
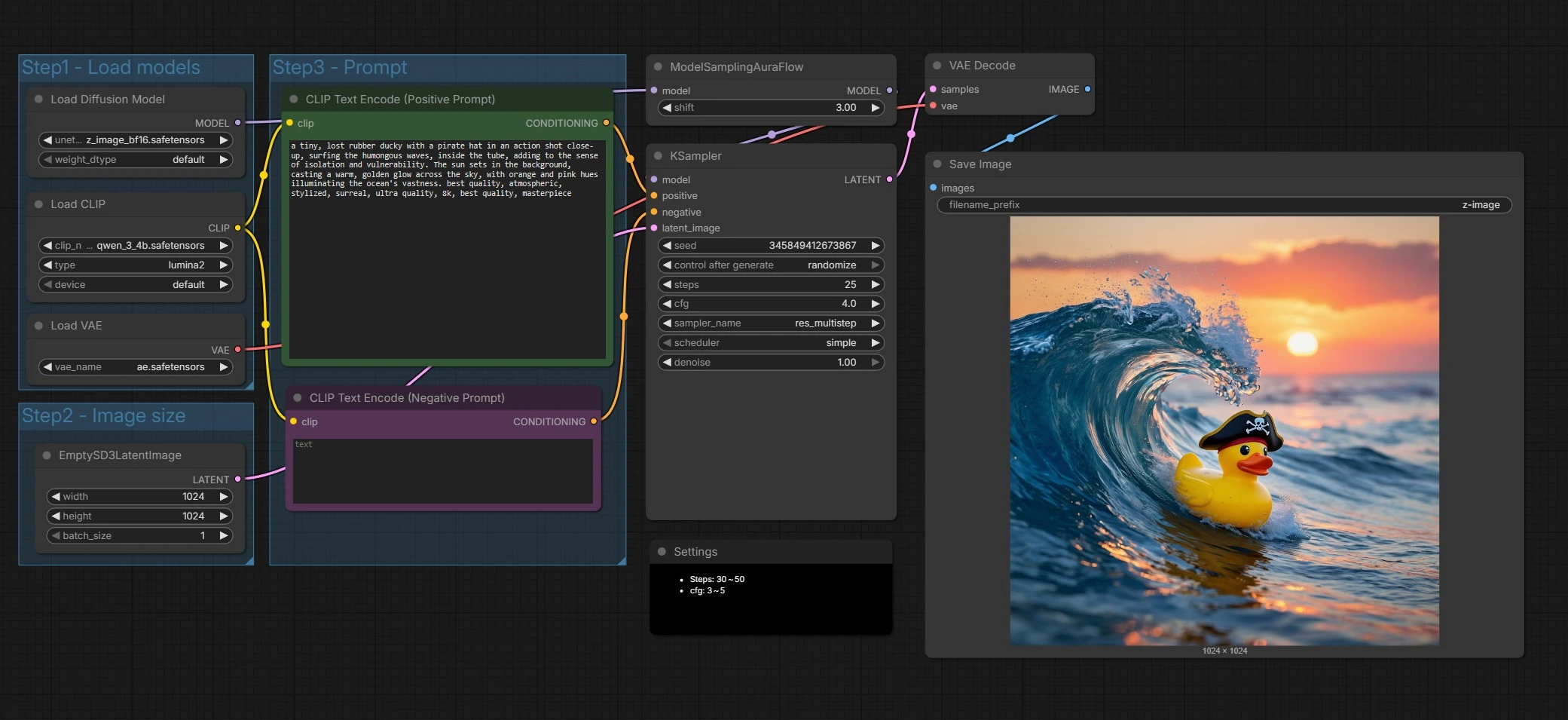
















ComfyUI的Z-Image文本到图像工作流程#
此ComfyUI工作流程展示了Z-Image,一种为快速高保真图像生成设计的下一代扩散变压器。它基于可扩展的单流架构构建,约有60亿参数,Z-Image在逼真性、强提示遵循性和双语文本渲染之间取得了平衡。
开箱即用,图形设置为Z-Image Base以在常见GPU上最大化质量的同时保持高效。当速度很重要时,它也能很好地与Z-Image Turbo变体配合,其结构使其易于扩展至Z-Image Edit以进行图像到图像任务。如果您需要一个可靠的、最小的图形,将清晰的提示转换为干净的结果,这个Z-Image工作流程是一个坚实的起点。
Comfyui Z-Image工作流程中的关键模型#
- Z-Image Base扩散变压器 (bf16)。核心生成器,使用Z-Image的单流拓扑和提示控制将潜在噪声转化为图像。模型页面 • bf16权重
- Qwen 3 4B文本编码器。为Z-Image编码提示,具有强大的双语覆盖和清晰的标记化文本渲染。编码器权重
- Z-Image自动编码器VAE。在像素空间和Z-Image潜在空间之间压缩和重建图像。VAE权重
如何使用Comfyui Z-Image工作流程#
从高层次上看,图形加载Z-Image组件,准备潜在画布,编码您的正面和负面提示,运行为Z-Image调整的采样器,然后解码并保存结果。您主要提供提示并选择输出大小,其他部分已为合理的默认值配置。
第一步 - 加载模型#
此组初始化Z-Image UNet、Qwen 3 4B文本编码器和VAE,使所有组件对齐。UNETLoader (#66) 默认指向Z-Image Base,偏向于保真度和编辑余地。CLIPLoader (#62) 引入处理多语言提示和文本标记的Qwen编码器。VAELoader (#63) 设置稍后用于解码的自动编码器。如果您想尝试Z-Image Turbo以获得更快的草稿,可以在此处交换权重。
第二步 - 图像大小#
此组通过EmptySD3LatentImage (#68) 设置潜在画布。选择您想要生成的宽度和高度,并考虑构图的纵横比。Z-Image在常见创意尺寸下表现良好,因此选择与您的故事板或交付格式匹配的尺寸。较大的尺寸增加细节和计算成本。
第三步 - 提示#
在这里您撰写您的故事。CLIP Text Encode (Positive Prompt) (#67) 节点获取您的场景描述和风格指令以供Z-Image使用。CLIP Text Encode (Negative Prompt) (#71) 帮助避免伪影或不需要的元素。Z-Image调整为双语文本渲染,因此您可以在需要时直接在提示中包含多种语言的文本内容。保持提示具体且视觉化以获得最一致的结果。
采样和去噪#
ModelSamplingAuraFlow (#70) 应用与Z-Image的单流设计一致的采样策略,然后KSampler (#69) 驱动去噪过程,将噪声转换为与您的提示匹配的图像。采样器结合您的正面和负面条件与潜在画布迭代地细化结构和细节。您可以通过调整采样器设置来在此处权衡速度与质量,如下所述。在这个阶段,Z-Image的提示遵循性和文本清晰度真正显现。
解码和保存#
VAEDecode (#65) 将最终潜在转换为RGB图像。SaveImage (#9) 使用节点中设置的前缀写入文件,以便您的Z-Image输出易于查找和组织。这完成了从提示到像素的完整过程。
Comfyui Z-Image工作流程中的关键节点#
UNETLoader (#66)#
加载执行实际去噪的Z-Image骨干。在探索速度或编辑用例时,在此处切换到另一个Z-Image变体。如果您更改变体,请保持编码器和VAE兼容以避免颜色或对比度偏移。
CLIP Text Encode (Positive Prompt) (#67)#
为Z-Image编码主要描述。撰写简洁、视觉化的短语,指定主体、照明、相机、情绪和任何在图像上的文本。对于文本渲染,将所需的单词放在引号中,并保持简短以获得最佳可读性。
CLIP Text Encode (Negative Prompt) (#71)#
定义要避免的内容,以便Z-Image可以专注于正确的细节。用它来抑制模糊、多余的肢体、混乱的排版或风格不符的元素。保持简短和主题相关,以免过度限制构图。
EmptySD3LatentImage (#68)#
创建Z-Image将绘制的潜在画布。选择适合最终用途的尺寸,并保持它们为64像素的倍数以便高效的内存使用。更宽或更高的画布会影响构图和透视,因此相应地调整提示。
ModelSamplingAuraFlow (#70)#
选择与Z-Image的训练和潜在空间匹配的采样器预设。除非您正在测试替代采样器,否则您很少需要更改此设置。保持原样以获得稳定、无伪影的结果。
KSampler (#69)#
控制Z-Image的质量-速度权衡。增加steps以获得更多细节和稳定性,减少以获得更快的草稿。保持cfg适中以平衡提示遵从性和自然纹理;此图中的典型值为steps: 30至50和cfg: 3至5。设置固定的seed以实现可重现性或随机化以探索变体。
VAEDecode (#65)#
将Z-Image的最终潜在转换为RGB图像。如果您更改VAE,请保持其与模型系列匹配以保持颜色准确性和清晰度。
SaveImage (#9)#
使用清晰的文件名前缀写入结果,以便Z-Image输出易于分类。调整前缀以区分实验、模型变体或纵横比。
可选附加项#
- 使用Z-Image Turbo进行快速构思,然后切换回Z-Image Base并提高步骤以进行最终渲染。
- 对于双语提示和图像上的文本,在提示中保持措辞简短且高对比度,以帮助Z-Image渲染清晰的排版。
- 在比较小的提示编辑时锁定种子,以便差异反映您的更改而不是新噪声。
- 如果看到过饱和或光晕,稍微降低
cfg或加强负提示以恢复平衡。
致谢#
此工作流程实现并构建在以下作品和资源的基础上。我们感谢Comfy-Org为Z-Image Day-0 ComfyUI工作流程模板的贡献和维护。有关权威细节,请参阅下方链接的原始文档和存储库。
资源#
- Comfy-Org/Z-Image Day-0在ComfyUI中的支持
- GitHub: Comfy-Org/workflow_templates
- 文档/发布说明: 来源
注意:使用参考的模型、数据集和代码时,需遵循其作者和维护者提供的相应许可证和条款。
