_nth'。您還可以使用 'frame_load_cap' 限制渲染的總幀數。
- 填寫正面和負面提示。設置批量幀時間以匹配您希望場景過渡發生的時間。
- 上傳每種默認 IP 適配器主題面具顏色的圖像:
- 紅色 = 主題(舞者)
- 黑色 = 背景
- 白色 = 白色音頻反應擴張面具
- 在 'Models' 部分加載一個好的 LCM 檢查點(我使用 ParadigmLCM by Machine Delusions)。
- 使用模型加載器下方的 Lora stacker 添加任何 loras
- 點擊 Queue Prompt
輸入#
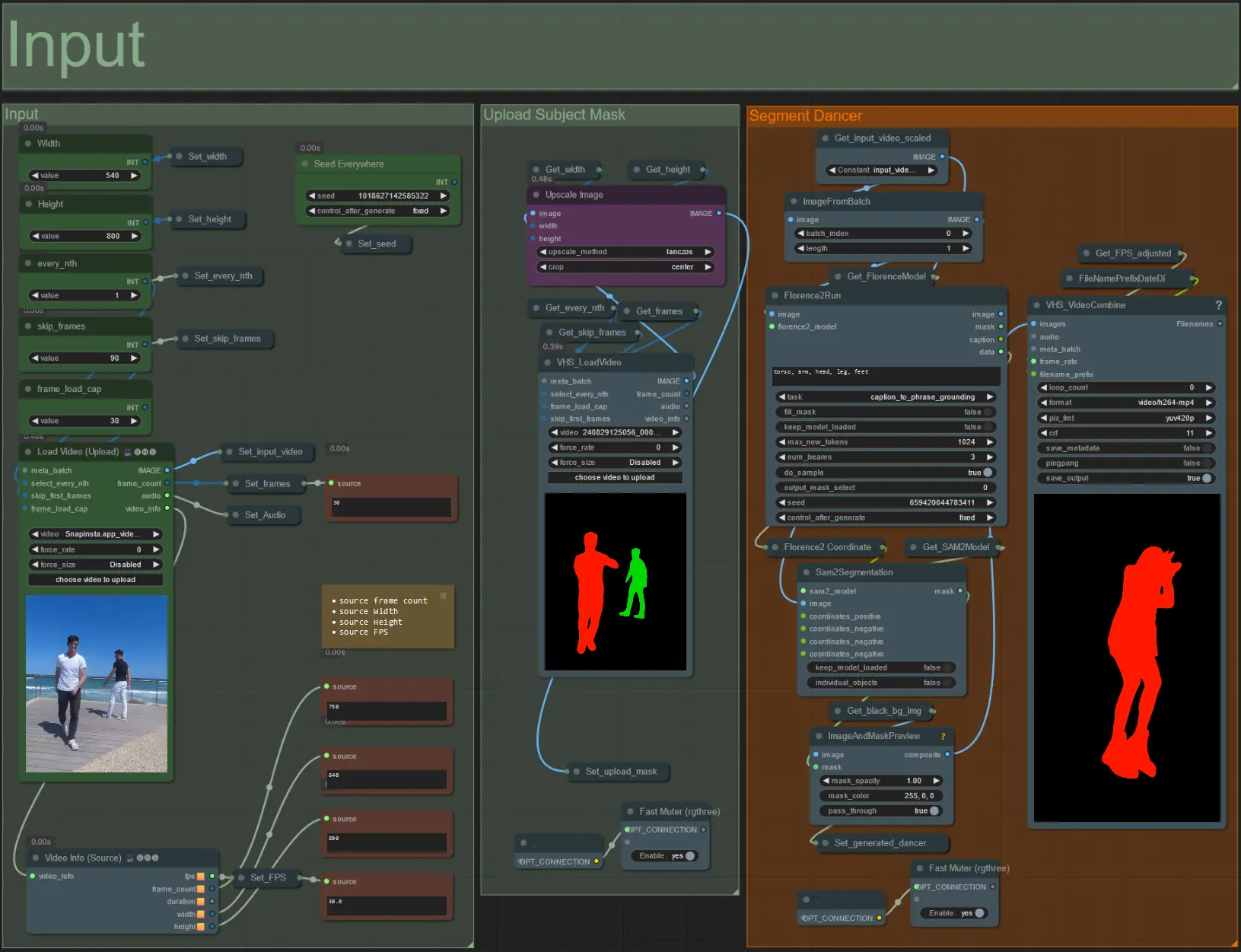
- 將您想要的主題視頻上傳到 Load Video (Upload) 節點。
- 使用左上角的兩個輸入調整輸出寬度和高度。
- every_nth 設置是否使用每隔一幀、每三幀等(2 = 每隔一幀)。默認為 1。
- skip_frames 用於在視頻開始時跳過幀。(100 = 跳過輸入視頻的前 100 幀)。默認為 0。
- frame_load_cap 用於指定應從輸入視頻加載多少總幀數。測試設置時最好保持較低(例如 30 - 60),然後在渲染最終視頻時增加或設置為 0(無幀限制)。
- 右下角的數字字段顯示上傳輸入視頻的信息:總幀數、寬度、高度和 FPS,從上到下。
- 如果您已經有生成的主題面具視頻,取消靜音 'Upload Subject Mask' 部分並上傳面具視頻。可選擇靜音 'Segment Dancer' 部分以節省一些處理時間。
- 有時分段的主題不會完美,然後使用右下角看到的預覽框檢查面具質量。如果是這種情況,您可以在 'Florence2Run' 節點中嘗試針對不同的身體部位,如 'head'、'chest'、'legs' 等,看看是否能得到更好的結果。
提示#
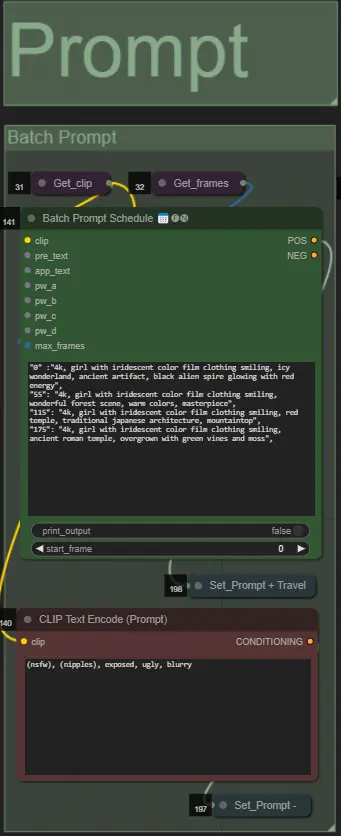
- 使用批量格式設置正面提示:
- 例如: '0': '4k, masterpiece, 1girl standing on the beach, absurdres', '25': 'HDR, sunset scene, 1girl with black hair and a white jacket, absurdres', …
- 負面提示為正常格式,如果需要可添加嵌入。
音頻處理#
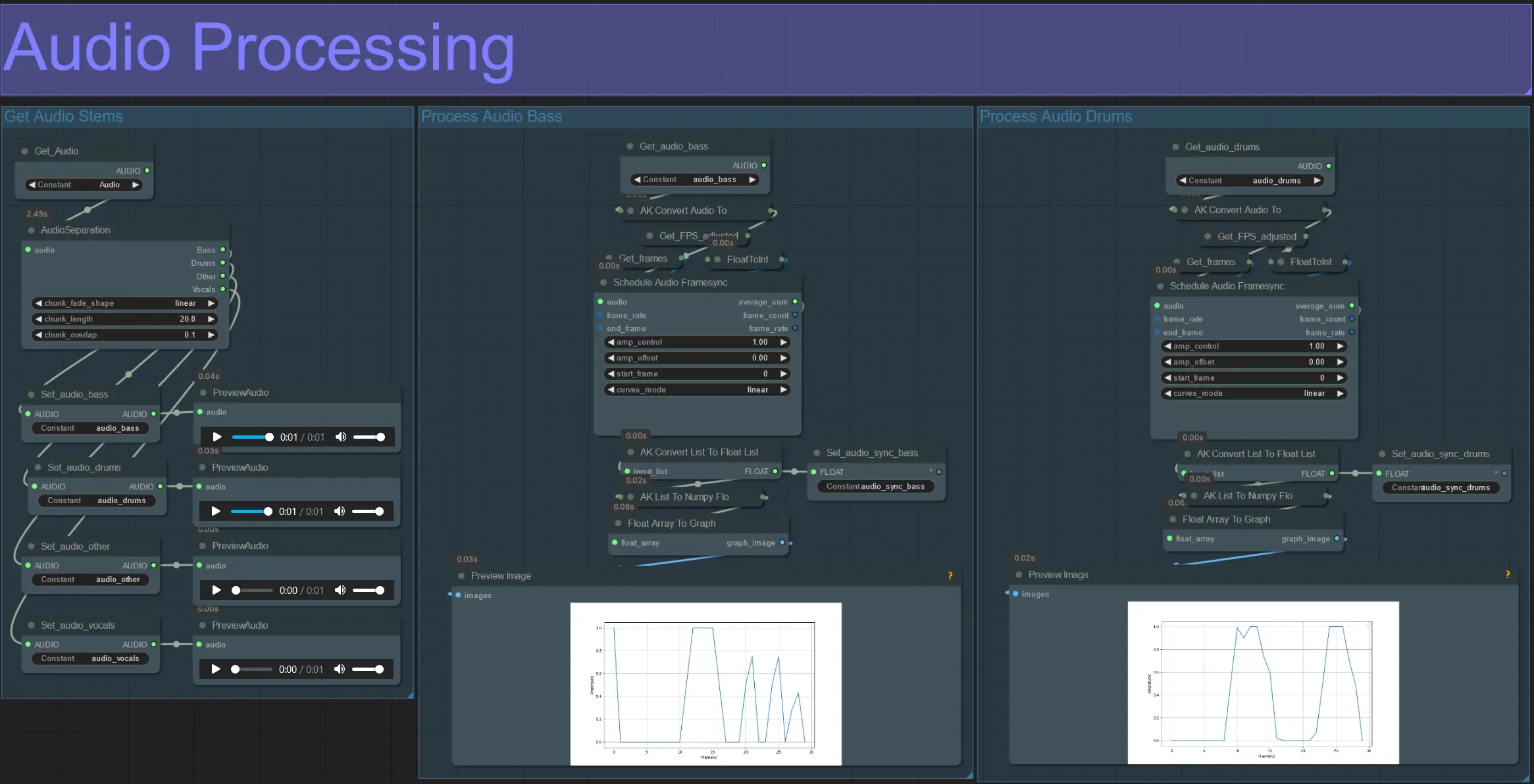
- 此部分從輸入視頻中提取音頻,提取出幹聲(低音、鼓聲、人聲等),然後將其轉換為與輸入視頻幀同步的標準化幅度。
- amp_control = 幅度可以行進的總範圍。
- amp_offset = 幅度可以取的最小值。
- 例如:amp_control = 0.8 和 amp_offset = 0.2 意味著信號將在 0.2 和 1.0 之間行進。
- 有時候鼓聲幹聲包含歌曲的實際低音音符;預覽每個以確定哪個最適合您的面具。
- 使用圖表清晰了解該幹聲的信號在視頻整個持續時間內如何變化。
擴張面具#
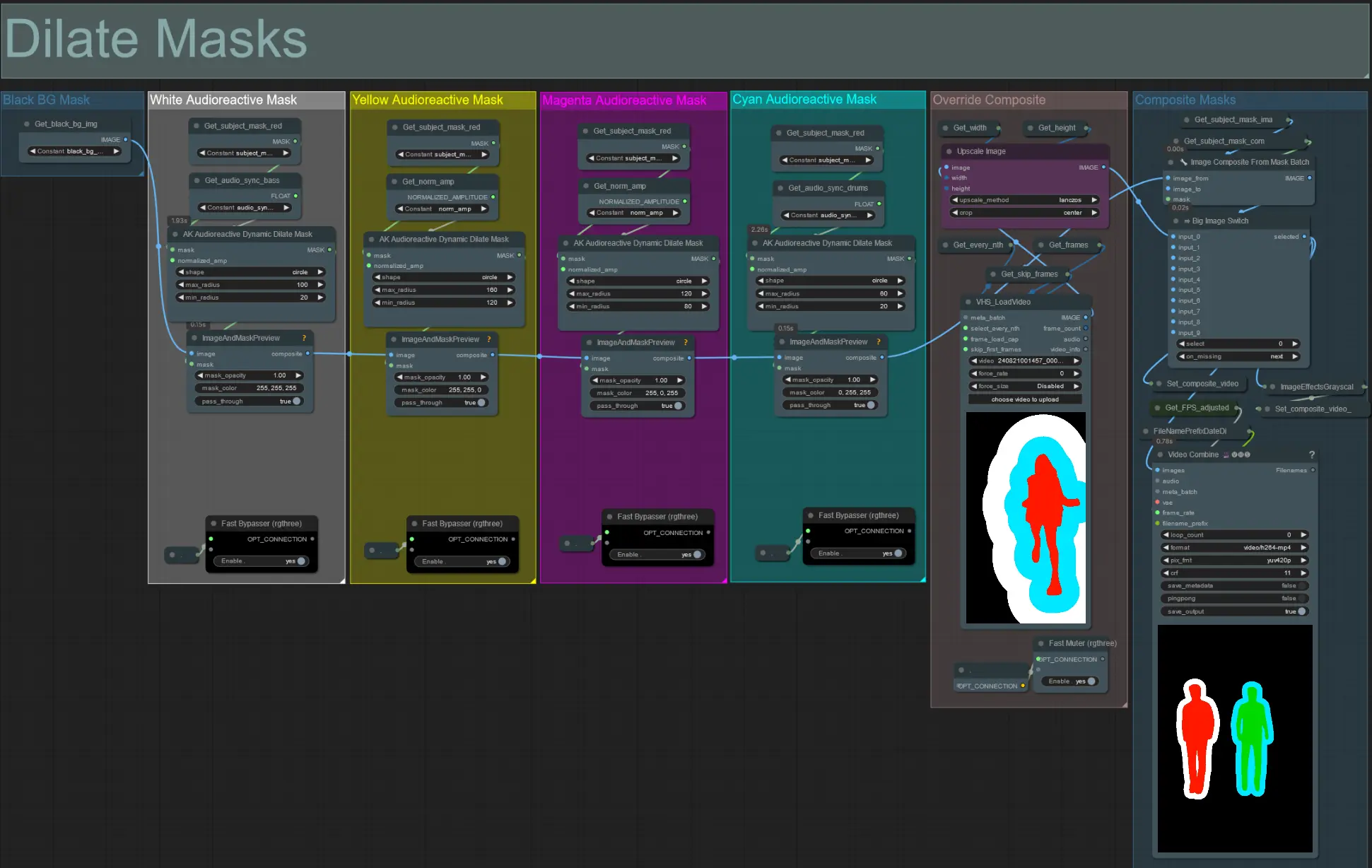
- 每個顏色組對應於它將生成的擴張面具的顏色。
- 使用以下節點設置擴張面具的最小和最大半徑及其形狀:
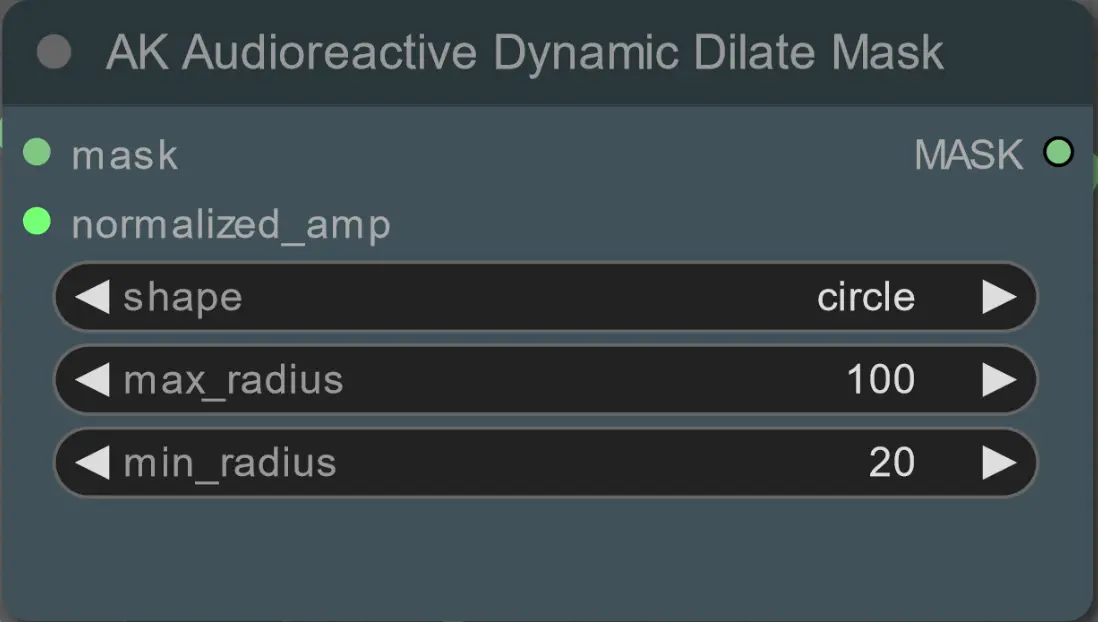
- 形狀:'circle' 是最準確的,但生成時間較長。當您準備進行最終渲染時設置此項。'square' 計算速度快,但不夠準確,最適合測試工作流程和決定 IP 適配器圖像。
- max_radius:當幅度值為最大(1.0)時的面具半徑(以像素為單位)。
- min_radius:當幅度值為最小(0.0)時的面具半徑(以像素為單位)。
- 如果您已經生成了合成面具視頻,您可以取消靜音 'Override Composite Mask' 組並上傳它。建議在覆寫時繞過擴張面具組以節省處理時間。
模型#
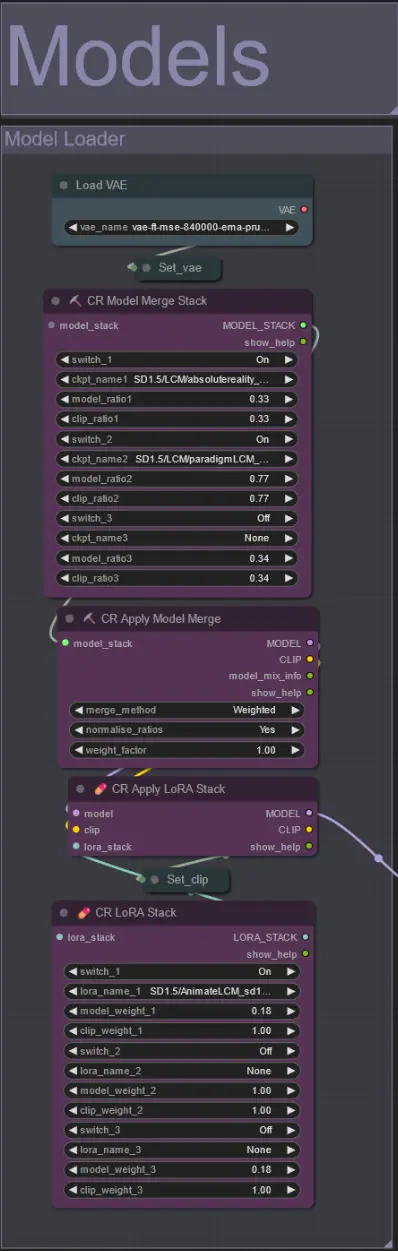
- 使用一個好的 LCM 模型作為檢查點。我推薦 ParadigmLCM by Machine Delusions。
- 使用 Model Merge Stack 合併多個模型以獲得各種有趣效果。確保啟用的模型的權重總和為 1.0。
- 可選地指定 AnimateLCM_sd15_t2v_lora.safetensors,權重低至 0.18 以進一步增強最終效果。
- 使用模型加載器下方的 Lora stacker 添加任何額外的 Loras 到模型中。
AnimateDiff#

- 設置一個不同的 Motion Lora 代替我使用的(LiquidAF-0-1.safetensors)
- 增加/減少 Scale 和 Effect 浮點數以增加/減少輸出的運動量。
IP 適配器#
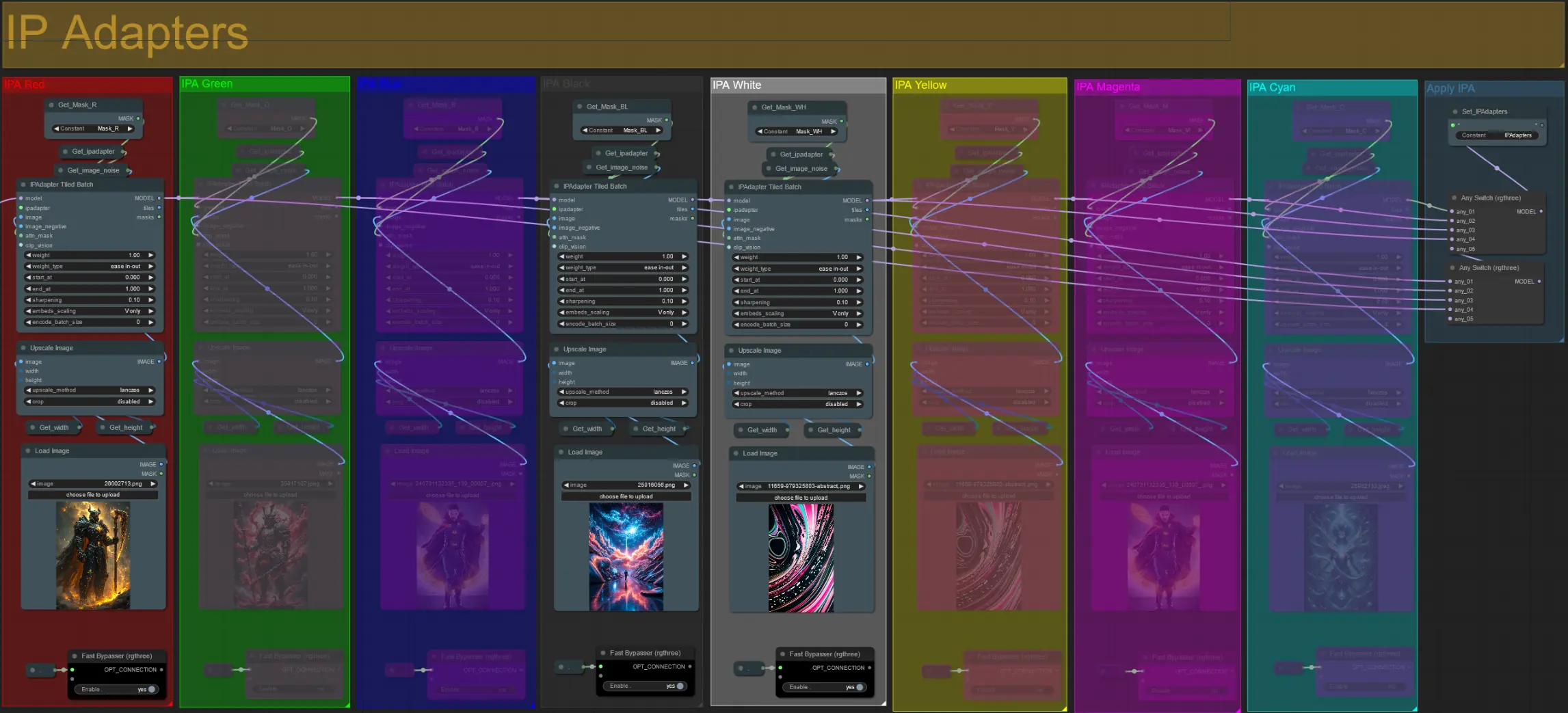
- 在這裡,您可以指定將用於渲染每個擴張面具的背景以及您的視頻主題的參考圖像。
- 每個顏色組的顏色代表它所針對的面具:
紅色、綠色、藍色:#
- 主題面具參考圖像。
黑色:#
- 背景面具圖像,上傳背景的參考圖像。
白色、黃色、洋紅色、青色:#
- 擴張面具參考圖像,為每個使用中的顏色擴張面具上傳一個參考圖像。
ControlNet#
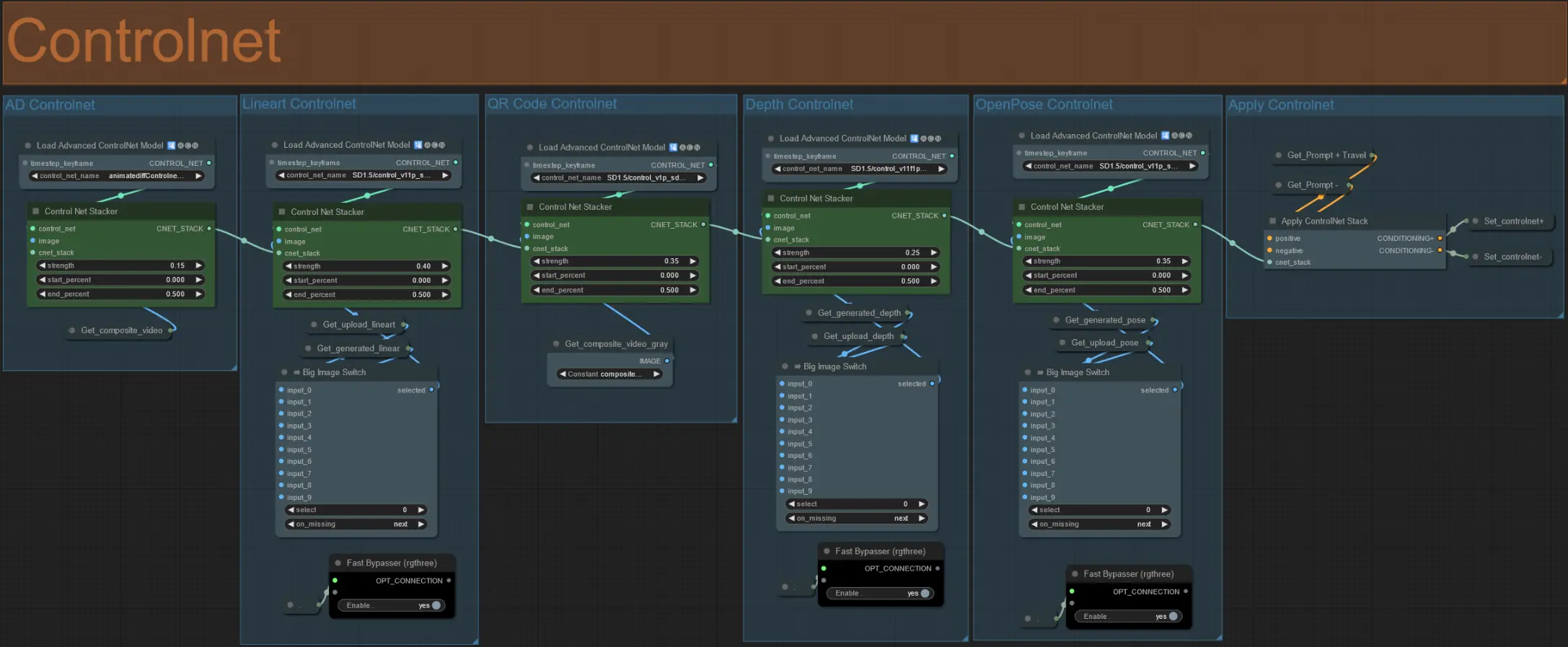
- 此工作流程使用了 5 個不同的 controlnets,包括 AD、Lineart、QR Code、Depth 和 OpenPose。
- 所有 controlnets 的輸入都是自動生成的
- 如果需要,您可以選擇覆寫 Lineart、Depth 和 Openpose controlnets 的輸入視頻,通過取消靜音 'Override ' 組來實現,如下所示:
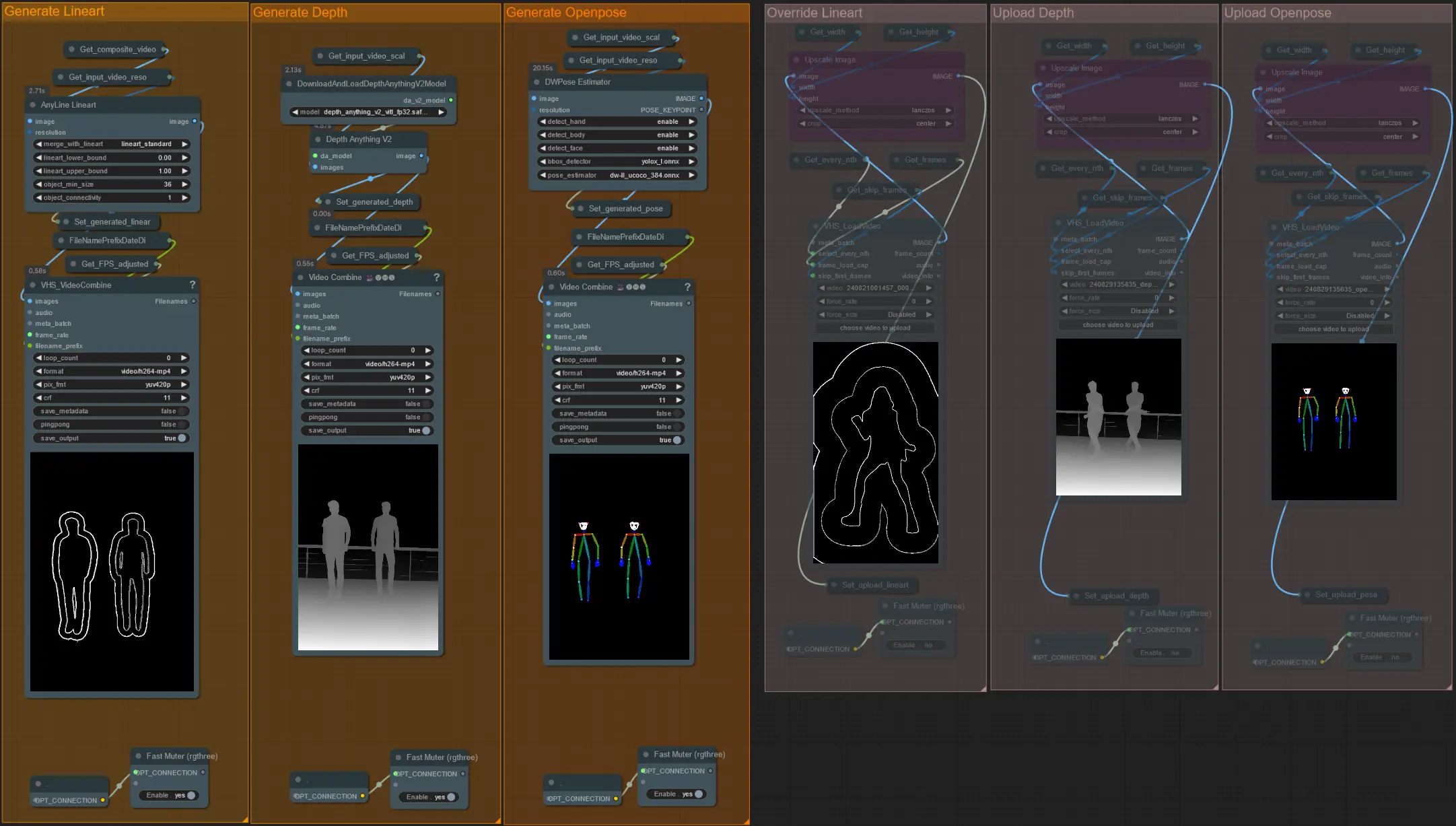
- 建議在覆寫時也靜音 'Generate' 組以節省處理時間。
提示:
- 繞過 Ksampler 並開始使用您的完整輸入視頻進行渲染。 一旦所有預處理器視頻生成完畢,保存並上傳到相應的覆寫中。 從現在起,當測試工作流程時,您不必等待每個預處理器視頻單獨生成。
取樣器#
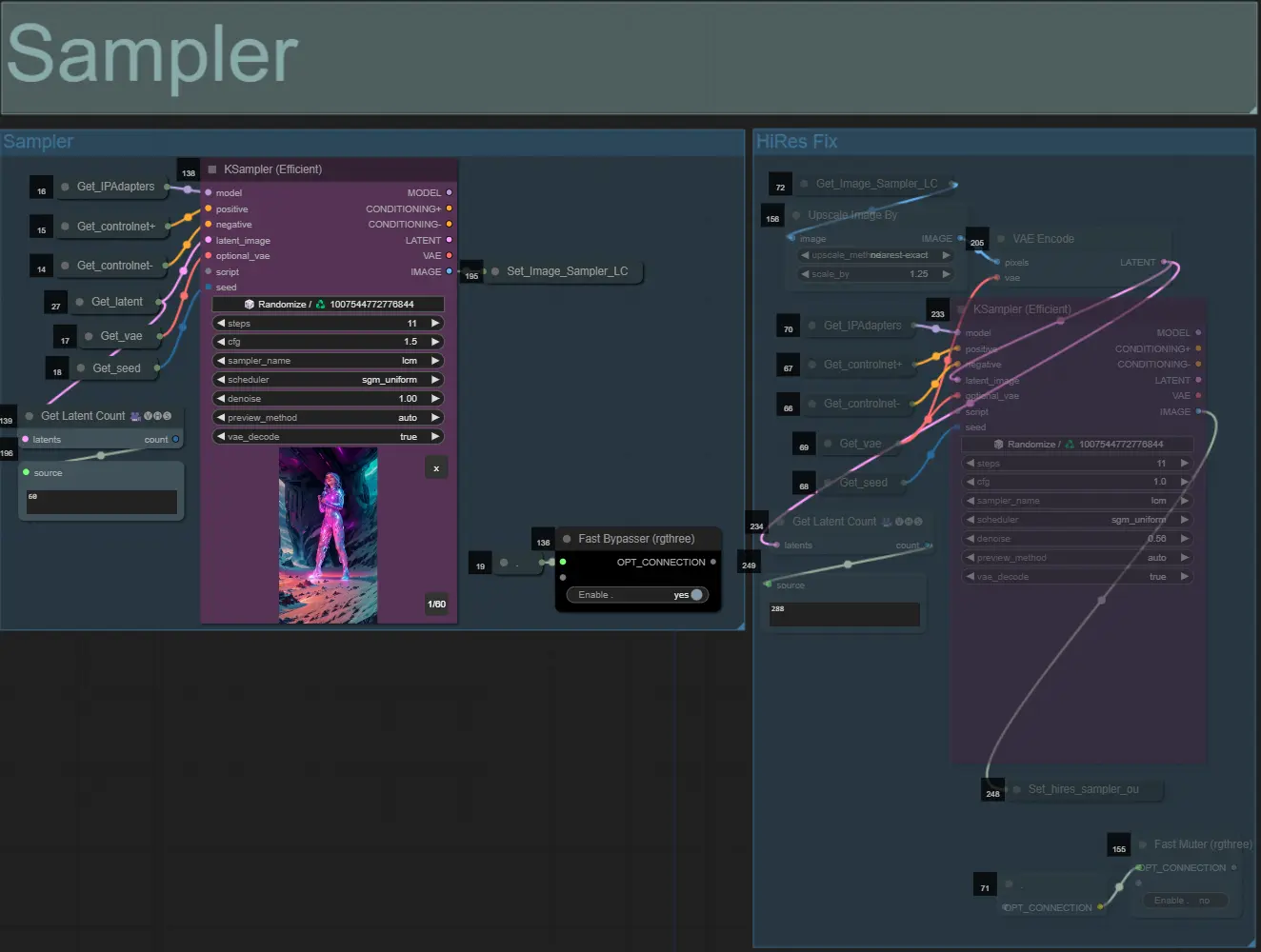
- 默認情況下,HiRes Fix 取樣器組將被靜音以節省測試時的處理時間
- 我建議在嘗試實驗擴張面具設置時也繞過取樣器組以節省時間。
- 在最終渲染時,您可以取消靜音 HiRes Fix 組,這將放大並增加最終結果的細節。
輸出#

- 有兩個輸出組:左邊是標準取樣器輸出,右邊是 HiRes Fix 取樣器輸出。
關於作者#
Akatz AI:
- 網站:https://akatz.ai
- http://patreon.com/Akatz
- https://civitai.com/user/akatz
- https://www.youtube.com/@akatz_ai
- https://www.instagram.com/akatz.ai/
- https://www.tiktok.com/@akatz_ai
- https://x.com/akatz_ai
- https://github.com/akatz-ai
聯繫方式:
- 電子郵件:akatz.hello@gmail.com
