
幻想肖像:在 ComfyUI 中的富有表现力的肖像动画#
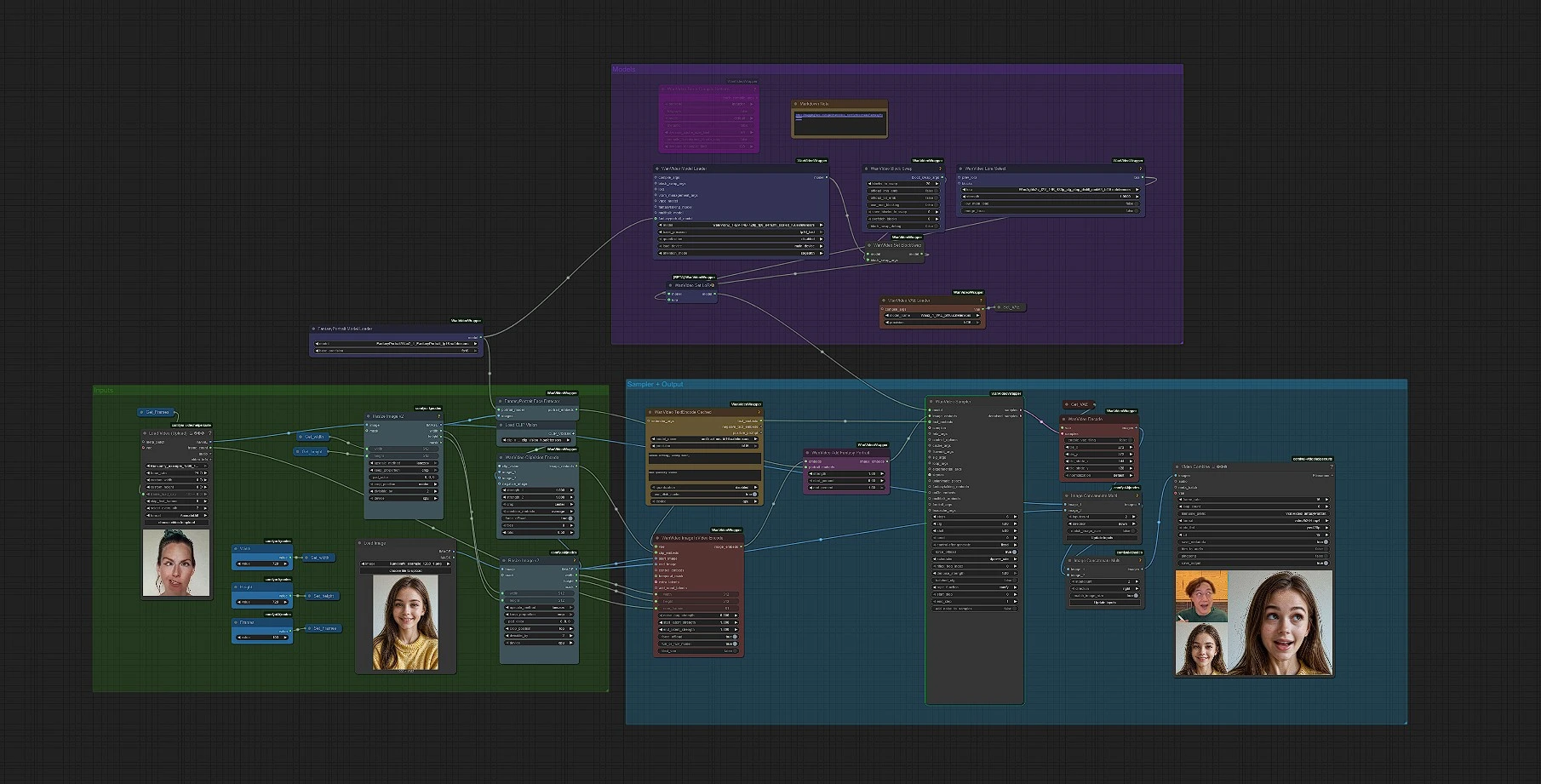
此工作流程将单张静态图像转化为高保真幻想肖像动画。它集成了 Fantasy-AMAP 的 FantasyPortrait 模型,结合了表情增强的扩散变换器,并将其包装在 Wan Video 2.1 图像到视频管道中,因此您可以通过最少的设置生成身份保留、情感丰富的说话镜头。它专为希望从单张照片中获得电影级幻想肖像动作的创作者设计,提供清晰的构图、时长和风格控制。
管道是全自动的:放入一张肖像,选择分辨率和帧数,选择性地添加提示和 LoRA,然后渲染为 MP4。在后台,图形检测面部,编码图像和文本引导,将 Fantasy Portrait 身份嵌入融合到 Wan 的 I2V 条件器中,采样视频,然后解码帧并保存最终剪辑。
ComfyUI 幻想肖像工作流程中的关键模型#
FantasyPortrait (Fantasy-AMAP)
核心身份和表情模块。提供增强表情的嵌入,既能保留主体特征,又能实现细微的面部动作。 GitHub | Paper (arXiv)
WanVideo 2.1 I2V (14B, 720p)
用于从肖像和文本/图像条件中采样动画的视频扩散骨干。量化的、适用于 Comfy 的权重可通过 Kijai 的模型包获取。 Hugging Face: Kijai/WanVideo_comfy
UMT5-XXL 编码器
用于视频采样器中提示引导的高容量文本编码器。 示例权重:umt5-xxl-enc-bf16.safetensors 在 Kijai/WanVideo_comfy
Wan 2.1 VAE
用于编码/解码潜在变量的视频优化 VAE。 示例权重:Wan2_1_VAE_bf16.safetensors 在 Kijai/WanVideo_comfy
如何使用 ComfyUI 幻想肖像工作流程#
工作流程从输入到最终视频从左到右运行。您首先设置三个方面:图像、尺寸和时长。然后,您可以根据需要使用简短提示或 LoRA 进行微调。
1) 图像输入和尺寸调整#
将单张肖像加载到 LoadImage 中,然后调整其大小以进行处理。两个调整阶段确保图像符合您选择的 宽度 和 高度,同时保持构图。使用 Width、Height 和 Frames 控件定义输出大小(默认 720 × 720)和动画长度。这使您的幻想肖像在整个管道中保持一致的构图。
2) 面部检测和幻想肖像嵌入#
FantasyPortraitModelLoader 加载 FantasyPortrait 权重,FantasyPortraitFaceDetector 从您的图像中提取身份和表情感知的肖像嵌入。核心思想是将主体是谁与他们如何表达分开,因此最终动画保留身份,同时允许表现力的动作。除非您更换模型,否则无需在此处进行调整。
3) 图像和文本条件#
对于图像引导,CLIPVisionLoader 与 WanVideoClipVisionEncode 从肖像中生成稳健的视觉特征。对于文本引导,WanVideoTextEncodeCached 使用 UMT5-XXL 编码器将您的正负提示转化为视频条件嵌入。一个简短、简单的提示如“自然工作室特写,温和微笑”通常足以获得干净的幻想肖像外观。
4) I2V 编码和时长控制#
VHS_LoadVideo 用作方便的帧计数器。您可以保留占位符剪辑或加载具有您偏好时长的参考;其帧数提供给 WanVideoImageToVideoEncode,将起始图像加上图像/文本嵌入转化为 I2V 条件。如果您偏好固定长度,只需直接设置 Frames,忽略参考加载器。
5) 幻想肖像融合#
WanVideoAddFantasyPortrait 将 I2V 条件与第 2 步的肖像嵌入合并。这赋予最终幻想肖像动画其强烈的身份保留和表现细节。一旦加载图像,不需要额外输入。
6) LoRA 和模型设置#
WanVideoModelLoader 加载 Wan 2.1,接着 WanVideoLoraSelect 可选择性地应用来自 Kijai 包的轻量级 I2V LoRA,以在不重新训练的情况下偏向动作或美学。如果您想要稍微更具风格化的幻想肖像,同时保持身份不变,这是一个很好的实验点。
7) 视频采样和解码#
WanVideoSampler 使用融合的条件生成潜在帧。保持提示简单,如果需要更多细节,适度增加步骤,避免使用长负面提示过度限制。WanVideoDecode 将潜在变量转换回图像,工作流程连接预览,然后 VHS_VideoCombine 写入 MP4(默认 16 fps,yuv420p)。输出文件名前缀设置为方便。
ComfyUI 幻想肖像工作流程中的关键节点#
FantasyPortraitModelLoader (#138)#
加载 FantasyPortrait 权重。如果您正在测试更新的 Fantasy-AMAP 版本,可以在此处替换。无需调优,但请保持与您的 Wan 模型和 VAE 的精度一致。
FantasyPortraitFaceDetector (#142)#
从调整大小的图像中提取肖像嵌入。良好的结果来自光线充足、正面拍摄且遮挡最小的照片。如果动作看起来不正常,请验证输入裁剪并尝试更干净的源图像。
WanVideoImageToVideoEncode (#151)#
从 CLIP 图像特征、您的起始图像和时长构建 Wan 的 I2V 条件。调整 宽度、高度 和 num_frames 以控制渲染占用和长度。较长的序列需要更多的 VRAM 和时间。
WanVideoAddFantasyPortrait (#150)#
将幻想肖像的身份/表情融入 I2V 条件器。使用此功能可以在启用细微表情变化的同时,使主体在各帧中保持可识别。不需要通常调整的参数。
WanVideoSampler (#149)#
生成视频潜在变量。如果您想要更清晰的细节,可以适度增加步骤。如果动作漂移,减少提示复杂度或尝试不同的 LoRA。保持引导连贯而不是冗长。
WanVideoTextEncodeCached (#155)#
使用 UMT5-XXL 编码正/负提示。使用简短的描述性短语。过于强烈的负面提示(例如,重"坏质量"堆叠)可能会抑制表情。
提示#
- 从方形 720 × 720 和 4 到 6 秒的快速迭代开始,然后根据需要进行扩展。
- 使用干净的、正面光照的肖像,眼睛可见。避免重遮挡、太阳镜或极端角度。
- 保持幻想肖像提示简洁。描述光照和氛围,而不是身份。
- 如果您希望在不丢失身份的情况下获得不同的动作感,可以尝试来自 Kijai 包的轻柔 LoRA。
致谢#
此工作流程利用了来自 Fantasy-AMAP 团队的 幻想肖像 模型,将 表情增强的扩散变换器 集成到 ComfyUI 中,实现全自动、高质量的肖像动画管道。 特别感谢 kijai 创建并集成了 Wan Video Wrapper node,使得在图像到视频框架中无缝运行肖像动画成为可能。 我们还感谢更广泛的 ComfyUI 社区对开放创意工具的持续贡献。
链接: