
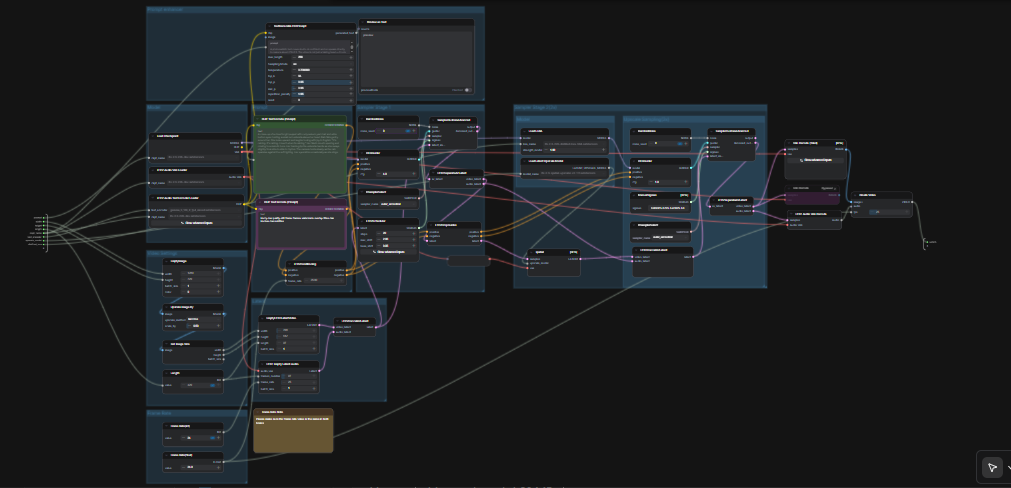
LTX 2.3 ComfyUI: 文本到视频,配有清晰音频、双阶段采样和2×空间放大#
此 LTX 2.3 ComfyUI 工作流程将短提示转换为精致的电影视频,并配有同步音频。它围绕 Lightricks 的 LTX‑2.3 模型构建,配置为高视觉连贯性、稳定运动和广播友好输出。创作者、编辑和技术艺术家可以通过一次操作从单个提示生成带有音频的 MP4,使用包含提示增强器、两个采样阶段和2×潜空间放大的简化图形。
与典型的文本到视频设置相比,此图强调场景一致性和提示保真度。默认路径生成一个 AV 潜在变量,在潜在空间中放大以获得更锐利的细节,然后解码为帧和音频,最后将所有内容打包成一个准备分享的视频文件。如果您正在探索现代开源视频模型,此 LTX 2.3 ComfyUI 工作流程是获得生产质量运动的快速方法。
Comfyui LTX 2.3 ComfyUI 工作流程中的关键模型#
- LTX‑2.3 22B (dev) checkpoint by Lightricks. 核心文本到视频模型,产生高连贯运动和强场景一致性。 Hugging Face • GitHub
- Gemma 3 12B Instruct text encoder (FP4 mixed). 提供强大的语言理解能力,以更好地支持提示定位和丰富的场景细节。 Hugging Face
- LTX‑2.3 Spatial Upscaler x2 1.0. 一个潜空间上采样器,在不破坏运动一致性的情况下锐化空间细节。 Hugging Face
- LTX‑2.3 22B Distilled LoRA (384). 一个蒸馏适配器,在放大/精炼阶段精细化纹理保真度并稳定风格。 Hugging Face
- LTX Audio VAE. 与 LTX‑2.3 配对的音频模块,可从同一提示生成清晰、同步的声音。 Hugging Face
如何使用 Comfyui LTX 2.3 ComfyUI 工作流程#
图形在协调的两次通过中运行。首先,它在工作分辨率下使用您的提示生成 AV 潜在变量。然后执行2×潜在放大和一个蒸馏 LoRA 的第二次采样通过,最后解码为帧和音频,最终复用为 MP4。
提示增强器#
TextGenerateLTX2Prompt (#149) 节点将普通语言重写为模型友好的提示,涵盖动作、视觉和音频线索。输入您的场景描述;如果需要框架或风格的指导,可以连接可选的参考图像。生成的文本被路由到一个正向编码器,而一个质量导向的负向提示则保持伪影减少。这种平衡帮助 LTX‑2.3 模型在不过度限制创造力的情况下保持任务。
模型#
CheckpointLoaderSimple (#146) 加载 LTX‑2.3 22B 检查点并公开模型及其 VAE。LTXAVTextEncoderLoader (#147) 引入工作流程使用的 Gemma 3 12B Instruct 文本编码器,用于正向和负向条件。除非您正在测试其他 LTX 变体,否则请保持这些选择,因为其余图形已针对该配对进行调整。
视频设置#
分辨率和持续时间通过轻量级图像支架和 Length 控件设置。图形读取图像大小,将其缩放为工作分辨率,并将这些值转发到视频潜在创建器。LTX 模型有步幅约束;请坚持遵循32步幅模式的大小和与模型的帧节奏一致的长度。图形会轻微调整非法值到最近的有效值,但预先选择有效大小会产生最佳构图。
帧率#
两个小控件设置用于条件和最终编码的 FPS:Frame Rate(int) (#141) 和 Frame Rate(float) (#140)。保持它们相同,以便在整个管道中运动时间和音频对齐保持一致。如果您想要更流畅的运动,请选择电影帧率;如果针对社交格式,请匹配平台默认设置。
潜在#
EmptyLTXVLatentVideo (#121) 初始化视频潜在,LTXVEmptyLatentAudio (#119) 对音频进行同样操作。LTXVConcatAVLatent (#122) 将它们合并为单个 AV 潜在,以便文本引导可以同时引导两种模式。LTXVConditioning (#120) 附加正向和负向条件,LTXVCropGuides (#115) 将引导适应潜在的空间布局,以实现更可靠的构图。
采样器阶段 1#
此阶段使用 RandomNoise (#151)、KSamplerSelect (#144) 和 LTX 感知的 LTXVScheduler (#112) 以及 CFGGuider (#139) 创建初始 AV 潜在。调度程序专为 LTX 量身定制,以平衡时间稳定性和提示遵循性。如果您想要更多变化,请更改噪声种子;如果想让脚本更稳定地遵循,请选择保持时间连贯性的采样器。
模型 (LoRA)#
LoraLoaderModelOnly (#143) 在精炼前应用 LTX‑2.3 蒸馏 LoRA。此适配器在不失去运动一致性的情况下,微妙地提升纹理光泽和风格保真度。它在皮肤、织物和镜面高光上最为明显。
放大采样 (2×)#
LTXVLatentUpsampler (#130) 使用加载的 LatentUpscaleModelLoader (#114) 和基础 VAE 在潜空间中执行2×空间放大。因为放大在解码之前进行,您保留时间平滑性,同时获得细致的空间细节。放大的视频和音频潜在变量然后与 LTXVConcatAVLatent (#129) 重新结合进行精炼通道。
采样器阶段 2 (2×)#
第二次通过使用 RandomNoise (#127)、KSamplerSelect (#145) 和 ManualSigmas 调度 (#113) 在 CFGGuider (#116) 下细化放大的潜在变量。此阶段是微细节和边缘锐度最终确定的地方。当 LoRA 活跃且提示具体到纹理和光照时效果最佳。
解码和输出#
LTXVSeparateAVLatent (#135) 拆分精炼的潜在变量,以便 VAEDecodeTiled (#137) 可以重建帧,而 LTXVAudioVAEDecode (#138) 恢复音频。CreateVideo (#133) 在选定的 FPS 下将帧和音频进行复用,顶层 SaveVideo 节点将 MP4 写入工作流程的视频文件夹。结果是一个在 LTX 2.3 ComfyUI 管道内部完全生成的干净、准备分享的文件。
Comfyui LTX 2.3 ComfyUI 工作流程中的关键节点#
TextGenerateLTX2Prompt(#149): 将简单描述转化为涵盖运动、视觉属性和音频的结构化提示。首先在此处调整您的措辞以引导故事情节或节奏;通常比采样器调整获得更大收益。LTXVScheduler(#112): 一个特定于 LTX 的调度程序,塑造噪声随时间的去除方式。明智地与您选择的采样器配对,以平衡时间稳定性和提示保真度。LTXVLatentUpsampler(#130): 直接在潜空间中执行2×空间放大,保留运动连续性,同时增加清晰细节。需要更锐利的结果时使用它,而不是依赖解码后的放大器。LoraLoaderModelOnly(#143): 应用 LTX‑2.3 蒸馏 LoRA 进行精炼。增加影响以更紧密地控制风格;如果想要基础模型的更广泛外观,则减少它。CreateVideo(#133): 在选定的 FPS 下将解码的帧与生成的音频进行复用,以保持时间和口型同步。如果更改 FPS,请保持两个帧率控件匹配。
可选扩展#
- 提示技巧:描述随时间变化的动作,列出关键视觉元素,并指定期望的声音或对话。清晰、简洁的措辞为 LTX‑2.3 编码器提供最佳信号。
- 尺寸和长度:偏好32步幅的大小和尊重模型帧节奏的长度。尽管图形自动调整接近值,但有效输入改善构图并减少细微抖动。
- 快速迭代:在运行之间更改
RandomNoise种子,以探索变体,同时保持相同的提示和设置。 - 模型切换:默认设置已针对 LTX‑2.3 22B 与 Gemma 3 12B IT 和2×空间放大器调优。仅在您了解每个如何影响条件和解码时交换模型。
致谢#
此工作流程实现并构建在以下作品和资源之上。我们诚挚感谢 Lightricks 提供的 LTX-2.3 模型和 EyeForAILabs 提供的 YouTube 教程的贡献和维护。有关权威细节,请参阅以下链接的原始文档和存储库。
资源#
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: 2601.03233
- EyeForAILabs/YouTube Tutorial
- 文档 / 发布说明: YouTube Channel from @eyeforailabs
注意:使用引用的模型、数据集和代码需遵循其作者和维护者提供的相关许可证和条款。