
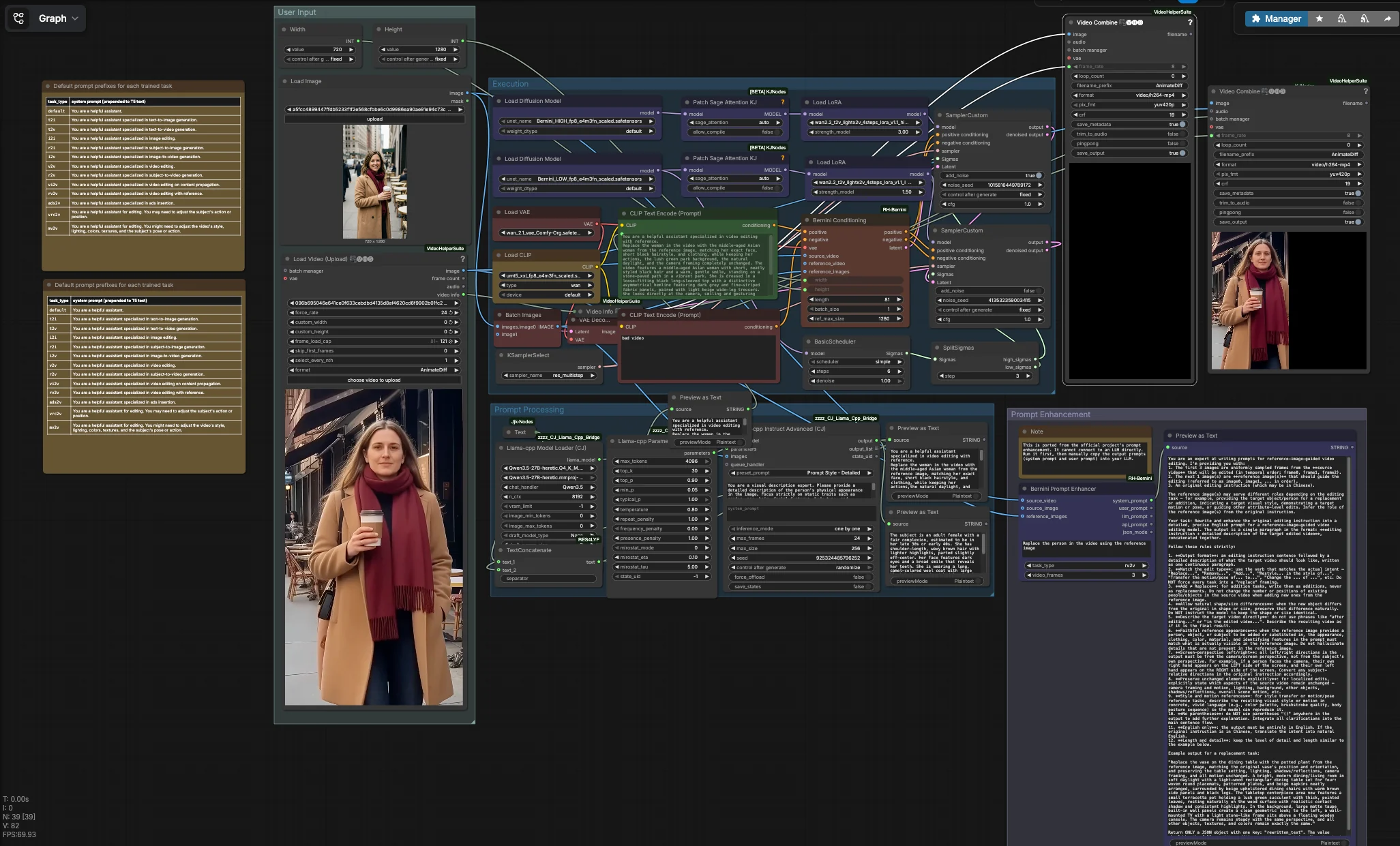
Bernini 多模態影片生成和編輯工作流程#
此 Bernini 多模態影片生成和編輯工作流程是一個即用型 ComfyUI 管道,適用於身份識別、參考導向影片編輯和影片轉影片轉換。它結合源影片、一個或多個參考圖像和聚焦提示,以在替換或重新設計主體的同時保留運動和相機行為。該工作流程將 Bernini 的高低擴散骨幹與 Wan 風格文本編碼、Bernini 兼容的 VAE、LightX2V LoRA 和 Bernini 特定條件結合,以確保結果在每一幀中保持一致。
為在 ComfyUI 中評估 Bernini 的創作者和研究人員而設計,該工作流程在角色替換、運動保留編輯、模仿和相機感知短片生成方面表現出色。它導出一個編輯的 MP4 以及可選的並排比較,方便審查您的提示和參考集的影響。在整個此 README 中,Bernini 多模態影片生成和編輯工作流程一詞指的是這個端到端圖表。
Comfyui Bernini 多模態影片生成和編輯工作流程中的關鍵模型#
- ByteDance Bernini 擴散模型家族(高和低骨幹)。提供在雙階段計劃中使用的核心去噪網絡:高模型在較強噪聲下處理結構,而低模型則細化細節和時間一致性。參考權重和說明請參見模型中心:ByteDance/Bernini。
- Wan 文本編碼器 (umT5-XXL)。一個 Wan 風格的 T5 編碼器,將您的指令轉化為 Bernini 的條件;通過 CLIP 兼容界面在 ComfyUI 中暴露。適合 ComfyUI 的資產可在此獲得:Kijai/WanVideo_comfy_fp8_scaled。
- Wan 2.1 VAE。執行潛在解碼,將去噪潛在變量轉化為具有與 Wan/Bernini 訓練匹配的色彩保真度的影片幀。同一資產包中包含一個 ComfyUI 準備好的 VAE:Kijai/WanVideo_comfy_fp8_scaled。
- LightX2V LoRA 配對 (high_noise 和 low_noise)。輕量級適配器,引導 Bernini 在保持每幀參考身份的同時實現穩定運動。提供的 FP8 LoRA 權重與此工作流程中使用的雙階段取樣對齊,並與上面的 Bernini 資產一起打包:Kijai/WanVideo_comfy_fp8_scaled。
如何使用 Comfyui Bernini 多模態影片生成和編輯工作流程#
此工作流程有四個協調組。您提供一個源影片和一個或多個參考圖像,塑造指令文本,然後執行組運行兩階段 Bernini 通過,解碼為幀並組裝您的輸出影片。並行實用程序可以生成 LLM 協助的提示寫作的支架系統和用戶提示。
用戶輸入#
使用 VHS_LoadVideo (#90) 加載您的源影片。該節點讀取剪輯並公開其元數據,以便最終渲染繼承原始幀率,有助於保持運動感。使用 LoadImage (#31) 添加一個或多個身份參考;正面、光線充足的面孔和中性表情效果最佳。使用 Width (#109) 和 Height (#110) 設定目標尺寸,理想情況下與源長寬比匹配以避免拉伸。CLIPTextEncode (#4) 編碼的默認負面提示可壓抑低質量影片中的常見工件;如果需要,您可以進行微調。
提示處理#
如果您希望指令與參考身份精確匹配,圖形可以使用本地 LLM 總結您的參考圖像中的靜態特徵。llama_cpp_model_loader (#93) 和 llama_cpp_instruct_adv (#92) 分析由 BatchImagesNode (#74) 批處理的圖像,並返回不可變屬性(如髮型、年齡和服裝)的簡潔描述。該描述通過 TextConcatenate (#102) 與您的任務指令 JjkText (#104) 連接。結果流入 CLIPTextEncode (#3),成為 Bernini 的正面條件。預覽節點顯示組合文本,讓您在運行重負階段之前快速迭代。
提示增強#
BerniniPromptEnhancer (#60) 生成結構化的“系統”和“用戶”提示,針對所選任務類型和輸入量身定制。運行它以獲得更強的指令,您可以將其粘貼到您的 LLM 中以獲得更豐富的提示擴展;按設計它不連接到主圖中。該實用程序來自 Bernini 自定義節點包:ComfyUI-RH-Bernini。將其作為一個預寫工具來標準化與 Bernini 的條件相適應的語言。
執行#
核心路徑從加載 Bernini 的高低 UNets 開始,並為每個階段附加 LightX2V LoRA。BerniniConditioning (#34) 將您的正負編碼、VAE、源影片幀和參考圖像融合在一起,以建立 Bernini 特定的條件和與您的分辨率和幀數對齊的初始潛在。BasicScheduler (#18) 創建去噪計劃,然後 SplitSigmas (#17) 將其分為高低範圍。高取樣器 SamplerCustom (#19) 在較強噪聲下建立結構和身份,將其潛在變量傳遞給低取樣器 SamplerCustom (#15) 以進行細節和時間優化。KSamplerSelect (#27) 選擇取樣器算法,VAEDecode (#16) 將最終潛在變量轉化為幀,VHS_VideoCombine (#87) 將其渲染為繼承源幀率的 MP4。並行地,ImageConcanate (#97) 和第二個 VHS_VideoCombine (#96) 生成並排比較以便快速質量檢查。影片 I/O 和組裝由影片助手套件提供:ComfyUI-VideoHelperSuite。
Comfyui Bernini 多模態影片生成和編輯工作流程中的關鍵節點#
BerniniConditioning (#34) 通過結合您的文本編碼、VAE、源影片和參考圖像來構建 Bernini 本地條件。它還準備了起始潛在體積並處理空間和時間大小。調整 width 和 height 以匹配您的目標分辨率,並使用 length 控制生成的幀數。如果參考主體在圖像中較小,增加 ref_max_size 以便模型更好地感知身份細節。該節點是 Bernini 自定義包的一部分:ComfyUI-RH-Bernini。
LoraLoaderModelOnly (#11) 將 LightX2V high_noise LoRA 應用於高骨幹。提高其 strength_model 增加在結構階段對參考的依從性,當主體的輪廓或粗略特徵與源影片不匹配時非常有用。如果編輯變得過於僵硬或抑制自然運動,則降低它。與低階段 LoRA 配合使用以平衡保真度和流動性。
LoraLoaderModelOnly (#29) 將 LightX2V low_noise LoRA 應用於低骨幹。此 LoRA 在保持高階段設置的運動的同時,細化頭髮、皮膚和衣服等紋理。如果身份細節在幀之間漂移,稍微增加強度;如果紋理過度銳化或看起來過度擬合,則減少它。與高階段 LoRA 一起形成互補配對。
SplitSigmas (#17) 將去噪計劃分為高低範圍。較早移動分割會產生更溫和的編輯,保留更多原影片,而較晚移動則賦予高階段更大的影響力以進行更強的替換。當您更改提示或 LoRA 強度時調整分割,以便兩個階段保持平衡。此控制對於相機鎖定、運動保留編輯特別有幫助。
KSamplerSelect (#27) 選擇兩個去噪階段使用的取樣器算法。有些取樣器偏向穩定性和時間平滑性,而其他取樣器則強調細節或速度。如果看到閃爍,嘗試一個以一致性著稱的取樣器;如果需要額外的清晰度,嘗試一個注入更多變異的算法。保持相同的選擇以便兩個階段維持可預測的行為。
VHS_VideoCombine (#87) 將解碼幀編碼為最終 MP4,同時繼承 VHS_VideoInfo 報告的幀率,以便播放速度與源剪輯匹配。使用檔名控件組織運行,如果計劃審核設置,啟用元數據保存。第二個實例 (#96) 輸出並排渲染以便快速視覺比較。由 ComfyUI-VideoHelperSuite 提供。
選擇性額外功能#
- 對於身份關鍵任務,提供兩到三張高品質的參考圖像,展示一致的髮型、光線和表情。使用批量輸入將它們一起輸入。
- 保持目標長寬比接近源影片。大幅不匹配會拉伸面孔並使運動不穩定。
- 如果背景或相機漂移,加強指令中鎖定相機位置和場景的語言,並用簡潔的負面提示增強。
- 在調整 LoRA 強度或 Sigma 分割時使用並排導出。它通過使差異明顯縮短迭代時間。
- 為了更快的試驗,限制您加載的幀數,然後在對身份匹配和運動質量滿意後再放大。
此 Bernini 多模態影片生成和編輯工作流程設計為可安全編輯:從默認值開始,對指令和參考進行迭代,然後對 LoRA 強度和 Sigma 分割進行微調以適應您的主體和場景。
致謝#
此工作流程實現並基於以下作品和資源構建。我們感謝 ByteDance 提供的 Bernini,RH-RunningHub 提供的 ComfyUI-RH-Bernini,和 Kosinkadink 提供的 ComfyUI-VideoHelperSuite 的貢獻和維護。欲了解權威詳情,請參閱以下鏈接的原始文檔和存儲庫。
資源#
- RunningHub/Bernini 多模態影片生成和編輯 (ComfyUI 工作流程)
- 文檔 / 發布說明: RunningHub 工作流程參考
- RunComfy/Cloud Save 工作流程
- 文檔 / 發布說明: RunComfy Cloud Save 工作流程
- ByteDance/Bernini-R
- GitHub: bytedance/Bernini
- Hugging Face: ByteDance/Bernini-R
- arXiv: arXiv:2605.22344
- 文檔 / 發布說明: ByteDance Bernini 模型來源
- Kijai/WanVideo_comfy_fp8_scaled (Bernini 資產)
- Hugging Face: Kijai/WanVideo_comfy_fp8_scaled
- 文檔 / 發布說明: Kijai Bernini ComfyUI fp8 模型資產
- RH-RunningHub/ComfyUI-RH-Bernini
- GitHub: RH-RunningHub/ComfyUI-RH-Bernini
- 文檔 / 發布說明: RunComfy Bernini 自定義節點
- Kosinkadink/ComfyUI-VideoHelperSuite
- GitHub: Kosinkadink/ComfyUI-VideoHelperSuite
- 文檔 / 發布說明: ComfyUI 影片助手套件
注意:使用引用的模型、數據集和代碼需遵守其作者和維護者提供的各自許可和條款。
