
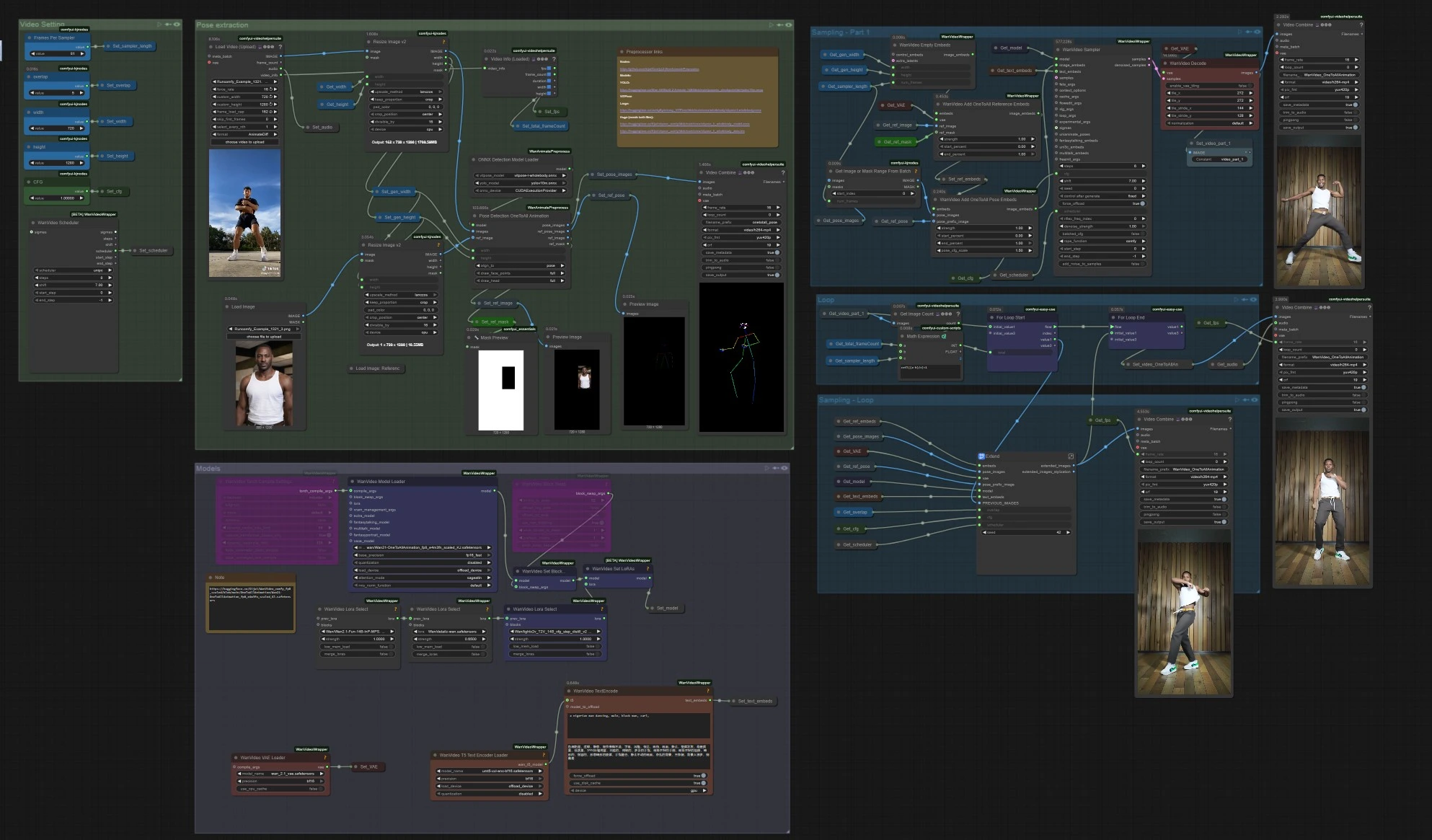
一对多动画:在ComfyUI中进行长形式、姿势对齐的角色视频#
此一对多动画工作流程将短参考片段转变为扩展的高保真视频,同时保持整个序列的一致动作、姿势对齐和角色身份。围绕Wan 2.1视频生成,采用全身姿势指导和滑动窗口扩展器,非常适合需要单一外观跟随复杂运动的舞蹈、表演捕捉和叙述镜头。
如果您是一位需要稳定、姿势驱动输出的创作者,而不希望出现抖动或身份漂移,一对多动画为您提供明确的路径:从源视频中提取姿势,将其与参考图像和遮罩融合,生成第一个片段,然后重复扩展该片段直到覆盖整个长度。
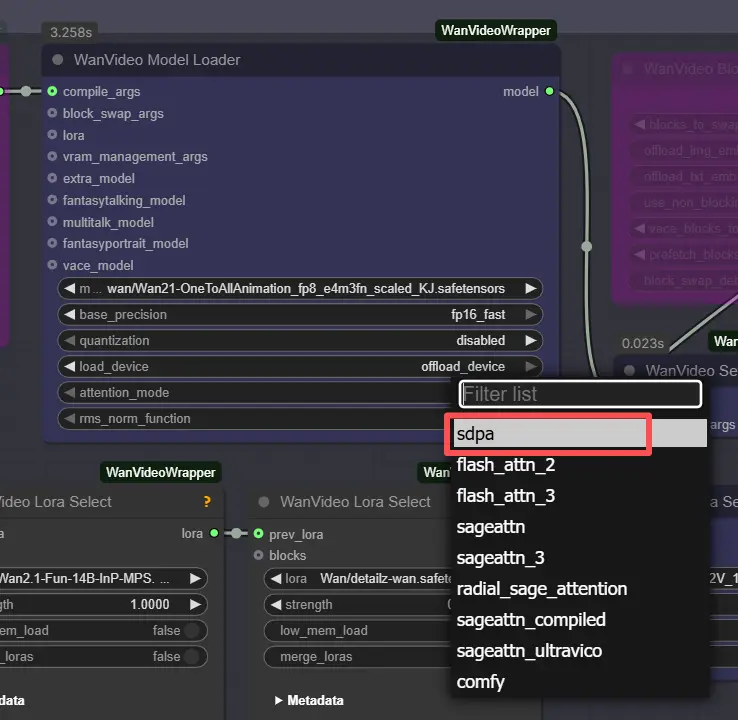
注意:在2XL或3XL机器上,请在WanVideo Model Loader节点中将attention_mode设置为"sdpa"。默认的segeattn后端可能会在高端GPU上导致兼容性问题。
Comfyui一对多动画工作流程中的关键模型#
- Wan 2.1 OneToAllAnimation(视频生成)。用于高质量运动和身份保留的主要扩散模型。示例权重:Wan21-OneToAllAnimation fp8由Kijai缩放。模型卡
- UMT5-XXL文本编码器。为Wan视频生成编码提示。模型卡
- ViTPose全身(姿势估计)。生成驱动姿势保真度的密集骨骼关键点。参见ViTPose论文和全身ONNX权重。论文 • 权重
- YOLOv10m检测器(人员/区域检测)。通过将估计器集中在主体上,加速稳健的姿势提取。论文 • 权重
- 可选ViTPose-H替代方案。用于挑战性运动的高容量全身模型。权重和数据文件
- 可选的LoRA包用于风格/控制。本图中使用的示例LoRAs包括Wan2.1-Fun-InP-MPS、detailz-wan和lightx2v T2V;它们在不重新训练的情况下优化纹理、细节或就地控制。
如何使用Comfyui一对多动画工作流程#
整体流程
- 工作流程读取您的参考动作视频,提取全身姿势,准备融合姿势和角色参考的一对多动画嵌入,生成初始片段,然后通过重叠不断扩展该片段,直到覆盖整个持续时间。最后,它合并音频并导出完整视频。
姿势提取
- 在
VHS_LoadVideo(#454)中加载您的运动源。使用ImageResizeKJv2(#131)调整帧以匹配生成的纵横比,以实现稳定采样。 OnnxDetectionModelLoader(#128)加载YOLOv10m和ViTPose全身;PoseDetectionOneToAllAnimation(#141)然后输出每帧姿势图、参考姿势图像和干净的参考遮罩。- 使用
PreviewImage(#145)快速检查姿势是否跟踪主体。清晰、高对比度的画面,运动模糊最小,可以产生最佳的一对多动画结果。
模型
WanVideoModelLoader(#22)加载Wan 2.1 OneToAllAnimation权重;WanVideoVAELoader(#38)提供配对的VAE。如果需要,通过WanVideoLoraSelect(#452, #451, #56)堆叠样式/控制LoRAs,并使用WanVideoSetLoRAs(#80)应用它们。- 文本提示由
WanVideoTextEncode(#16)编码。编写简洁、以身份为中心的正面提示和强有力的清理负面,以保持角色在模型上。
视频设置
- 在“视频设置”组中设置宽度和高度,并传播到姿势提取和生成,以确保一切保持对齐。
注意:⚠️ 分辨率限制:此工作流程固定为720×1280 (720p)。使用任何其他分辨率将导致维度不匹配错误,除非手动重新配置工作流程。
WanVideoScheduler(#231)和CFG控制选择噪声计划和提示强度。更高的CFG更符合提示;较低的值稍微松散地跟踪姿势,但可以减少伪影。VHS_VideoInfoLoaded(#440)读取源剪辑的fps和帧数,循环使用这些信息来确定需要多少一对多动画窗口。
采样 - 第1部分
WanVideoEmptyEmbeds(#99)为目标大小的条件创建容器。WanVideoAddOneToAllReferenceEmbeds(#105)注入您的参考图像及其ref_mask以锁定身份并保留或忽略背景或服装等区域。WanVideoAddOneToAllPoseEmbeds(#98)附加提取的pose_images和pose_prefix_image,以便第一个生成的片段从第一帧开始遵循源运动。WanVideoSampler(#27)生成初始潜在片段,该片段由WanVideoDecode(#28)解码,并可选择通过VHS_VideoCombine(#139)预览或保存。这是要扩展的种子片段。
循环
VHS_GetImageCount(#327)和MathExpression|pysssss(#332)根据总帧数和每次通过的长度计算需要多少次扩展。easy forLoopStart(#329)使用初始片段作为起始上下文开始扩展。
采样 - 循环
Extend(#263)是一对多动画长长度的核心。它通过WanVideoAddOneToAllExtendEmbeds(在子图内)重新计算条件,以保持与先前潜在的一致性,然后采样并解码下一个窗口。ImageBatchExtendWithOverlap(在Extend中)使用overlap区域将每个新窗口融合到累积视频中,平滑边界并减少时间缝。easy forLoopEnd(#334)附加每个扩展块。结果通过Set_video_OneToAllAnimation(#386)存储以供导出。
导出
VHS_VideoCombine(#344)写入最终视频,使用源fps和VHS_LoadVideo中的可选音频。如果您希望获得无声结果,可以在此处省略或静音音频输入。
Comfyui一对多动画工作流程中的关键节点#
PoseDetectionOneToAllAnimation (#141)
- 检测主体并估计驱动姿势指导的全身关键点。由YOLOv10和ViTPose支持,对快速运动和部分遮挡具有鲁棒性。如果您的主体漂移或多人物场景使检测器混淆,请裁剪输入或切换到上面链接的高容量ViTPose-H权重。
WanVideoAddOneToAllReferenceEmbeds (#105)
- 将参考图像和
ref_mask融合到条件中,以确保身份、服装或受保护区域在帧间保持稳定。紧密的遮罩可以保护面部和头发;较宽的遮罩可以锁定背景。当改变外观时,交换参考并保持相同的运动。
WanVideoAddOneToAllPoseEmbeds (#98)
- 将姿势图和前缀姿势绑定到一对多动画嵌入中。对于更严格的编舞,增加姿势影响;对于更自由的解释,略微减少它。与LoRAs结合使用时,希望在保持一致纹理的同时仍能匹配运动。
WanVideoSampler (#27)
- 将嵌入和文本转化为初始潜在片段的主要视频采样器。
cfg控制提示的遵循程度,scheduler在质量、速度和稳定性之间进行权衡。在此处和循环中使用相同的采样器系列,以避免闪烁。
Extend (#263)
- 执行带有重叠的滑动窗口扩展的紧凑子图。
overlap设置是关键旋钮:更多重叠可更平滑地融合过渡,但需要额外计算;较少重叠速度更快,但可能显露接缝。此节点还重用先前的潜在,以保持场景和角色在窗口之间的一致性。
VHS_VideoCombine (#344)
- 最终混合和保存。根据检测到的fps设置
frame_rate,以保持运动时间与源一致。您可以在后期修剪或循环,但以原始节奏导出可以保留表演的感觉。
可选附加功能#
- 预处理器的安装说明。姿势提取节点来自社区插件。请参阅仓库以获取设置和ONNX放置。ComfyUI-WanAnimatePreprocess
- 对于困难运动,优先选择ViTPose-H。当手/脚快速或部分遮挡时,切换到ViTPose-H;从上面链接的页面下载模型及其数据文件。
- 长时间运行的调优。如果您遇到VRAM限制,请减少每次通过的窗口长度或简化LoRA堆栈。然后可以略微提高重叠以保持过渡干净。
- 强烈身份保留。使用高质量、正面参考,并绘制精确的
ref_mask以保护面部、头发或服装。对于长时间的一对多动画序列,这一点至关重要。 - 干净的画面有帮助。高快门速度、一致的照明和清晰的前景主体将显著改善姿势跟踪,并减少一对多动画输出中的抖动。
- 视频实用程序。导出器和辅助节点来自视频助手套件。如果您希望对编解码器或预览进行额外控制,请查看项目文档。视频助手套件
致谢#
此工作流程实现并建立在以下作品和资源的基础上。我们诚挚感谢Innovate Futures @ Benji提供的一对多动画工作流程教程,以及ssj9596对一对多动画项目的贡献和维护。有关权威细节,请参阅下面链接的原始文档和仓库。
资源#
- Innovate Futures @ Benji/一对多动画来源
- GitHub: ssj9596/One-to-All-Animation
- Hugging Face: MochunniaN1/One-to-All-1.3b_1
- arXiv: 2511.22940
- 文档/发布说明: Patreon post
注意:所引用模型、数据集和代码的使用受其作者和维护者提供的相应许可和条款的约束。


