
ACE-Step 1.5XL Base 文本到音樂:ComfyUI 的提示到歌曲工作流程#
此工作流程使用 ACE-Step 1.5XL Base 擴散家族將自然語言描述轉換為完成的音頻。它將基本模型與其 ACE Step VAE 和雙 Qwen 文本編碼器配對,以確保結果堅定地處於音樂領域,而不是 TTS 或語音。如果您想要具有可預測結構、節奏和樂器的提示驅動 AI 音樂,這個 ACE-Step 1.5XL Base 文本到音樂管道是一個專注的最小設置,能夠快速將您的想法轉換為 MP3。
專為製作人、音效設計師和創作者設計,該圖強調透明度:選擇模型,設置持續時間,撰寫音樂提示,然後生成並保存。ACE-Step 1.5XL Base 文本到音樂工作流程足夠緊湊以進行快速迭代,同時保持對詳細編排、調性和節奏的表達能力。
Comfyui ACE-Step 1.5XL Base 文本到音樂工作流程中的關鍵模型#
- ACE-Step 1.5 XL Base (bf16) 擴散模型。生成的骨幹將音頻潛在變成連貫的音樂短語和紋理。模型文件
- ACE Step 1.5 VAE。成對的變分自動編碼器,在潛在空間和波形域之間進行編碼/解碼,保留音色和混音平衡。模型文件
- Qwen 4B ACE15 文本編碼器。為 ACE 改編的大型文本編碼器,從提示中捕捉豐富的音樂語義、結構和編排提示。模型文件
- Qwen 0.6B ACE15 文本編碼器。輕量級的 ACE 適應編碼器,優先考慮速度和資源效率,同時保留強大的提示理解力。模型文件
如何使用 Comfyui ACE-Step 1.5XL Base 文本到音樂工作流程#
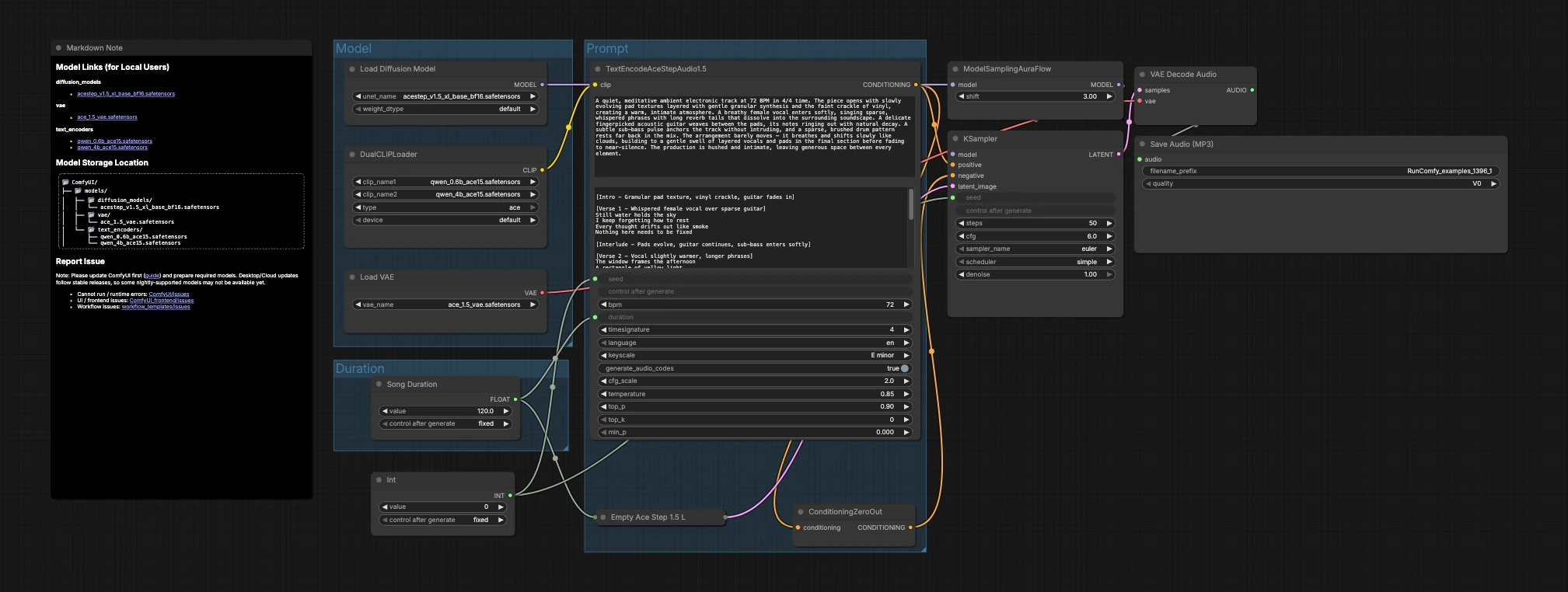
該圖分為三組,流入生成和導出:模型、持續時間和提示。您加載模型,選擇目標長度,描述音樂,然後取樣器創建潛在變量,VAE 將其解碼為音頻。
模型#
此組加載核心資產。UNETLoader (#104) 選擇 ACE-Step 1.5 XL Base 擴散檢查點,VAELoader (#106) 加載匹配的 ACE Step 1.5 VAE,以便解碼質量與訓練一致。DualCLIPLoader (#105) 將兩個 Qwen ACE15 編碼器引入工作流程,工作流程將它們結合使用,以便豐富的文本提示轉化為強大的音樂條件。
持續時間#
在這裡您決定作品的長度。Song Duration (#99) 設置以秒為單位的目標長度,並向前推進,以便潛在畫布和文本條件保持一致。PrimitiveInt (#109) 提供一個種子,讓您鎖定確切的結果以便重現,或改變它以探索替代版本。
提示#
這就是語言變成音樂的地方。在 TextEncodeAceStepAudio1.5 (#94) 中撰寫您的描述,包括有用的音樂元數據,如節奏(BPM)、節拍、調性、樂器編排、聲樂存在和混音說明。該節點發出正面條件;ConditioningZeroOut (#47) 提供中立的負面路徑,以便生成保持專注於您的描述。EmptyAceStep1.5LatentAudio (#98) 為選擇的持續時間初始化潛在音頻時間線。ModelSamplingAuraFlow (#78) 將基本模型適應於 ACE-Step 音頻的調度器。KSampler (#3) 結合模型、條件、潛在變量和種子生成音樂潛在變量。VAEDecodeAudio (#18) 將潛在變量轉換回波形,SaveAudioMP3 (#107) 將結果寫入準備分享的 MP3 文件。
Comfyui ACE-Step 1.5XL Base 文本到音樂工作流程中的關鍵節點#
TextEncodeAceStepAudio1.5 (#94)#
將您的提示轉換為擴散模型可以遵循的條件。它接受音樂細節,如節奏、時間簽名、調性、編排說明、樂器、語言和可選的聲樂意圖。為了獲得最佳效果,請具體描述流派、感覺和混音位置,並保持結構提示簡潔,以便模型能夠在請求的持續時間內保持連貫性。
EmptyAceStep1.5LatentAudio (#98)#
為作品創建潛在音頻“畫布”。將其秒數與您在 Song Duration (#99) 中設置的時間匹配,並在文本編碼器中引用以避免不必要的截斷或填充。更長的畫布邀請更漸進的發展,而較短的畫布適合循環、提示和短音。
ModelSamplingAuraFlow (#78)#
配置專為 ACE-Step 音頻設計的取樣策略。按提供的方式使用,以獲得穩定的結果;只有在您有特定的調度器偏好時才進行調整,因為它會與 KSampler (#3) 中的步數和指導互動。
KSampler (#3)#
執行將條件轉化為音頻潛在變量的去噪。這裡的關鍵杠桿是取樣器類型、步數和種子。增加步數來細化細節,但會消耗時間;在比較提示時保持種子固定,以便您可以將變化歸因於文本而非隨機性。
DualCLIPLoader (#105)#
加載兩個 Qwen ACE15 文本編碼器。如果您可以訪問兩者,請先啟用 4B 編碼器以獲得更豐富的語言理解;當您需要更快的迭代或更低的內存使用時,切換到 0.6B 變體。在評估微調提示時,保持編碼器選擇一致。
ConditioningZeroOut (#47)#
提供中立的負面路徑。如果您想抑制特定的工件或偏離語音內容,可以用實際的負面提示節點替換此節點;否則零化的負面保持 ACE-Step 1.5XL Base 文本到音樂生成專注於您的正面描述。
可選附加功能#
- 以緊湊的配方開始提示:流派 + 情緒 + 節奏 + 節拍 + 調性 + 樂器 + 編排 + 混音說明。
- 使用明確的音樂動詞和角色(主音、墊音、低音、打擊樂器),以便模型在混音中分配空間,避免語音內容。
- 在 A/B 測試提示時固定種子,然後改變種子以探索獲勝想法的替代表演。
- 讓
Song Duration(#99)、TextEncodeAceStepAudio1.5(#94) 和EmptyAceStep1.5LatentAudio(#98) 的持續時間保持一致,以獲得可預測的措辭。 - 選擇 Qwen 4B 以獲得更豐富的提示理解力,或選擇 0.6B 以獲得速度;在迭代時保持您的選擇不變,以便進行公平的比較。
感謝#
此工作流程實現並建立在以下作品和資源之上。我們感謝 Comfy.org 提供 audio_ace_step1_5_xl_base 工作流程,感謝 Comfy-Org 提供 ACE Step 1.5 XL Base 擴散模型和 ACE Step 1.5 VAE,感謝 Qwen 團隊提供 0.6B 和 4B ACE15 文本編碼器的貢獻和維護。欲了解詳細內容,請參閱以下鏈接的原始文檔和存儲庫。
資源#
- Comfy.org/Workflow source page
- Docs / Release Notes: audio_ace_step1_5_xl_base workflow page
- Comfy-Org/ACE Step 1.5 XL Base diffusion model
- Hugging Face: acestep_v1.5_xl_base_bf16.safetensors
- Comfy-Org/ACE Step 1.5 VAE
- Hugging Face: ace_1.5_vae.safetensors
- Comfy-Org/Qwen 0.6B ACE15 text encoder
- Hugging Face: qwen_0.6b_ace15.safetensors
- Comfy-Org/Qwen 4B ACE15 text encoder
- Hugging Face: qwen_4b_ace15.safetensors
注意:使用引用的模型、數據集和代碼需遵循其作者和維護者提供的相應許可和條款。