






Nunchaku Qwen Image редактирование и композитинг нескольких изображений для ComfyUI#
Nunchaku Qwen Image — это рабочий процесс редактирования и композитинга нескольких изображений для ComfyUI с управлением на основе подсказок. Он принимает до трёх эталонных изображений, позволяет указать, как их следует смешивать или трансформировать, и создаёт целостный результат, управляемый естественным языком. Типичные случаи использования включают объединение объектов, замену фонов или перенос стилей и деталей с одного изображения на другое.
Основанный на семействе изображений Qwen, этот рабочий процесс предоставляет художникам, дизайнерам и создателям точный контроль, оставаясь быстрым и предсказуемым. Он также включает маршрут для редактирования одного изображения и чистый маршрут "текст-в-изображение", так что вы можете генерировать, уточнять и композитировать в одной линии Nunchaku Qwen Image.
Примечание: Пожалуйста, выбирайте типы машин в диапазоне от Medium до 2XLarge. Использование типов машин 2XLarge Plus или 3XLarge не поддерживается и приведёт к ошибке запуска.
Ключевые модели в рабочем процессе Comfyui Nunchaku Qwen Image#
- Nunchaku Qwen Image Edit 2509. Диффузионные/DiT веса, оптимизированные для редактирования изображений на основе подсказок и переноса атрибутов. Сильны в локализованных правках, замене объектов и изменении фона. Model card
- Nunchaku Qwen Image (base). Базовый генератор, используемый веткой "текст-в-изображение" для творческого синтеза без исходной фотографии. Model card
- Qwen2.5‑VL 7B текстовый энкодер. Мультимодальная языковая модель, интерпретирующая подсказки и согласующая их с визуальными характеристиками для редактирования и генерации. Model page
- Qwen Image VAE. Вариационный автокодировщик, используемый для кодирования исходных изображений в латенты и декодирования конечных результатов с точными цветами и деталями. Assets
Как использовать рабочий процесс Comfyui Nunchaku Qwen Image#
Этот граф содержит три независимых маршрута, которые используют один и тот же визуальный язык и логику выборки. Используйте одну ветку за раз в зависимости от того, редактируете ли вы несколько изображений, уточняете одно изображение или генерируете из текста.
Nunchaku‑qwen‑image‑edit‑2509 (редактирование и композитинг нескольких изображений)#
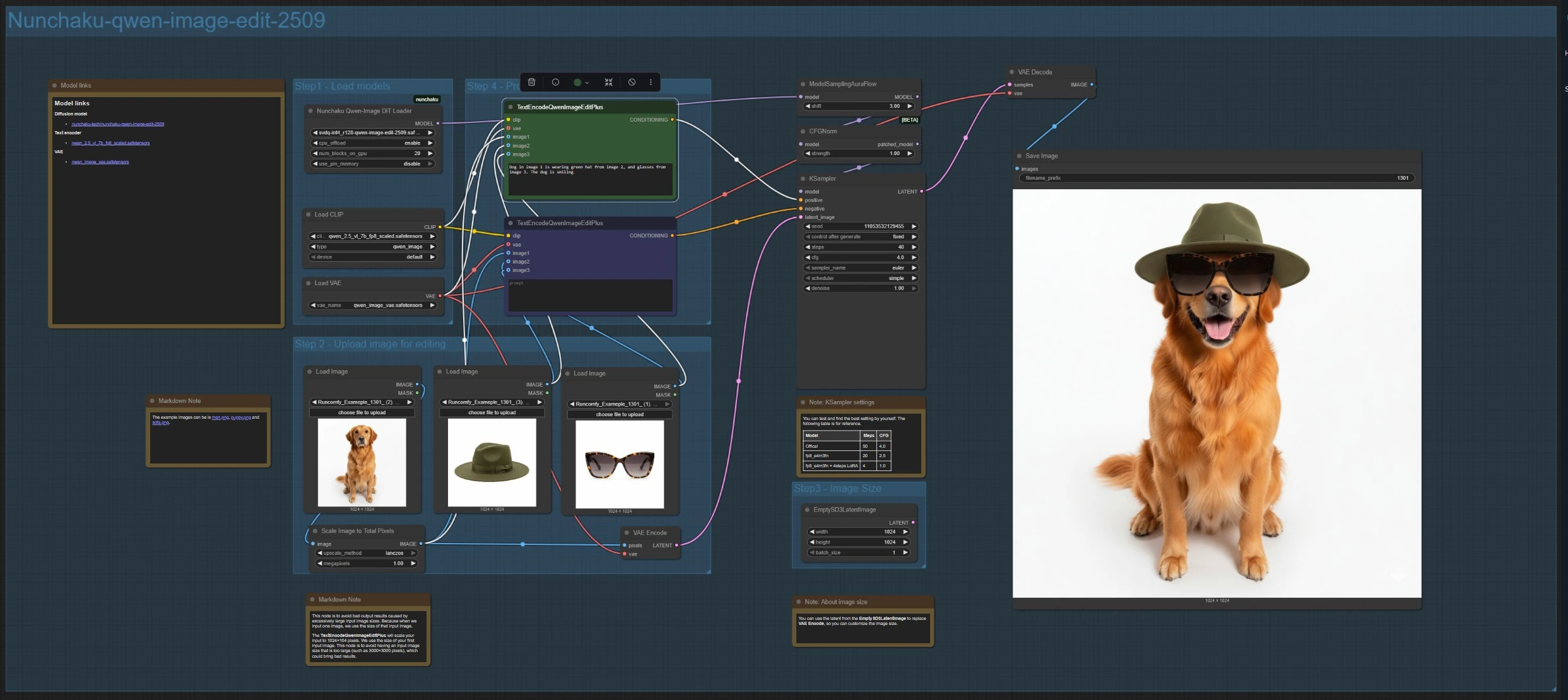
Эта ветка загружает модель редактирования с NunchakuQwenImageDiTLoader (#115), направляет её через ModelSamplingAuraFlow (#66) и CFGNorm (#75), затем синтезирует с помощью KSampler (#3). Загрузите до трёх изображений с помощью LoadImage (#78, #106, #108). Основное эталонное изображение кодируется VAEEncode (#88) для установки холста, а ImageScaleToTotalPixels (#93) поддерживает входные данные в стабильном диапазоне размеров.
Напишите свою инструкцию в TextEncodeQwenImageEditPlus (#111) и, если необходимо, разместите удаления или ограничения в парном TextEncodeQwenImageEditPlus (#110). Явно указывайте источники, например: "Собака на изображении 1 носит зелёную шляпу с изображения 2 и очки с изображения 3." Для пользовательского размера вывода вы можете заменить закодированный латент на EmptySD3LatentImage (#112). Результаты декодируются VAEDecode (#8) и сохраняются с помощью SaveImage (#60).
Nunchaku‑qwen‑image‑edit (уточнение одного изображения)#
Выберите это, когда хотите целенаправленно очистить, изменить фон или скорректировать стиль одного изображения. Модель загружается NunchakuQwenImageDiTLoader (#120), адаптируется ModelSamplingAuraFlow (#125) и CFGNorm (#123), и выборка осуществляется KSampler (#127). Импортируйте своё фото с помощью LoadImage (#129); оно нормализуется ImageScaleToTotalPixels (#130) и кодируется VAEEncode (#131).
Предоставьте свою инструкцию в TextEncodeQwenImageEdit (#121) и дополнительное контрруководство в TextEncodeQwenImageEdit (#122) для сохранения или удаления элементов. Ветка декодируется с помощью VAEDecode (#124) и записывает файлы через SaveImage (#128).
Nunchaku‑qwen‑image (из текста в изображение)#
Используйте эту ветку для создания новых изображений с нуля с помощью базовой модели. NunchakuQwenImageDiTLoader (#146) подаёт в ModelSamplingAuraFlow (#138). Введите свои положительные и отрицательные подсказки в CLIPTextEncode (#143) и CLIPTextEncode (#137). Установите холст с помощью EmptySD3LatentImage (#136), затем генерируйте с KSampler (#141), декодируйте с помощью VAEDecode (#142) и сохраняйте с SaveImage (#147).
Ключевые узлы в рабочем процессе Comfyui Nunchaku Qwen Image#
NunchakuQwenImageDiTLoader (#115) Загружает веса изображения Qwen и вариант, используемый веткой. Выберите модель редактирования для редактирования на основе фото или базовую модель для "текст-в-изображение". Когда VRAM позволяет, более точные или высокоразрешённые варианты могут давать больше деталей; более лёгкие варианты приоритетны для скорости.
TextEncodeQwenImageEditPlus (#111) Управляет редактированием нескольких изображений, анализируя вашу инструкцию и связывая её с до трёх ссылками. Делайте директивы явными, указывая, какое изображение вносит какой атрибут. Используйте краткие формулировки и избегайте противоречивых целей, чтобы правки оставались сосредоточенными.
TextEncodeQwenImageEditPlus (#110) Выступает в качестве парного отрицательного или ограничивающего энкодера для ветки нескольких изображений. Используйте его для исключения объектов, стилей или артефактов, которые вы не хотите видеть. Это часто помогает сохранить композицию, удаляя наложения интерфейса или нежелательные реквизиты.
TextEncodeQwenImageEdit (#121) Положительная инструкция для ветки редактирования одного изображения. Опишите желаемый результат, поверхностные качества и композицию чёткими терминами. Стремитесь к одному-трём предложениям, которые уточняют сцену и изменения.
TextEncodeQwenImageEdit (#122) Отрицательная или ограничивающая подсказка для ветки редактирования одного изображения. Перечислите элементы или черты, которых следует избегать, или опишите элементы, которые нужно удалить из исходного изображения. Это полезно для очистки от случайного текста, логотипов или элементов интерфейса.
ImageScaleToTotalPixels (#93) Предотвращает дестабилизацию результатов из-за слишком больших входных данных, масштабируя до целевого общего количества пикселей. Используйте его для гармонизации разнородных разрешений источников перед композитингом. Если вы замечаете несоответствие резкости между источниками, приведите их к более близкому эффективному размеру здесь.
ModelSamplingAuraFlow (#66) Применяет расписание выборки DiT/flow‑matching, настроенное для моделей изображений Qwen. Если выходы выглядят тёмными, размытыми или без структуры, увеличьте сдвиг расписания для стабилизации глобального тона; если они выглядят плоскими, уменьшите сдвиг для добавления деталей.
KSampler (#3) Главный сэмплер, где вы балансируете скорость, точность и стохастическое разнообразие. Настройте шаги и шкалу руководства для согласованности против креативности, выберите метод сэмплирования и зафиксируйте семя, когда хотите точную воспроизводимость между запусками.
CFGNorm (#75) Нормализует руководство без классификатора, чтобы уменьшить перенасыщение или взрывы контраста при более высоких шкалах руководства. Оставьте его на пути, как предоставлено; он помогает поддерживать стабильные цвет и экспозицию, пока вы экспериментируете с подсказками.
Дополнительные возможности#
- Для лучших результатов при работе с несколькими изображениями выбирайте источники с похожей перспективой и освещением; модель редактирования Nunchaku Qwen Image затем сосредоточится на содержании, а не на исправлении геометрии.
- Указывайте источники по порядку ("изображение 1", "изображение 2", "изображение 3") и будьте явными в том, какие атрибуты куда переносятся.
- Когда выходы кажутся тёмными или размытыми, поднимите сдвиг
ModelSamplingAuraFlow; когда хотите больше текстуры, попробуйте немного снизить сдвиг. - Чтобы установить определённое разрешение, замените закодированный латент на
EmptySD3LatentImageв используемой вами ветке. - Используйте отрицательные подсказки для удаления текста интерфейса, водяных знаков или нежелательных объектов, прежде чем вкладываться в детализированный стиль; это сохраняет правки Nunchaku Qwen Image чистыми с самого начала.
Признания#
Этот рабочий процесс реализует и основывается на следующих работах и ресурсах. Мы благодарны Nunchaku за рабочий процесс Qwen-Image (ComfyUI-nunchaku) за их вклад и поддержку. Для авторитетных деталей, пожалуйста, обращайтесь к оригинальной документации и репозиториям, указанным ниже.
Ресурсы#
- Nunchaku/Qwen-Image
- GitHub: nunchaku-tech/ComfyUI-nunchaku
- Hugging Face: nunchaku-tech/nunchaku-qwen-image
- arXiv: SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
- Документы / Примечания к выпуску: Nunchaku Qwen Image Source
Примечание: Использование указанных моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и поддерживающими организациями.



