







Z Image Turbo for ComfyUI: 快速文本到图像,几乎实时迭代#
这个工作流将Z Image Turbo引入ComfyUI,因此您可以通过很少的步骤和紧密的提示遵循生成高分辨率、照片级真实感的视觉效果。专为需要快速一致渲染的概念艺术、广告设计稿、互动媒体和快速A/B测试的创作者设计。
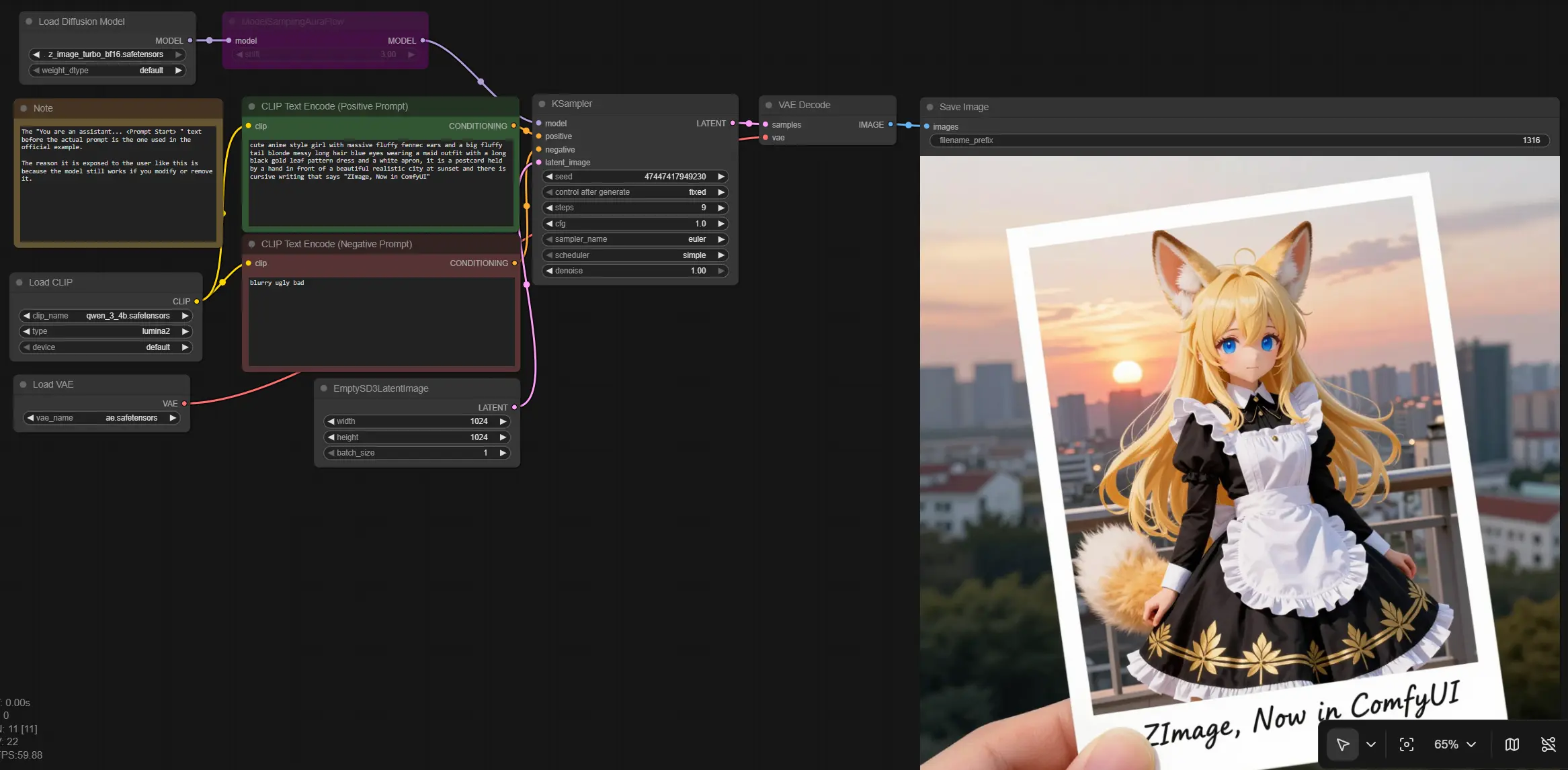
流程图从文本提示到图像的路径很简洁:加载Z Image模型和支持组件,编码正面和负面提示,创建潜在画布,使用AuraFlow计划采样,然后解码为RGB以保存。结果是一个简化的Z Image管道,侧重于速度而不牺牲细节。
Comfyui Z Image工作流中的关键模型#
- Tongyi-MAI Z Image Turbo。主要生成器,以精简、高效的方式进行去噪。它以照片级真实感、清晰纹理和忠实构图为目标,同时保持低延迟。Model card
- Qwen 4B文本编码器 (qwen_3_4b.safetensors)。为模型提供语言条件,使您的提示中的风格、主题和构图指导去噪轨迹。
- Autoencoder AE (ae.safetensors)。在潜在空间和像素之间进行翻译,以便最终的Z Image结果可以查看和导出。
如何使用Comfyui Z Image工作流#
在高层次上,路径从提示到条件,通过Z Image采样,然后解码为图像。节点被分组为阶段以保持操作简单。
模型加载器:UNETLoader (#16), CLIPLoader (#18), VAELoader (#17)#
此阶段加载核心Z Image Turbo检查点、文本编码器和自动编码器。如果有的话,选择BF16检查点,因为它在消费者GPU上平衡了速度和质量。CLIP风格编码器确保您的措辞控制场景和风格。AE用于在采样完成后将潜在转回RGB。
提示:CLIP Text Encode (Positive Prompt) (#6) 和 CLIP Text Encode (Negative Prompt) (#7)#
在正面提示中使用具体名词、风格提示、相机提示和光照写下您想要的内容。使用负面提示抑制常见的伪影,如模糊或不需要的物体。如果您看到提示前缀,例如官方示例中的说明标题,您可以保留、编辑或删除它,工作流仍将运行。这些编码器共同产生在采样期间引导Z Image的条件。
潜在和调度器:EmptySD3LatentImage (#13) 和 ModelSamplingAuraFlow (#11)#
通过设置潜在画布选择输出大小。调度器节点将模型切换到与步骤高效精简模型良好对齐的AuraFlow风格采样策略。这在低步骤计数时保持轨迹稳定,同时保留细节。一旦设置了画布和计划,管道就准备好去噪。
采样:KSampler (#3)#
此节点使用加载的Z Image模型、选定的调度器和您的提示条件执行实际去噪。根据需要调整采样器类型和步骤计数以在速度和细节之间进行权衡。指导比例控制相对于先前的提示强度;适中的值通常在保真度和创意变化之间给出最佳平衡。随机化种子以进行探索或固定以获得可重复的结果。
解码和保存:VAEDecode (#8) 和 SaveImage (#9)#
在采样后,AE将潜在解码为图像。保存节点将文件写入您的输出目录,以便您可以比较迭代或将结果输入下游任务。如果计划放大或后处理,请保持解码在您期望的工作分辨率并导出无损格式以获得最佳质量保留。
Comfyui Z Image工作流中的关键节点#
UNETLoader (#16)#
加载Z Image Turbo检查点 (z_image_turbo_bf16.safetensors)。使用此选项在精度变体或更新权重可用时进行切换。如果希望种子和提示保持可比性,请在会话中保持模型一致。更改基础模型将改变外观、颜色响应和细节密度。
ModelSamplingAuraFlow (#11)#
将采样策略设置为适用于快速收敛的AuraFlow风格计划。这是使Z Image在低步骤计数时高效的关键,同时保留细节和连贯性。如果您稍后更换计划,请重新检查步骤计数和指导以保持类似的输出特征。
KSampler (#3)#
控制采样器算法、步骤、指导和种子。对快速构思使用较少的步骤,仅在需要更多微观细节或更严格的提示遵循时增加。不同的采样器偏好不同的外观;尝试几个,并在比较结果时保持管道的其余部分不变。
CLIP Text Encode (Positive Prompt) (#6)#
编码驱动Z Image的创意意图。专注于主题、媒介、镜头、光照、构图以及任何品牌或设计限制。与负面提示节点配对,将图像推向您的目标外观,同时过滤已知的伪影。
可选额外功能#
- 在第一次通过中使用方形或接近方形的分辨率,然后在锁定构图后调整纵横比。
- 保持可重用提示片段的库,用于主题、镜头和光照,以加快跨项目的迭代速度。
- 为了保持一致的艺术方向,固定种子并仅在每次迭代中改变一个因素,如风格标签或相机提示。
- 如果输出感觉过于受控,稍微减少指导或从正面提示中删除过于直白的短语。
- 在为下游编辑准备素材时,导出无损PNG并保留提示、种子和分辨率的记录,以及每个Z Image渲染。
致谢#
此工作流实现并构建在以下工作和资源之上。我们对Tongyi-MAI的Z-Image-Turbo的贡献和维护表示感谢。有关权威详细信息,请参考下面链接的原始文档和存储库。
资源#
- Tongyi-MAI/Z-Image-Turbo
- Hugging Face: Tongyi-MAI/Z-Image-Turbo
注意:引用的模型、数据集和代码的使用受其作者和维护者提供的相应许可证和条款的约束。