
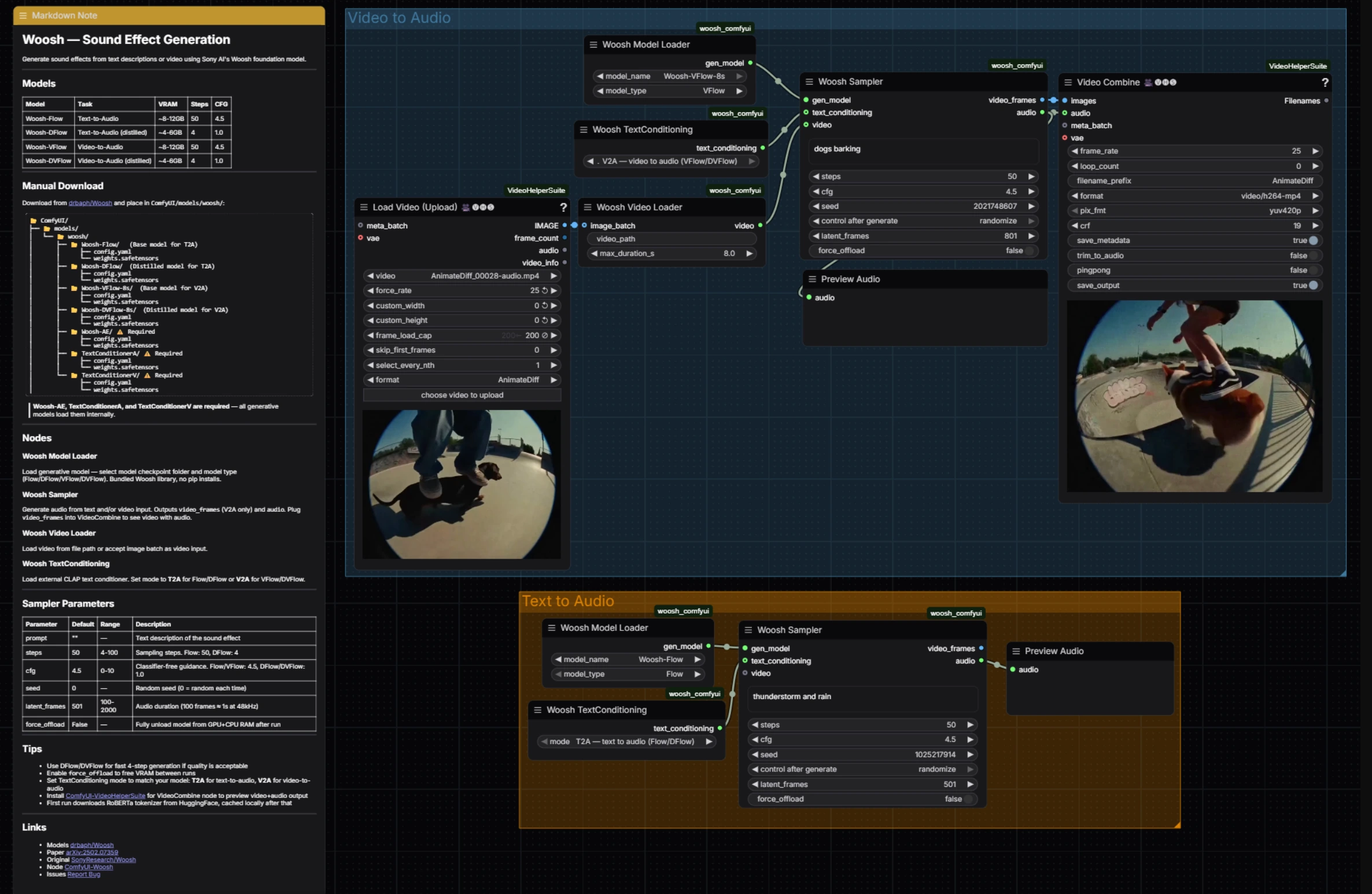
Woosh音效生成:在ComfyUI中基于提示和视频的音频生成#
Woosh音效生成是一个ComfyUI工作流程,通过Sony Research的Woosh基础模型,将文本提示或视频剪辑转化为抛光的音效。它为需要基于提示的Foley、紧密匹配视频的音效设计,以及在高质量和快速蒸馏版本之间快速切换的创作者而构建。
该工作流程展示了两类Woosh模型:用于text-to-audio的Flow/DFlow和用于video-to-audio的VFlow/DVFlow。一个共享的采样器驱动两个路径的生成,输出音频用于即时预览,并在视频路径中提供帧预览,这些帧被重新组合以快速生成日常。其背后依赖于官方的ComfyUI Woosh节点和VideoHelperSuite,以实现无缝的视频IO,从而使Woosh音效生成保持快速简单,同时保持灵活性。参考:SonyResearch/Woosh,drbaph/Woosh on Hugging Face,paper,ComfyUI-Woosh,ComfyUI-VideoHelperSuite。
Comfyui Woosh音效生成工作流程中的关键模型#
- Sony Research Woosh — Flow:用于高保真Foley和环境音的核心text-to-audio生成器,经过流匹配目标训练。参见SonyResearch/Woosh和paper。
- Sony Research Woosh — DFlow:优化速度的蒸馏text-to-audio模型,采样步骤显著减少,适合快速迭代。权重可通过drbaph/Woosh获得。
- Sony Research Woosh — VFlow‑8s:视频条件生成器,将音频起始点和纹理与视觉运动提示同步,用于video-to-audio。参见SonyResearch/Woosh。
- Sony Research Woosh — DVFlow‑8s:用于实时精简工作流程和快速预览的蒸馏video-to-audio模型。权重:drbaph/Woosh。
- Woosh‑AE:用于从模型潜在空间重建波形的音频自动编码器;所有生成器均需要。权重:drbaph/Woosh。
- TextConditionerA和TextConditionerV:文本条件模块,适当地嵌入提示用于text-to-audio或video-to-audio运行。详细信息和用法记录在ComfyUI-Woosh和paper中。
如何使用Comfyui Woosh音效生成工作流程#
该工作流程有两个可独立运行的并行组:Video to Audio用于视觉匹配的音效设计,Text to Audio用于纯基于提示的Foley。两者在相同的采样器逻辑和快速音频预览上汇聚,使Woosh音效生成无论输入如何都能保持一致。
Video to Audio#
Video to Audio组加载一个剪辑,对齐帧和条件,然后生成同步声音。首先将您的剪辑输入到VHS_LoadVideo(#34);它以您选择的速率提取帧,以便下游节点看到一个干净、界定的序列。这些帧由WooshLoadVideo(#37)打包为视频条件流,它标准化持续时间,以便生成器接收稳定的窗口。
在WooshLoadFlow(#7)中选择一个视频条件模型,通常是VFlow用于保真度或DVFlow用于速度。在采样器中提供一个简短的描述性提示(用于风格或意图),并将WooshTextEncode(#19)设置为V2A,以便文本以正确的条件分支嵌入。运行WooshSample(#38)合成音频;它输出给PreviewAudio(#9)的audio和流入VHS_VideoCombine(#33)的video_frames用于快速拼接预览,使Woosh音效生成在编辑审查中保持紧密。
Text to Audio#
Text to Audio组专注于干净的提示驱动生成。在WooshLoadFlow(#40)中选择一个模型,当您需要最高质量时使用Flow,当您需要非常快速的迭代通过时使用DFlow。将WooshTextEncode(#41)设置为T2A,以便您的提示被嵌入用于仅文本生成。在WooshSample(#39)中输入您的描述并执行;结果被发送到PreviewAudio(#43)以便即时收听。当您在创建库或在没有画面的情况下分层效果时,此路径保持Woosh音效生成的轻便。
Comfyui Woosh音效生成工作流程中的关键节点#
WooshSample (#38)#
用于视频条件生成的中心采样器。调整提示以引导风格和起始点,然后调整steps以实现质量与速度的权衡(运行DVFlow时使用较少的步骤)。cfg控制提示的依从性,latent_frames确定输出长度以匹配或故意偏移剪辑。设置seed以重现拍摄,并在长时间运行之间需要清理内存时启用force_offload。节点实现和行为遵循官方ComfyUI-Woosh。
WooshSample (#39)#
用于text-to-audio的采样器,具有相同的控制和行为,减去视频流。快速构思时选择DFlow和低steps;在最终阶段切换到Flow并提高steps以获得细节。保持cfg适中以获得自然纹理,稍微提高以获得风格化、提示锁定的结果。使用latent_frames在构建库或DAW时间线的资产时精确设置持续时间。
WooshLoadFlow (#7)#
用于Video to Audio路径的模型选择器。选择VFlow以获得与运动最高保真度的对齐,或在需要近实时预览时选择DVFlow。确保WooshTextEncode设置为V2A,以便嵌入与所选模型系列匹配。参见drbaph/Woosh了解模型变体。
WooshLoadFlow (#40)#
用于Text to Audio路径的模型选择器。选择Flow以获得丰富的细节和更广泛的纹理多样性,或选择DFlow以快速迭代,步骤最少。将其与WooshTextEncode在T2A模式下配对,以避免条件不匹配。节点行为和选项跟踪官方ComfyUI-Woosh。
VHS_VideoCombine (#33)#
用于将生成的audio与采样器的video_frames预览组合在一起以生成可审核的剪辑的实用程序。使用它来识别同步、评估过渡,并在不离开ComfyUI的情况下共享日常。属于ComfyUI-VideoHelperSuite。
可选附加功能#
- 使用DVFlow/DFlow进行快速侦察,通过后切换到VFlow/Flow以在Woosh音效生成必须发光时进行最终处理。
- 将输入剪辑保持在所选模型的窗口内(例如,8秒的VFlow变体),并在重叠的块中处理较长的场景,您可以进行交叉淡入。
- 维护从
VHS_LoadVideo到VHS_VideoCombine的一致帧速率,以减少音频和画面之间的漂移。 - 对于提示,将动作词与纹理和声学背景配对(例如,“在混凝土楼梯间的快速金属嗖声”)以获得可预测的结果。
- 在采样器中开启
force_offload,如果GPU内存紧张,在重负荷运行之间。
致谢#
此工作流程实现并构建在以下作品和资源之上。我们感谢Sony Research对Woosh(项目和论文)的贡献,感谢Saganaki22对ComfyUI-Woosh(ComfyUI节点)的贡献,以及感谢Kosinkadink对ComfyUI-VideoHelperSuite的贡献和维护。有关权威详细信息,请参阅下面链接的原始文档和资源库。
资源#
- Saganaki22/ComfyUI-Woosh
- GitHub: Saganaki22/ComfyUI-Woosh
- drbaph/Woosh
- Hugging Face: drbaph/Woosh
- SonyResearch/Woosh
- GitHub: SonyResearch/Woosh
- Sony Research/Woosh (paper)
- arXiv: 2502.07359
- Kosinkadink/ComfyUI-VideoHelperSuite
注意:引用的模型、数据集和代码的使用受其作者和维护者提供的各自许可和条款的约束。
