
Wan2.1 Stand In: geração de vídeo consistente com personagem a partir de uma única imagem para ComfyUI#
Este fluxo de trabalho transforma uma imagem de referência em um vídeo curto onde o mesmo rosto e estilo persistem ao longo dos quadros. Alimentado pela família Wan 2.1 e um Stand In LoRA construído para esse propósito, é projetado para contadores de histórias, animadores e criadores de avatares que precisam de identidade estável com configuração mínima. O pipeline Wan2.1 Stand In cuida da limpeza do fundo, corte, mascaramento e incorporação, para que você possa se concentrar no seu prompt e movimento.
Use o fluxo de trabalho Wan2.1 Stand In quando você quiser continuidade de identidade confiável a partir de uma única foto, iteração rápida e MP4s prontos para exportação, além de uma saída de comparação lado a lado opcional.
Modelos principais no fluxo de trabalho Comfyui Wan2.1 Stand In#
- Wan 2.1 Text‑to‑Video 14B. O gerador principal responsável pela coerência temporal e movimento. Suporta geração 480p e 720p e integra-se com LoRAs para comportamentos e estilos direcionados. Model card
- Wan‑VAE para Wan 2.1. Um VAE espaciotemporal de alta eficiência que codifica e decodifica latentes de vídeo enquanto preserva pistas de movimento. Sustenta as etapas de codificação/decodificação de imagem neste fluxo de trabalho. Veja os recursos do modelo Wan 2.1 e as notas de integração Diffusers para uso do VAE. Model hub • Diffusers docs
- Stand In LoRA para Wan 2.1. Um adaptador de consistência de personagem treinado para bloquear a identidade a partir de uma única imagem; neste gráfico, é aplicado na carga do modelo para garantir que o sinal de identidade seja fundido na base. Files
- LightX2V Step‑Distill LoRA (opcional). Um adaptador leve que pode melhorar o comportamento de orientação e a eficiência com Wan 2.1 14B. Model card
- Módulo VACE para Wan 2.1 (opcional). Permite controle de movimento e edição por meio de condicionamento ciente de vídeo. O fluxo de trabalho inclui um caminho de incorporação que você pode habilitar para controle VACE. Model hub
- Codificador de texto UMT5‑XXL. Fornece codificação de prompt multilíngue robusta para Wan 2.1 text‑to‑video. Model card
Como usar o fluxo de trabalho Comfyui Wan2.1 Stand In#
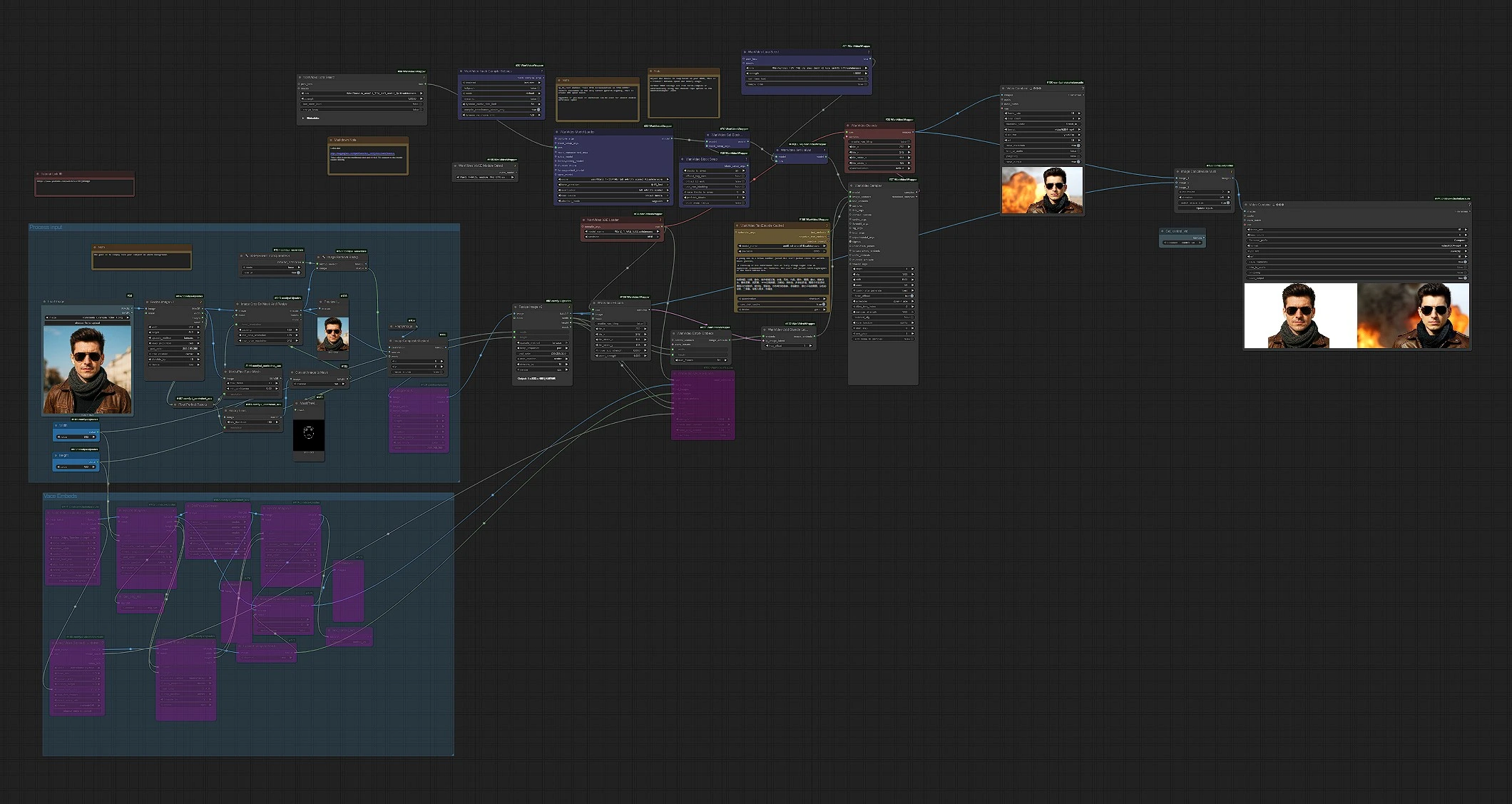
Em resumo: carregue uma imagem de referência limpa e voltada para frente, o fluxo de trabalho prepara uma máscara e composição focada no rosto, codifica-a em um latente, mescla essa identidade nos embeds de imagem Wan 2.1, então amostra quadros de vídeo e exporta MP4. Duas saídas são salvas: a renderização principal e uma comparação lado a lado.
Processar entrada (grupo)#
Comece com uma imagem bem iluminada e voltada para frente em um fundo simples. O pipeline carrega sua imagem em LoadImage (#58), padroniza o tamanho com ImageResizeKJv2 (#142) e cria uma máscara centrada no rosto usando MediaPipe-FaceMeshPreprocessor (#144) e BinaryPreprocessor (#151). O fundo é removido em TransparentBGSession+ (#127) e ImageRemoveBackground+ (#128), então o sujeito é composto sobre uma tela limpa com ImageCompositeMasked (#108) para minimizar o sangramento de cores. Finalmente, ImagePadKJ (#129) e ImageResizeKJv2 (#68) alinham o aspecto para geração; o quadro preparado é codificado em um latente via WanVideoEncode (#104).
Embeds VACE (grupo opcional)#
Se você quiser controle de movimento de um clipe existente, carregue-o com VHS_LoadVideo (#161) e opcionalmente um guia secundário ou vídeo alfa com VHS_LoadVideo (#168). Os quadros passam por DWPreprocessor (#163) para pistas de pose e ImageResizeKJv2 (#169) para correspondência de forma; ImageToMask (#171) e ImageCompositeMasked (#174) permitem que você misture imagens de controle com precisão. WanVideoVACEEncode (#160) transforma estes em embeddings VACE. Este caminho é opcional; deixe-o intocado quando você quiser movimento dirigido por texto apenas de Wan 2.1.
Modelo, LoRAs e texto#
WanVideoModelLoader (#22) carrega a base Wan 2.1 14B mais o Stand In LoRA para que a identidade seja incorporada desde o início. Recursos de velocidade amigáveis ao VRAM estão disponíveis através de WanVideoBlockSwap (#39) e aplicados com WanVideoSetBlockSwap (#70). Você pode anexar um adaptador extra, como LightX2V via WanVideoSetLoRAs (#79). Os prompts são codificados com WanVideoTextEncodeCached (#159), usando UMT5‑XXL nos bastidores para controle multilíngue. Mantenha os prompts concisos e descritivos; enfatize a roupa, o ângulo e a iluminação do sujeito para complementar a identidade do Stand In.
Incorporação de identidade e amostragem#
WanVideoEmptyEmbeds (#177) estabelece a forma alvo para embeddings de imagem, e WanVideoAddStandInLatent (#102) injeta seu latente de referência codificado para carregar a identidade ao longo do tempo. As embeddings de imagem e texto combinadas alimentam WanVideoSampler (#27), que gera uma sequência de vídeo latente usando o agendador e etapas configuradas. Após a amostragem, os quadros são decodificados com WanVideoDecode (#28) e escritos em um MP4 em VHS_VideoCombine (#180).
Visualizar e exportar comparação#
Para QA instantâneo, ImageConcatMulti (#122) empilha os quadros gerados ao lado da referência redimensionada para que você possa julgar a semelhança quadro a quadro. VHS_VideoCombine (#74) salva isso como um MP4 "Compare" separado. O fluxo de trabalho Wan2.1 Stand In, portanto, produz um vídeo final limpo mais uma verificação lado a lado sem esforço extra.
Nós principais no fluxo de trabalho Comfyui Wan2.1 Stand In#
WanVideoModelLoader(#22). Carrega Wan 2.1 14B e aplica o Stand In LoRA na inicialização do modelo. Mantenha o adaptador Stand In conectado aqui em vez de mais tarde no gráfico para que a identidade seja imposta ao longo do caminho de remoção de ruído. Emparelhe comWanVideoVAELoader(#38) para o Wan‑VAE correspondente.WanVideoAddStandInLatent(#102). Funde seu latente de imagem de referência codificado nos embeddings de imagem. Se a identidade se desviar, aumente sua influência; se o movimento parecer excessivamente restrito, reduza-o ligeiramente.WanVideoSampler(#27). O gerador principal. Ajustar etapas, escolha do agendador e estratégia de orientação aqui tem o maior impacto no detalhe, riqueza de movimento e estabilidade temporal. Ao aumentar a resolução ou o comprimento, considere ajustar as configurações do amostrador antes de alterar qualquer coisa a montante.WanVideoSetBlockSwap(#70) comWanVideoBlockSwap(#39). Troca memória GPU por velocidade trocando blocos de atenção entre dispositivos. Se você ver erros de falta de memória, aumente o descarregamento; se você tiver espaço, reduza o descarregamento para iteração mais rápida.ImageRemoveBackground+(#128) eImageCompositeMasked(#108). Estes garantem que o sujeito seja isolado de maneira limpa e colocado em uma tela neutra, o que reduz a contaminação de cores e melhora o bloqueio de identidade do Stand In ao longo dos quadros.VHS_VideoCombine(#180). Controla a codificação, taxa de quadros e nomeação de arquivos para a saída principal MP4. Use-o para definir seu FPS preferido e alvo de qualidade para entrega.
Extras opcionais#
- Use uma referência voltada para frente e bem iluminada em um fundo simples para melhores resultados. Pequenas rotações ou oclusões pesadas podem enfraquecer a transferência de identidade.
- Mantenha os prompts concisos; descreva roupas, humor e iluminação que correspondam à sua referência. Evite descritores de rosto conflitantes que lutem contra o sinal do Wan2.1 Stand In.
- Se o VRAM estiver apertado, aumente a troca de blocos ou reduza a resolução primeiro. Se você tiver espaço de manobra, tente habilitar otimizações de compilação na pilha de carregadores antes de aumentar as etapas.
- O Stand In LoRA é não padrão e deve ser conectado na carga do modelo; siga o padrão neste gráfico para manter a identidade estável. Arquivos LoRA: Stand‑In
- Para controle avançado, habilite o caminho VACE para direcionar o movimento com um clipe guia. Comece sem ele se você quiser movimento puramente dirigido por texto de Wan 2.1.
Recursos
- Wan 2.1 14B T2V: Hugging Face
- Wan 2.1 VACE: Hugging Face
- Stand In LoRA: Hugging Face
- LightX2V Step‑Distill LoRA: Hugging Face
- Codificador UMT5‑XXL: Hugging Face
- Nós do wrapper WanVideo: GitHub
- Utilitários KJNodes usados para redimensionamento, preenchimento e mascaramento: GitHub
- Pré-processadores Aux ControlNet (MediaPipe Face Mesh, DWPose): GitHub
Agradecimentos#
Este fluxo de trabalho implementa e se baseia em trabalhos e recursos do ArtOfficial Labs. Agradecemos sinceramente ao ArtOfficial Labs e aos autores do Wan 2.1 por Wan2.1 Demo por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- Wan 2.1/Wan2.1 Demo
- Docs / Notas de Lançamento: Wan2.1 Demo
Nota: O uso dos modelos, conjuntos de dados e códigos referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.

