
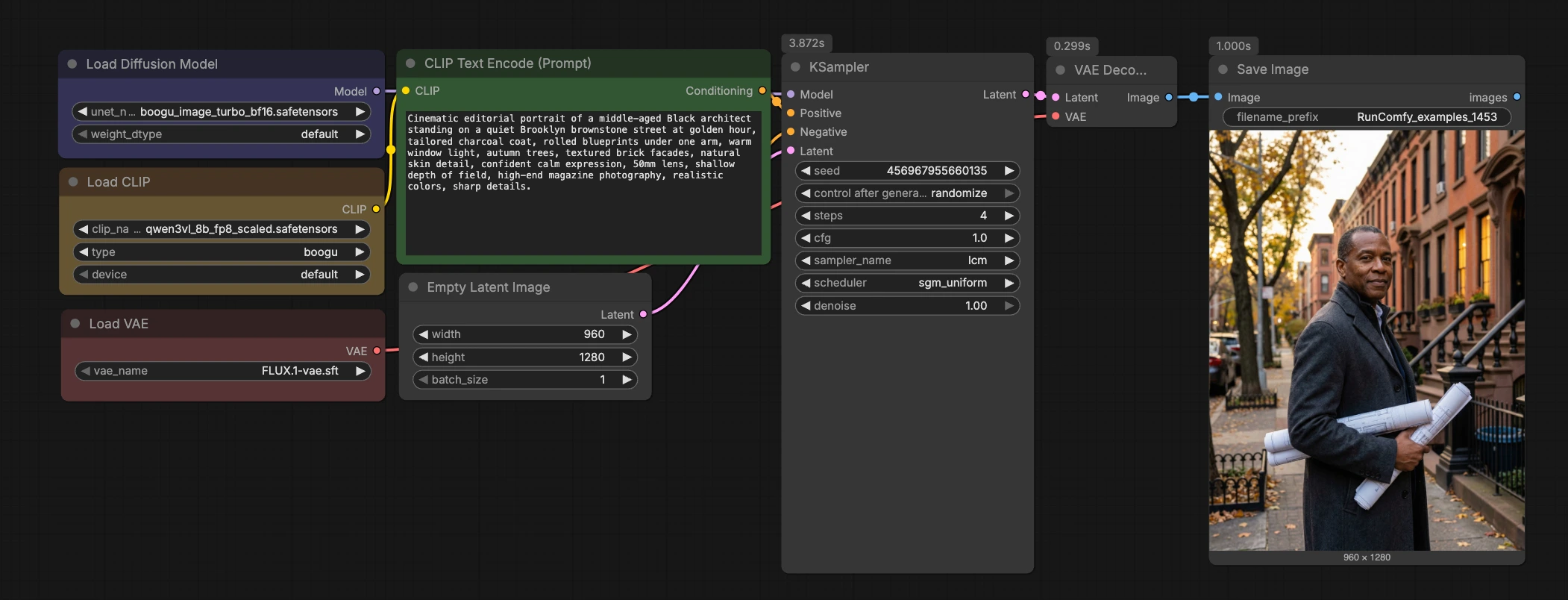






Boogu Turbo text-to-image ComfyUI workflow#
Этот процесс Boogu Turbo text-to-image ComfyUI предлагает чистый и быстрый путь от запроса до изображения, используя контрольную точку Boogu-Image-0.1-Turbo с четырехшаговой LCM выборкой. Он сочетает Qwen3-VL text encoder с FLUX.1 VAE, чтобы вы могли быстро итеративно работать, сохраняя график минимальным и легким для повторного использования в различных проектах.
Разработанный для быстрого визуального исследования, процесс превосходит в создании кинематографических окружений, аниме-стилей фонов, атмосферных пейзажей, воображаемых продуктовых машин и архитектурных сцен. Если вам нужен легковесный процесс Boogu Turbo text-to-image ComfyUI, готовый к RunComfy и простой для анализа, этот шаблон является сильной отправной точкой.
Основные модели в Comfyui Boogu Turbo text-to-image ComfyUI workflow#
- Boogu-Image-0.1-Turbo. Дистиллированный вариант Turbo создан для быстрого, фотореалистичного text-to-image с типичной 3–4-шаговой интерпретацией и шкалой руководства около 1.0. Официальные веса модели и инструкции доступны на Hugging Face, с предоставленными ComfyUI-готовыми перепакованными файлами от Comfy-Org. См. Boogu/Boogu-Image-0.1-Turbo-fp8 и упакованный ComfyUI пакет на Comfy-Org/Boogu-Image.
- Qwen3-VL 8B text encoder. Этот современный vision-language backbone используется здесь исключительно как text encoder для создания сильных эмбеддингов запроса для диффузионной модели. ComfyUI-упакованные энкодеры размещены на Comfy-Org/Qwen3-VL и официальный репозиторий QwenLM/Qwen3-VL.
- FLUX.1 VAE. Автоэнкодер от Black Forest Labs кодирует и декодирует изображения между пиксельным и латентным пространством, помогая сохранять цвет и контраст. Ссылочные веса и документация находятся на black-forest-labs/FLUX.1-dev.
Как использовать Comfyui Boogu Turbo text-to-image ComfyUI workflow#
Вкратце, процесс кодирует ваш запрос, инициализирует латентный холст, запускает быстрый LCM sampler через Boogu-Image-0.1-Turbo, декодирует с помощью FLUX.1 VAE и сохраняет результат. График намеренно компактный, чтобы вы могли вставить его в другие проекты или расширить с помощью LoRAs, ControlNets или цепочек постобработки.
Кодирование запроса с Qwen3-VL (CLIPLoader (#7) → CLIPTextEncode (#11))#
На этом этапе загружается Qwen3-VL encoder и ваш текстовый запрос преобразуется в векторы кондиционирования. Введите ваш запрос в CLIPTextEncode (#11) с использованием естественного языка; такие детализированные фотоподсказки, как объектив, освещение, время суток и текстура, работают хорошо. Негативный ввод намеренно обнулен через ConditioningZeroOut (#9) для сохранения стабильных результатов в низком руководящем режиме Turbo. Если вы предпочитаете явные негативы, замените ConditioningZeroOut на второй CLIPTextEncode, чтобы предоставить негативный запрос. Хорошая гигиена запросов здесь уменьшает необходимость в высоком CFG или дополнительных шагах позже.
Настройка латентности и загрузка модели (EmptyLatentImage (#8) + UNETLoader (#2))#
EmptyLatentImage (#8) создает латентный холст. Стандартный портретный формат 960×1280 является сбалансированной отправной точкой для людей, интерьеров и высоких снимков продуктов; вы можете установить другие размеры для квадратов или широких форматов. UNETLoader (#2) загружает веса Boogu Turbo диффузии из пакета Comfy-Org, выравнивая модель с выбранным вами encoder и VAE. Замена BF16 и FP8 вариантов проста, если вам нужно сбалансировать VRAM и пропускную способность. Сохраняйте выбор модели согласованным в вашем проекте, чтобы поддерживать стилевую целостность.
Быстрая выборка LCM (KSampler (#32) с sampler lcm)#
KSampler настроен для Latent Consistency Models для достижения высокого качества примерно за четыре шага. Дистилляция LCM нацелена на очень низкие значения руководства, поэтому этот процесс Boogu Turbo text-to-image ComfyUI работает стабильно с CFG около 1.0, сохраняя приверженность запросу. Если вы хотите добавить больше микро-деталей, увеличьте количество шагов умеренно и зафиксируйте зерно для сравнений A/B. Для изменений стиля или композиции, перезапустите зерно и уточните запрос, а не увеличивайте шаги слишком высоко. Теория на фоне LCM интерпретации в несколько шагов описана в оригинальной статье Latent Consistency Models.
Декодирование и сохранение (VAELoader (#5) → VAEDecode (#3) → SaveImage (#58))#
FLUX.1 VAE, загруженный в VAELoader (#5), декодирует латенты в RGB в VAEDecode (#3). Соответствие семейства VAE с вашей диффузионной основой обычно дает более верные цвета и текстуры, поэтому этот график поставляется с FLUX.1 VAE. SaveImage (#58) записывает результаты на диск; измените префикс выхода, чтобы организовать эксперименты по запросу, зерну или соотношению сторон. Если вы позже добавите масштабаторы или пост-фx, разветвите от вывода Image VAEDecode, чтобы сохранить чистую историю.
Основные узлы в Comfyui Boogu Turbo text-to-image ComfyUI workflow#
CLIPTextEncode (#11)#
Этот узел содержит ваш основной текстовый запрос и создает положительное кондиционирование, используемое sampler. Держите запросы краткими и добавляйте подсказки сцены, такие как фокусное расстояние камеры, время суток и прилагательные материала. Если вы хотите использовать негативные запросы, создайте второй CLIPTextEncode и подключите его к негативному вводу sampler, удалив ConditioningZeroOut (#9).
ConditioningZeroOut (#9)#
Это отключает негативное кондиционирование, подавая нулевой вектор в негативный порт sampler. Оставить его на месте - это хороший вариант по умолчанию для конфигурации с низким руководством Turbo. Удаляйте его только тогда, когда вам нужны негативные запросы и вы можете их четко сформулировать.
EmptyLatentImage (#8)#
Управляет размерами вывода и размером пакета. Начните с 960×1280 для портретов или 1280×960 для более широких окружений; корректируйте в зависимости от предмета и бюджета памяти. Большие латенты предоставляют больше холста для мелких деталей, но увеличивают использование VRAM и время декодирования.
UNETLoader (#2)#
Выбирает контрольную точку Boogu-Image-0.1-Turbo для генерации. Используйте вариант BF16 для наивысшей точности на способных GPU или вариант FP8 для меньшего использования VRAM и более быстрых загрузок, оба доступны в пакете Comfy-Org. Файлы моделей и их предполагаемые каталоги документированы на Comfy-Org/Boogu-Image.
KSampler (#32)#
Запускает процесс диффузии с lcm sampler для интерпретации в несколько шагов. Основные рычаги - это зерно, количество шагов и CFG; Turbo разработан для работы с очень низким руководством и несколькими шагами, сохраняя качество, как отражено в официальных настройках Turbo на карточке модели на Boogu/Boogu-Image-0.1-Turbo-fp8. Для контролируемых исследований, зафиксируйте зерно и изменяйте шаги или формулировку запроса по одному изменению за раз.
VAELoader (#5) и VAEDecode (#3)#
Загрузите и примените FLUX.1 VAE для декодирования. Соблюдение семейства FLUX.1 сохраняет цвета, контраст и поведение текстур согласованными с настройками тренировки UNet. Смешивание VAE возможно, но может незначительно изменить тональность или насыщенность; тестируйте перед тем, как принять новый вид. Ссылочные веса: black-forest-labs/FLUX.1-dev.
SaveImage (#58)#
Управляет именованием и назначением вывода. Используйте значимые префиксы, такие как название проекта, тег соотношения или зерно, чтобы сохранить организованность запусков. При расширении конвейера разветвите здесь, чтобы добавить масштабаторы, цветокоррекцию или генераторы подписей, не нарушая базовое сохранение.
Дополнительные возможности#
- Держите CFG около 1.0 и шаги около четырех для самых быстрых итераций; переходите к 6–8 шагам только когда вам нужно немного больше текстуры или стабильности.
- Перезапускайте зерно, чтобы изучить композицию; фиксируйте зерно, чтобы уточнить стиль и микро-детали.
- Предпочитайте BF16 веса для наилучшего качества на высокопамятных GPU; переключайтесь на FP8, чтобы ускорить загрузку и уменьшить VRAM.
- Для читаемости текста в изображении попробуйте немного более высокое разрешение и включите явные типографические подсказки в запросе.
- Сохраняйте промежуточные избранные часто; небольшие изменения запроса в этом процессе Boogu Turbo text-to-image ComfyUI могут привести к значительным различиям в сценах за считанные секунды.
Признания#
Этот процесс реализует и опирается на следующие работы и ресурсы. Мы с благодарностью признаем RunningHub за ссылку на процесс, Boogu за репозиторий Boogu-Image и модель Boogu-Image-0.1-Turbo, Comfy-Org за веса Boogu ComfyUI и ComfyUI за учебник Boogu за их вклад и поддержку. Для авторитетных деталей, пожалуйста, обратитесь к оригинальной документации и репозиториям, приведенным ниже.
Ресурсы#
- RunningHub/Ссылка на процесс
- Документы / Примечания к выпуску: RunningHub post
- Boogu/Сайт проекта
- Документы / Примечания к выпуску: boogu.org
- Boogu/Boogu Image репозиторий
- GitHub: boogu-project/Boogu-Image
- Hugging Face: Boogu/Boogu-Image-0.1-Turbo
- Boogu/Boogu-Image-0.1-Turbo модель
- Hugging Face: Boogu/Boogu-Image-0.1-Turbo
- GitHub: boogu-project/Boogu-Image
- Comfy-Org/Boogu ComfyUI веса
- Hugging Face: Comfy-Org/Boogu-Image
- ComfyUI/Boogu учебник
- Документы / Примечания к выпуску: ComfyUI tutorial
Примечание: использование упомянутых моделей, наборов данных и кода подлежит соответствующим лицензиям и условиям, предоставленным их авторами и кураторами.



