
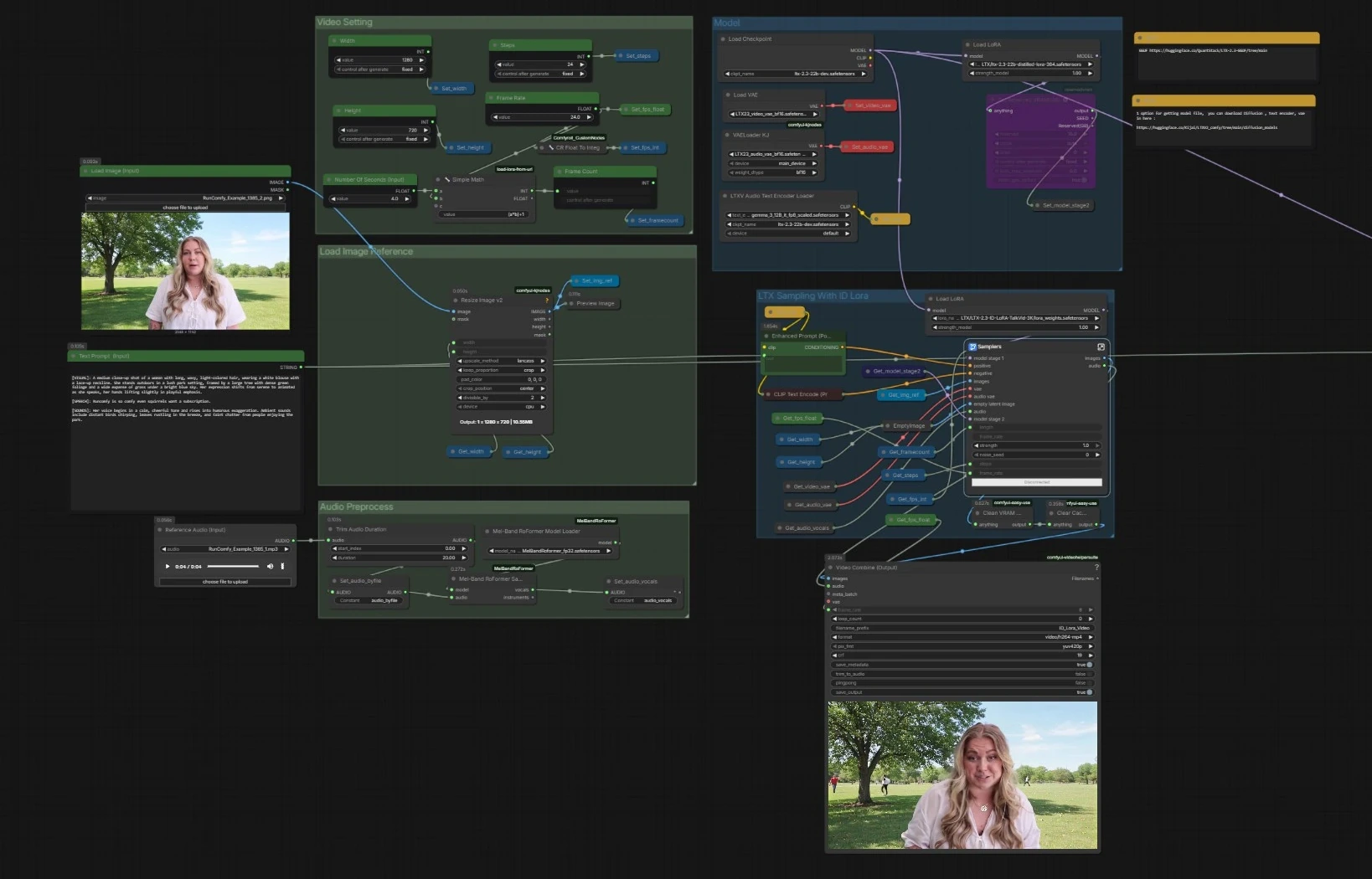
LTX 2.3 ID-LoRA 对话视频工作流 for ComfyUI#
此工作流将单张人脸图像、短语音片段和提示转换为完全同步的对话视频。基于 LTX-2.3,它将音频和视觉融合在一个扩散过程中,并添加了 In-Context LoRA 身份适配器,以确保参考图像中的人物在所有帧中保持一致。LTX 2.3 ID-LoRA 非常适合用于化身、虚拟主持人以及任何需要在一次通过中对齐唇形同步、相似性和提示控制的场景。
您需要提供三样东西:一张参考图像、一两句音频和描述外观和表现的文本提示。LTX 2.3 ID-LoRA 路径处理身份,同时轻量级音频预处理器增强语音清晰度以获得更强的嘴部提示。结果是一个连贯的、保持身份的视频,带有同步的语音,不需要每个主体的训练。
Comfyui LTX 2.3 ID-LoRA 工作流中的关键模型#
- Lightricks LTX-2.3 22B 基础检查点。联合音视频基础模型,从文本、图像和音频条件生成同步的帧和声音。它是此 ComfyUI 管道使用的核心生成器。模型卡
- LTX-2.3 蒸馏 LoRA 384。官方 LoRA 适配器,为基础模型应用蒸馏指导,以稳定和加速采样而不牺牲质量。它作为此工作流中的第二阶段模型插入。请参阅 LTX-2.3 页面上的检查点表。模型卡
- LTX-2.3 空间放大器 x2。潜在空间放大器用于采样子图中,在解码前提升空间细节,改善最终视频中的面部和边缘保真度。模型卡
- Gemma 3 12B 指令文本编码器用于 LTX-2.3。提供驱动风格、场景和表现的文本条件。此工作流使用了适用于 ComfyUI 的 LTX-2 的 Gemma 3 编码器。Comfy-Org 文本编码器
- LTX-2.3 视频和音频 VAEs。专为解码模型生成的视觉和声学潜在变量而设计的 VAEs,兼容的 bf16 构建在图中引用。示例来源:视频 VAE · 音频 VAE
- Mel-Band RoFormer 用于声乐分离。可选的预处理器,从参考音频中提取干净的声乐,以便模型可以更可靠地跟踪音节和嘴形。论文 · ComfyUI 节点
- LTX 2.3 ID-LoRA (IC-LoRA)。为对话视频使用而训练的上下文内身份 LoRA,使生成器偏向于您的参考图像中的面部,同时尊重提示和语音提示。Lightricks 在模型页面上记录了 LoRA 和 IC-LoRA 与 LTX-2.3 的使用。模型卡
如何使用 Comfyui LTX 2.3 ID-LoRA 工作流#
总体流程。管道加载 LTX-2.3 基础与文本编码器和 VAEs,准备您的图像和音频,然后运行一个结合文本、人脸参考和声轨的两阶段 LTX 采样器以生成同步的帧和语音。包含一个没有 ID-LoRA 的并行采样器用于快速比较。最终帧和音频被混合成 MP4。
- 模型
- 图加载基础检查点与
CheckpointLoaderSimple(#5493),通过LTXAVTextEncoderLoader(#5494) 加载基于 Gemma 的文本编码器,视频VAELoader(#5651) 和音频VAELoaderKJ(#5649) 的专用 VAEs。然后应用两个适配器:官方蒸馏 LoRA 形成第二阶段模型和用于身份条件的 LTX 2.3 ID-LoRA 通过LoraLoaderModelOnly(#5573)。 - 此阶段确保生成器理解您的提示,具有正确的解码堆栈,并通过效率指导和身份偏向进行了优化。
- 一般情况下,您无需在此处修改任何内容,除非您有替代检查点或 LoRA。
- 图加载基础检查点与
- 视频设置
- 控制输出尺寸、帧率、步骤和长度。
Width(#5284)、Height(#5286) 和Frame Rate(#5289) 提供一个小型工具,用于从秒计算总帧数,保持音频和视频的时间一致性。 - 设置存储一次,并由所有下游节点读取,因此两个采样器和多路复用器保持对齐。
- 当您想要不同的纵横比、平滑度或时长时,首先调整这些值。
- 控制输出尺寸、帧率、步骤和长度。
- 加载图像参考
- 通过
Load Image (Input)(#5525) 提供一张清晰的人脸图像。图像通过ImageResizeKJv2(#5280) 调整大小以匹配您选择的输出。 - 此预处理图像成为 LTX 2.3 ID-LoRA 阶段中身份的锚点,指导相似性和镜头构图。
- 使用光线充足、正面拍摄且运动模糊最小的照片以获得最佳效果。
- 通过
- 音频预处理
- 使用
Reference Audio (Input)(#5652) 插入一个短的 WAV 或 MP3。必要时修剪剪辑,然后传递给MelBandRoFormerSampler(#5473) 以隔离声乐。 - 清晰的声乐有助于模型推断音素和时间,以实现准确的唇部动作和说话节奏。
- 如果您的音频已经是仅语音,您可以跳过分离并直接输入。
- 使用
- 使用 ID Lora 的 LTX 采样
- 这是主要路径。采样器子图 (
Samplers(#5278)) 将您的正面提示从Enhanced Prompt (Positive)(#5174)、负面列表、人脸参考和声轨通过 LTX-2.3 的 AV 潜在管道混合。 LTXVReferenceAudio对齐运动与语音而LTXVImgToVideoInplace将面部图像注入潜在变量作为锚点。LTX 2.3 ID-LoRA 适配器引导生成器朝向您的主体身份。- 该阶段包括一个内部潜在放大器,以在解码前提升细节。它输出帧加上同步的音频流。
- 这是主要路径。采样器子图 (
- 无 ID Lora 的 LTX 采样
- 镜像采样器 (
Samplers(#5643)) 运行相同的条件,但没有 ID-LoRA 适配器。当您想要从参考身份中获得更多自由时,使用此选项进行 A/B 检查或快速草稿。 - 其他一切保持相同,因此您注意到的差异仅由于身份条件。
- 此路径对于快速草图或创意偏离很有帮助。
- 镜像采样器 (
- 视频合并和输出
- 使用
Video Combine (Output)(#5218) 将帧和生成的音频混合为 MP4。帧率来自您的全局设置,因此运动和唇形同步匹配采样器的时间。 - 如果您启用了无 ID-LoRA 分支,次级
Video Combine(#5645) 将预览它,这对于比较很有用。 - 工作流在运行之间清除缓存,以保持长时间会话中的 VRAM 稳定。
- 使用
Comfyui LTX 2.3 ID-LoRA 工作流中的关键节点#
LoraLoaderModelOnly(#5573)- 加载保持面部身份的 LTX 2.3 ID-LoRA。如果您想要更多创意变化,请减轻其权重,或增加以更紧密地锁定相似性。与提示强度配合使用,以便身份和风格不竞争。参考:LTX-2.3 LoRA 在模型页面上的使用。模型卡
LTXVReferenceAudio(#5589)- 将您的参考音频转换为音节时间、韵律和嘴形的条件。提供清晰的语音以获得最佳对齐。如果您听到泵送或偏离节奏的发音,缩短或简化剪辑,而不是增强强度。
LTXVImgToVideoInplace(#5245, 也在后面使用)- 将面部图像注入潜在视频流作为空间先验。图像强度控制平衡对照片的遵循与运动自由。对于强身份和自然运动,保持图像强度适中,让 ID-LoRA 维持相似性。
LTXVConditioning(#5621)- 为 LTX 采样器打包文本条件和时间提示。确保其帧率输入与您的输出帧率匹配,以便运动字段和音素时间保持一致。
VHS_VideoCombine(#5218)- 将帧和音频混合到最终文件中。如果您的音频稍长于帧,请在此启用修剪以防止尾部留下黑色。为了平台兼容性,除非有理由更改,否则保持默认 H.264 设置。节点参考:ComfyUI-VideoHelperSuite
MelBandRoFormerSampler(#5473)- 使用 Mel-band 变换器从音乐中分离声乐,以便生成器锁定语音。如果咝音模糊或爆破音爆裂,尝试同一系列的不同模型文件或降低输入响度。背景阅读:arXiv
可选附加功能#
- 对于 LTX-2.3 的最稳定生成,使用宽度和高度为 32 的倍数,并选择 8n + 1 的帧数,如 Lightricks 所记录。模型卡
- 使参考图像与您的提示一致。如果您描述户外光照但提供室内照片,身份可能会保持,但颜色和阴影会与提示冲突。
- 为音频提供 2 到 8 秒的自然节奏。即使在声乐分离后,过度压缩或混响的剪辑也会降低唇形同步的保真度。
- 当面部漂移时,稍微降低图像强度,并更多地依赖 LTX 2.3 ID-LoRA。当面部漂移过多时,反向操作。
- 对于较长的拍摄,生成共享相同种子和全局设置的段落,然后在需要时在视频编辑中加入剪辑。
参考和有用的仓库#
- LTX-2.3 开放权重和备注:Hugging Face 模型页面
- LTX 视频的官方 ComfyUI 节点:Lightricks/ComfyUI-LTXVideo
- LTX-2 代码库和论文:Lightricks/LTX-Video · arXiv
- 用于 ComfyUI 的 Gemma 3 12B IT 编码器:Comfy-Org/ltx-2 text_encoders
- Mel-Band RoFormer 背景:arXiv
致谢#
此工作流实现并基于以下作品和资源。我们感谢 LTX 2.3 ID-LoRA Source 的创建者为 LTX 2.3 ID-LoRA Source 工作流的贡献和维护。有关权威详细信息,请参阅下方链接的原始文档和存储库。
资源#
- LTX 2.3 ID-LoRA Source
- 文档 / 发布说明:YouTube @Benji’s AI Playground
注意:所引用的模型、数据集和代码的使用受其作者和维护者提供的各自许可和条款的约束。