
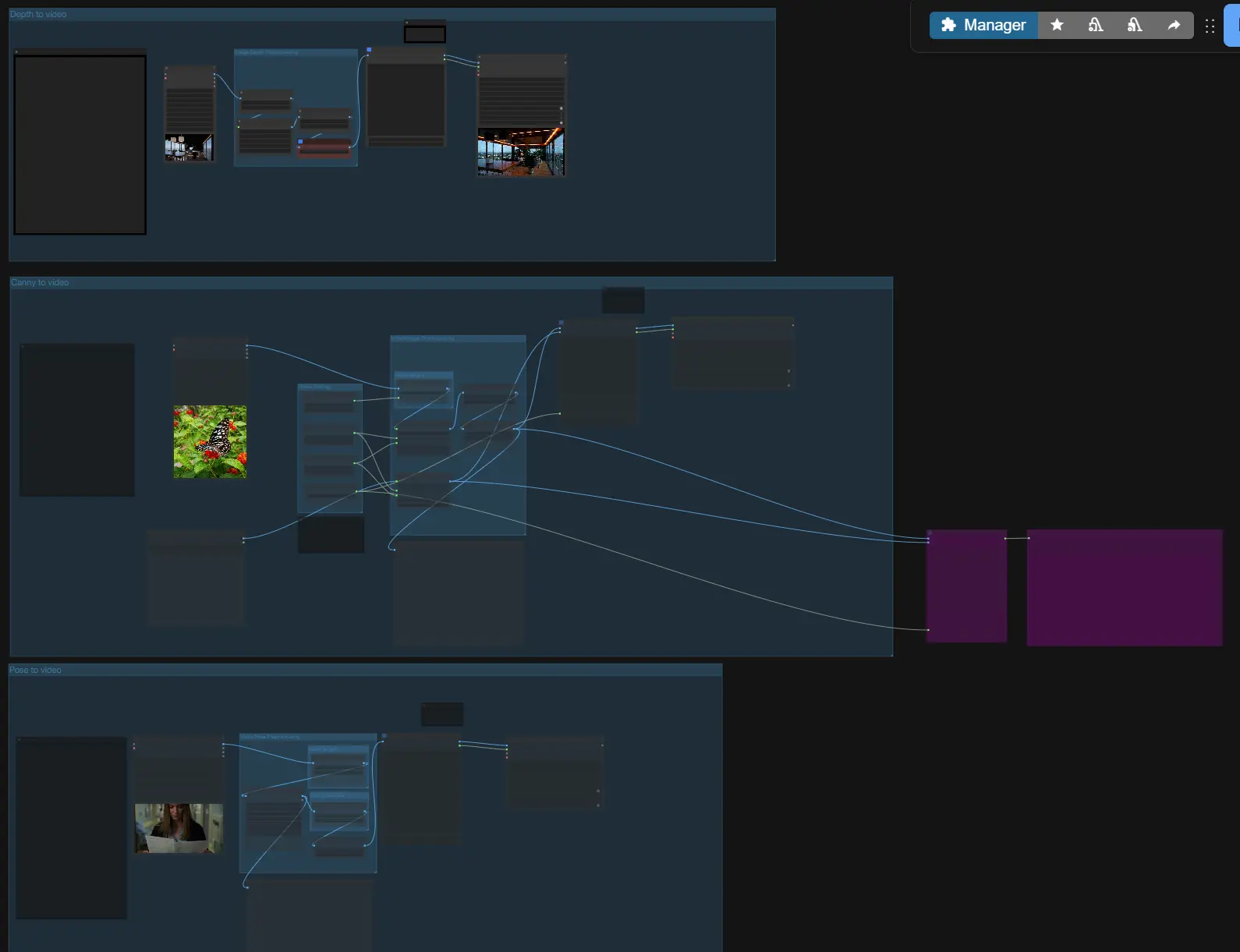
LTX-2 ControlNet: 在ComfyUI中结构引导、音频同步的视频生成#
LTX-2 ControlNet是一个控制驱动的ComfyUI工作流,用于ComfyUI-LTXVideo扩展,允许您通过深度、Canny边缘和姿态引导来引导LTX-2视频生成,同时保持音频和视觉同步。它在一个统一的视听潜在空间中运行,因此语音、音效和运动一起生成并从第一帧到最后一帧保持对齐。
针对文本到视频、图像到视频和视频到视频,工作流添加了基于IC LoRA的ControlNet条件以实现精确的布局和运动控制,场景连续性的首帧初始化,以及具有潜在放大的两阶段管道,以在不增加VRAM的情况下获得清晰的结果。LTX-2 ControlNet完全开放,快速迭代,面向需要可重复、高质量输出的创作者。
Comfyui LTX-2 ControlNet工作流中的关键模型#
- LTX-2 19B (开发 FP8和蒸馏)。用于在单个潜在空间中采样视频和音频的核心视听生成模型。模型系列
- Gemma 3 12B IT文本编码器。通过LTX-2使用的打包编码器提供对提示和否定的强大语言理解。编码器文件
- LTX-2 Spatial Upscaler x2。用于第二阶段的潜在放大模型以细化空间细节。放大器
- LTX-2 Audio VAE。专门的音频解码编码器,使生成的声音与帧保持对齐。包含在LTX-2检查点中。检查点
- IC LoRA控制系列用于LTX-2。添加ControlNet风格的条件:
- 深度控制LoRA: ltx-2-19b-IC-LoRA-Depth-Control
- Canny控制LoRA: ltx-2-19b-IC-LoRA-Canny-Control
- 姿态控制LoRA: ltx-2-19b-IC-LoRA-Pose-Control
- 蒸馏LoRA以实现质量/效率权衡: ltx-2-19b-distilled-lora-384
- Lotus Depth D v1.1。用于深度控制路径的深度估计器。模型
- SD VAE FT MSE (Stability AI)。用于深度预计算和平铺解码的图像VAE。VAE
- ComfyUI-LTXVideo扩展。提供在整个过程中使用的LTX-2采样器、AV潜在变量、音频VAE和引导节点。仓库
如何使用Comfyui LTX-2 ControlNet工作流#
在高层次上,LTX-2 ControlNet接受您的提示和可选参考,构建一个带有ControlNet风格引导的视听潜在变量,进行第一次采样,然后放大潜在变量以获得清晰的视频和同步的音频。选择三种引导路径之一(深度、Canny、姿态)或独立使用它们,然后在导出前设置长度和大小。
- 图像/视频预处理
- 如果您正在进行从图像到视频或从视频到视频,请使用加载器导入您的参考媒体。
VHS_LoadVideo(#196, #197, #198)分割帧以进行分析,而LoadImage(#189)处理静帧。该组提供便利的缩放,以便下游引导看到一致的帧大小。 - 可以传递“首帧”图像以进行场景初始化;稍后将在生成组中启用它。
- 如果您正在进行从图像到视频或从视频到视频,请使用加载器导入您的参考媒体。
- 图像深度预处理
- 对于深度引导,“Image to Depth Map (Lotus)”子图使用Lotus Depth将您的输入转换为标准化深度图。这准备了一个单帧或多帧的深度表示,LTX-2可以遵循。
- 路径包括可选的调整大小和强度控制,以便引导编码广泛的结构而不过度拟合小的伪影。
- 视频姿态预处理
- 对于姿态引导,
DWPreprocessor(#158)从输入视频中检测全身关键点并对其进行缩放以实现稳定的条件。这产生了一个干净的姿态图像序列,强调骨架和肢体方向。 - 预览节点帮助您快速验证检测和纵横比在生成前看起来是否正确。
- 对于姿态引导,
- Canny到视频
- 此控制路径使用
Canny(#169)提取边缘,然后使用控制图像序列构建一个AV潜在变量。当您希望保留轮廓、主要轮廓或参考中的排版边缘时使用它。 - 提供首帧图像输入以进行一致的初始化;仅在您希望开头帧匹配特定静帧时启用它。
- 此控制路径使用
- 深度到视频
- 此路径将Lotus深度图作为控制图像。深度控制非常适合在选择纹理和照明时执行相机几何、大规模布局和主体距离。
- 您可以提供首帧以锁定初始构图,然后让运动在深度提示的引导下演变。
- 姿态到视频
- 姿态路径使用来自预处理器的关键点渲染,指导身体方向和运动时间。它在角色阻挡、手提时间和行走循环方面特别有效。
- 如同其他模式,您可以将提示时间与可选的首帧条件结合使用以实现连续性。
- 视频设置和长度
- 在“视频设置”和“视频长度”组中设置工作宽度、高度和帧数。工作流自动调整无效值到LTX-2的潜在网格和步幅的最近兼容尺寸,以便您可以安全地迭代。
- 保持目标帧速率在节点之间一致;条件节点和最终复合尊重它以实现平滑的视听同步。
- 生成、放大和导出
- 在采样期间,
LTXVAddGuide将您的正/负条件与选择的控制图像相结合,然后SamplerCustomAdvanced从LTXVScheduler执行视频和音频潜在变量的计划。可选的首帧通过LTXVImgToVideoInplace注入以启用。 - 第二阶段运行
LTXVLatentUpsampler以使用x2潜在放大器细化细节。最终解码通过平铺的VAEDecodeTiled进行帧和LTXVAudioVAEDecode进行音频,然后视频通过VHS_VideoCombine或CreateVideo根据选择的分支写入。
- 在采样期间,
Comfyui LTX-2 ControlNet工作流中的关键节点#
LTXVAddGuide(#132)- 将文本条件和IC LoRA控制合并到AV潜在变量中,作为LTX-2 ControlNet引导的核心。仅调整少数重要控制:选择与您的路径(深度、Canny或姿态)匹配的控制LoRA,并在可用时调整
image_strength以调整模型对引导的跟随程度。参考实现和节点行为由LTXVideo扩展提供。文档/代码
- 将文本条件和IC LoRA控制合并到AV潜在变量中,作为LTX-2 ControlNet引导的核心。仅调整少数重要控制:选择与您的路径(深度、Canny或姿态)匹配的控制LoRA,并在可用时调整
LTXVImgToVideoInplace(#149, #155)- 将首帧图像注入AV潜在变量以实现一致的场景初始化。使用
strength在对首帧的忠实度与自由演变之间取得平衡;保持较低以获得更多运动,较高以获得更紧密的锚点。当您希望完全由文本或控制驱动的开头时,绕过它。文档/代码
- 将首帧图像注入AV潜在变量以实现一致的场景初始化。使用
LTXVScheduler(#95)- 驱动统一潜在变量的去噪轨迹,以便音频和视频一起收敛。增加步骤以适应复杂场景和细节;缩短以进行草稿和快速迭代。计划设置与引导强度相互作用,因此当引导强时避免极端值。文档/代码
LTXVLatentUpsampler(#112)- 使用LTX-2 x2空间放大器执行第二阶段潜在放大,通过最小的VRAM增长提高清晰度。在第一次通过后使用它,而不是增加基础分辨率,以保持迭代响应。放大器模型
DWPreprocessor(#158)- 为姿态控制路径生成干净的人体姿态关键点。通过预览验证检测;如果手或小肢体有噪声,在预处理前将输入缩放到适度的最大尺寸。由ControlNet辅助套件提供。仓库
VHS_VideoCombine/CreateVideo(#195, #106)- 将解码的帧和音频以选定的帧速率和像素格式合并为MP4。仅在确认音频解码在预览中看起来对齐后使用它们。由视频助手套件提供。仓库
可选附加功能#
- LTX-2 ControlNet的提示
- 描述随时间变化的动作,而不仅仅是静态属性。
- 包含所需的声音提示或对话,以便音频按节拍生成。
- 使用简洁的负面提示来抑制您反复看到的伪影。
- 大小和长度
- 使用形式为32k + 1的图像大小;如果您错过了,图表会自动校正,但精确的值会加速迭代。
- 形式为8k + 1的帧数对于调度来说通常是最稳定的。
- 首帧一致性
- 仅在需要锁定的开头构图时启用首帧;将其与中等的
image_strength配对以避免过度约束。
- 仅在需要锁定的开头构图时启用首帧;将其与中等的
- VRAM和吞吐量
- 工作流在LTXVideo补丁中包含序列并行和torch编译选项,适用于多GPU或内存受限的设置。对于长片段保持开启,调试节点行为时关闭。扩展
致谢#
此工作流实现并建立在以下工作和资源的基础上。我们对Lightricks的ComfyUI-LTXVideo的贡献和维护表示感谢。有关权威的详细信息,请参阅下面链接的原始文档和存储库。
资源#
- ComfyUI-LTXVideo GitHub Repository: https://github.com/Lightricks/ComfyUI-LTXVideo
- GitHub: Lightricks/ComfyUI-LTXVideo
注意:所引用的模型、数据集和代码的使用受其作者和维护者提供的各自许可证和条款的约束。