
Hunyuan Video 1.5 ComfyUI 工作流程:快速的文本到视频和图像到视频,支持1080p超分辨率#
此工作流程将Hunyuan Video 1.5 包装在 ComfyUI 中,以便在消费者GPU上快速生成连贯的视频。它支持文本到视频和图像到视频,然后可以选择使用专用的潜在上采样器和蒸馏超分辨率模型放大到1080p。在后台,Hunyuan Video 1.5 将扩散变压器与3D因果VAE和选择性滑动平铺注意力策略结合起来,以平衡质量、运动保真度和速度。
创作者、产品团队和研究人员可以使用此ComfyUI Hunyuan Video 1.5工作流程从提示或单个静止图像快速迭代,以720p预览,并在需要时以清晰的1080p输出完成。
Comfyui Hunyuan Video 1.5 工作流程中的关键模型#
- HunyuanVideo 1.5 720p 图像到视频 UNet。从起始图像生成运动和时间连贯性。权重在Hugging Face的Comfy-Org重新打包中提供 Comfy-Org/HunyuanVideo_1.5_repackaged。
- HunyuanVideo 1.5 720p 文本到视频 UNet。直接从文本提示生成视频,使用相同的核心架构,为提示优先的工作流程进行了调整。参见上面的重新打包存储库。
- HunyuanVideo 1.5 1080p 超分辨率 UNet(蒸馏)。在保留运动和场景结构的同时,将720p潜在细节提升到更高的细节。在Hugging Face的相同重新打包中包含。
- HunyuanVideo 1.5 3D VAE。编码和解码视频潜在信息以实现高效生成和平铺解码。
- HunyuanVideo 1.5 潜在上采样器1080p。在SR优化之前将潜在序列缩放到1920×1080,以提高速度和内存效率。
- Qwen 2.5 VL 7B 文本编码器和 ByT5 小型文本编码器。提供强大的指令跟随和标记化功能,用于多样化的提示,重新打包到此工作流程中的Hugging Face捆绑包中。ByT5的原始模型卡:google/byt5-small。
- SigCLIP Vision (ViT-L/14, 384)。从起始图像中提取高质量的视觉特征,以指导图像到视频的条件:Comfy-Org/sigclip_vision_384。
如何使用 Comfyui Hunyuan Video 1.5 工作流程#
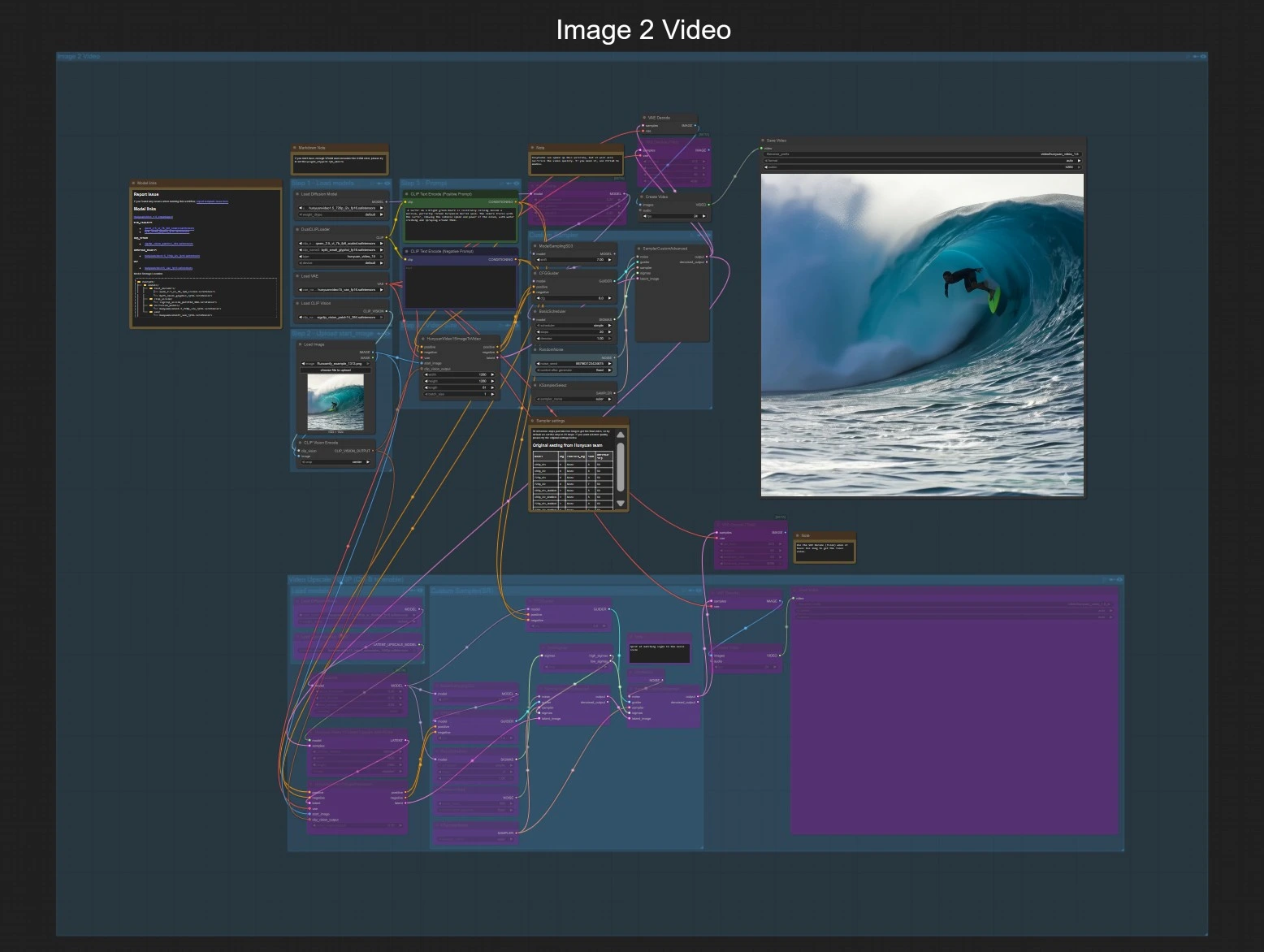
此图表展示了两个独立的路径,分享相同的导出和可选的1080p完成阶段。选择图像到视频或文本到视频,然后可以选择启用1080p组进行最终化。
图像到视频#
步骤1 — 加载模型 加载器引入Hunyuan Video 1.5 图像到视频UNet、3D VAE、双文本编码器和SigCLIP视觉。这使工作流程准备好接受单个起始图像和提示。用户无需采取任何行动,只需确认模型可用即可。
步骤2 — 上传起始图像 在LoadImage (#80)中提供干净、曝光良好的图像。图表使用CLIPVisionEncode (#79)对该图像进行编码,以便Hunyuan Video 1.5可以将运动和风格锚定在您的参考上。尽量选择与目标长宽比大致相符的图像,以减少裁剪或填充。
步骤3 — 提示 在CLIP Text Encode (Positive Prompt) (#44)中编写您的描述。使用负提示CLIP Text Encode (Negative Prompt) (#93)来避免不需要的伪影或风格。保持提示简洁,但要具体说明主题、运动和相机行为。
步骤4 — 视频大小和时长 HunyuanVideo15ImageToVideo (#78)设置空间分辨率和合成的帧数。较长的序列需要更多的VRAM和时间,因此一开始可以短一些,喜欢的运动再放大。
自定义采样 采样器堆栈(ModelSamplingSD3 (#130), CFGGuider (#129), BasicScheduler (#126), KSamplerSelect (#128), RandomNoise (#127), SamplerCustomAdvanced (#125))控制指导强度、步骤、采样器类型和种子。增加步骤以获得更多细节和稳定性,并使用固定种子在提示迭代时再现结果。
预览和保存 潜在序列使用VAEDecode (#8)解码,以24 fps的速度用CreateVideo (#101)框定为视频,并由SaveVideo (#102)写入。这为您提供了一个720p的快速预览,准备好进行审核。
1080p 完成(可选) 切换“Video Upscale 1080P”组以启用完成链。潜在上采样器扩展到1920×1080,然后蒸馏超分辨率UNet在两个阶段优化细节。VAEDecodeTiled和第二个CreateVideo/SaveVideo对导出1080p结果。
文本到视频#
步骤1 — 加载模型 加载器获取Hunyuan Video 1.5 720p文本到视频UNet、3D VAE和双文本编码器。此路径不需要起始图像。
步骤3 — 提示 在正编码器CLIP Text Encode (Positive Prompt) (#149)中输入您的描述,并可以选择在CLIP Text Encode (Negative Prompt) (#155)中添加负提示。描述场景、主题、运动和相机,保持语言具体。
步骤4 — 视频大小和时长 EmptyHunyuanVideo15Latent (#183) 使用您选择的宽度、高度和帧数分配初始潜在。使用它来预先定义序列长度,以便调度器和采样器可以计划稳定的去噪轨迹。保持长宽比与预期输出一致,以避免稍后的额外填充。
自定义采样 ModelSamplingSD3 (#165), CFGGuider (#164), BasicScheduler (#161), KSamplerSelect (#163), RandomNoise (#162), 和 SamplerCustomAdvanced (#166) 协作将噪声转化为由您的文本指导的连贯视频。调整步骤和指导以在速度和保真度之间进行权衡,并固定种子以便进行可比运行。
预览和保存 解码帧由CreateVideo (#168) 组装,并由SaveVideo (#167) 保存,进行24 fps的快速720p审核。
1080p 完成(可选) 启用“Video Upscale 1080P”组,将潜在上采样到1080p,并使用蒸馏SR UNet进行优化。两阶段采样在保持运动的同时提高清晰度。平铺解码器和第二个保存阶段导出最终的1080p视频。
Comfyui Hunyuan Video 1.5 工作流程中的关键节点#
HunyuanVideo15ImageToVideo (#78) 通过条件化起始图像和您的提示生成视频。调整其分辨率和总帧数以匹配您的创意目标。更高的分辨率和更长的剪辑增加了VRAM和时间。这一节点对图像到视频的质量至关重要,因为它在采样前融合了CLIP-Vision特征和文本指导。
EmptyHunyuanVideo15Latent (#183) 为文本到视频初始化潜在网格,设置宽度、高度和帧数。使用它来预先定义序列长度,以便调度器和采样器可以计划稳定的去噪轨迹。保持长宽比与预期输出一致,以避免稍后的额外填充。
CFGGuider (#129) 设置无分类器指导强度,在提示遵循和自然性之间取得平衡。增加指导以更严格地遵循提示;降低它以减少过饱和和闪烁。在基础生成期间使用中等值,在超分辨率优化时降低指导。
BasicScheduler (#126) 控制去噪步骤的数量和计划。更多步骤通常意味着更好的细节和稳定性,但渲染时间更长。将步骤数与采样器选择配对以获得最佳结果;此工作流程默认为快速的通用采样器。
SamplerCustomAdvanced (#125) 使用您选择的采样器和指导执行去噪循环。在1080p完成链中,它分为两个阶段,由SplitSigmas分割,首先在较高噪声下建立结构,然后在低噪声细节中进行优化。在调整步骤和指导时保持种子固定,以便可以可靠地比较输出。
HunyuanVideo15LatentUpscaleWithModel (#109) 使用重新打包权重中的专用上采样器将潜在序列缩放到1920×1080。在潜在空间中放大比像素空间调整大小更快,更节省内存,并为蒸馏SR模型添加精细细节做好准备。更大的目标需要更多的VRAM;保持16:9以获得最佳吞吐量。
HunyuanVideo15SuperResolution (#113) 使用Hunyuan Video 1.5捆绑包中的1080p SR蒸馏UNet优化上采样的潜在,选择性地采用起始图像和CLIP-Vision提示以保持一致性。这在保持运动的同时添加清晰的纹理和线条。SR权重在Comfy-Org/HunyuanVideo_1.5_repackaged中可用。
EasyCache (#116) 缓存中间模型状态以加速预览迭代。当您想要更快的周转时启用它,最后通过时禁用以获得最大质量。在使用相同分辨率和时长进行提示迭代时尤其有用。
可选附加功能#
- 保持提示具体。描述主题、运动动词和相机移动。使用简短的负提示抑制您反复看到的伪影。
- 为图像到视频选择干净、高对比度的起始图像。将长宽比与目标分辨率匹配,以最小化填充。
- 为了速度,在较短的时长和720p下迭代;仅在最终运行时打开1080p组。
- 如果VRAM紧张,请切换平铺VAE解码,并考虑在模型加载器暴露的较低精度设置中加载权重。
- 在调整步骤、指导和措辞时固定种子,以使跨运行的变化可测量。
致谢#
此工作流程实现并构建在以下作品和资源之上。我们对Comfy.org为Hunyuan Video 1.5工作流程教程的贡献和维护表示感谢。有关权威细节,请参阅下面链接的原始文档和存储库。
资源#
- Hunyuan Video 1.5 源代码
- 文档/发布说明: Hunyuan Video 1.5 Source
注意:所引用的模型、数据集和代码的使用受其作者和维护者提供的各自许可和条款的约束。