
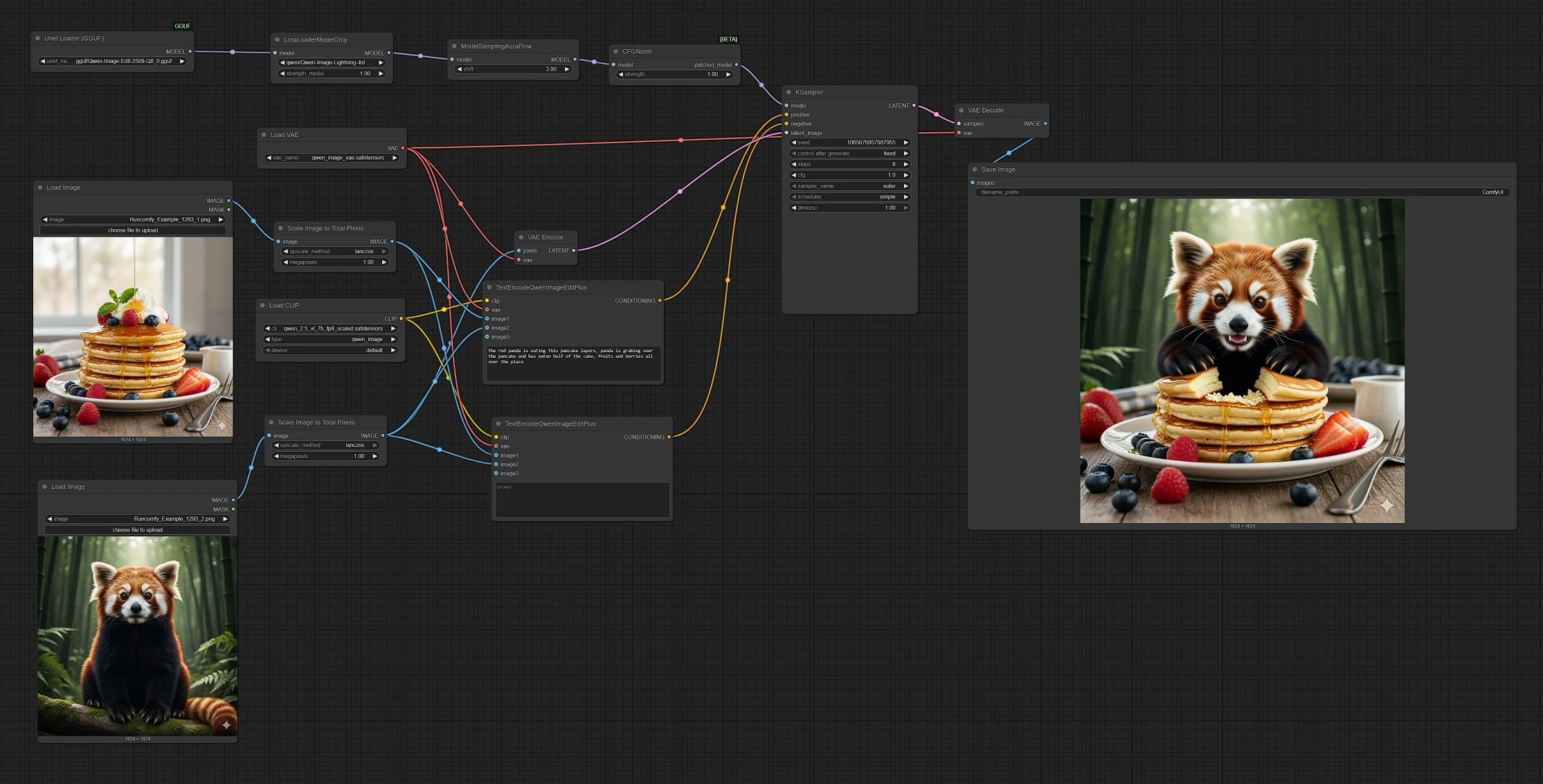






Qwen Image Edit 2509: edição e mistura multi-imagem orientada por prompt para ComfyUI#
Qwen Image Edit 2509 é um fluxo de trabalho de edição multi-imagem para ComfyUI que funde 2–3 imagens de entrada sob um único prompt para criar edições precisas e misturas contínuas. É projetado para criadores que desejam compor objetos, reestilizar cenas, substituir elementos ou mesclar referências enquanto mantêm o controle intuitivo e previsível.
Este gráfico do ComfyUI combina o modelo de imagem Qwen com um codificador de texto ciente de edição para que você possa direcionar resultados com linguagem natural e uma ou mais referências visuais. Fora da caixa, o Qwen Image Edit 2509 lida com transferência de estilo, inserção de objetos e remixes de cena, produzindo resultados coerentes mesmo quando as fontes variam em aparência ou qualidade.
Principais modelos no fluxo de trabalho Comfyui Qwen Image Edit 2509#
- Qwen Image Edit 2509 (Modelo de Difusão & GGUF, Q8_0). O ponto de verificação principal de edição de imagem, carregado em forma quantizada para reduzir VRAM enquanto preserva o comportamento de edição. Ele fornece a base de difusão que interpreta texto e imagens de referência durante a amostragem.
- Qwen Image VAE. Um VAE dedicado adaptado para Qwen Image que codifica a tela base para espaço latente e decodifica os resultados finais de volta para pixels. Fonte do ativo: Comfy-Org/Qwen-Image_ComfyUI.
- Codificador de texto Qwen 2.5 VL 7B (FP8 escalado). Um codificador de texto de visão-linguagem empacotado para ComfyUI que transforma seu prompt mais imagens de referência em condições de edição. Fonte do ativo: Comfy-Org/Qwen-Image_ComfyUI.
- Qwen‑Image‑Lightning‑4steps‑V1.0 LoRA. Um LoRA opcional que inclina o modelo para atualizações rápidas e de alto impacto, útil para iterações rápidas ou contagens de passos baixas. Página do modelo: lightx2v/Qwen-Image-Lightning.
Como usar o fluxo de trabalho Comfyui Qwen Image Edit 2509#
Este fluxo de trabalho segue um caminho claro de entradas para saída: você carrega 2–3 imagens, escreve um prompt, o gráfico codifica tanto o texto quanto as referências, a amostragem ocorre sobre uma base latente, e o resultado é decodificado e salvo.
Etapa 1 — Carregue e dimensione suas fontes
- Use
LoadImage(#103) para a Imagem 1 eLoadImage(#109) para a Imagem 2. A Imagem 2 atua como a tela base que receberá as edições. - Cada imagem passa por
ImageScaleToTotalPixels(#93 e #108) para que ambas as referências compartilhem um orçamento de pixels consistente. Isso estabiliza a composição e a transferência de estilo. - Se você quiser uma terceira referência, conecte outro
LoadImagena entradaimage3nos nós de codificação. O Qwen Image Edit 2509 aceita até três imagens para uma orientação mais rica.
Etapa 2 — Escreva o prompt e defina a intenção
- O codificador positivo
TextEncodeQwenImageEditPlus(#104) combina seu prompt de texto com a Imagem 1 e a Imagem 2 para descrever o resultado que você deseja. Use linguagem natural para solicitar mesclagens, substituições ou sugestões de estilo. - O codificador negativo
TextEncodeQwenImageEditPlus(#106) permite que você se afaste de detalhes indesejados. Mantenha-o vazio para permanecer neutro ou adicione frases que suprimam artefatos ou estilos que você não deseja. - Ambos os codificadores usam o codificador de texto Qwen e o VAE, para que o modelo "veja" suas referências como parte da instrução.
Etapa 3 — Prepare o modelo
UnetLoaderGGUF(#102) carrega a base Qwen Image Edit 2509 no formato GGUF para inferência eficiente.LoraLoaderModelOnly(#89) aplica o LoRA Qwen‑Image‑Lightning. Aumente sua influência para edições mais marcantes ou reduza para atualizações mais conservadoras.- O modelo é então preparado para amostragem com uma configuração ajustada para estabilidade de edição.
Etapa 4 — Geração guiada
- A tela base (Imagem 2) é codificada por
VAEEncode(#88) e fornecida paraKSampler(#3) como o latente inicial. Isso torna a execução de imagem-para-imagem em vez de texto-puro-para-imagem. KSampler(#3) funde as condições positivas e negativas com a tela latente para produzir o resultado editado. Trave a semente para reprodutibilidade ou varie-a para explorar alternativas.- As escolhas de orientação e amostragem equilibram a fidelidade às suas fontes com a adesão ao prompt, dando ao Qwen Image Edit 2509 sua mistura de precisão e flexibilidade.
Etapa 5 — Decodifique e salve
VAEDecode(#8) converte o latente final em uma imagem, eSaveImage(#60) a escreve na sua pasta de saída. Os nomes dos arquivos refletem a execução para que você possa comparar versões facilmente.
Principais nós no fluxo de trabalho Comfyui Qwen Image Edit 2509#
TextEncodeQwenImageEditPlus (#104)#
Este nó cria a condição de edição positiva combinando seu prompt com até três imagens de referência via o codificador Qwen. Use-o para especificar o que deve aparecer, qual estilo adotar e quão fortemente as referências devem influenciar o resultado. Comece com um objetivo claro em uma única frase, depois adicione descritores de estilo ou dicas de câmera conforme necessário. Os ativos para o codificador são empacotados em Comfy-Org/Qwen-Image_ComfyUI.
TextEncodeQwenImageEditPlus (#106)#
Este nó forma a condição negativa para prevenir traços indesejados. Adicione frases curtas que bloqueiem artefatos, suavização excessiva ou estilos incompatíveis. Mantenha-o mínimo para evitar conflito com a intenção positiva. Ele usa o mesmo codificador Qwen e pilha VAE que o caminho positivo.
UnetLoaderGGUF (#102)#
Carrega o ponto de verificação Qwen Image Edit 2509 no formato GGUF para inferência amigável à VRAM. Quantização mais alta economiza memória mas pode afetar levemente detalhes finos; se você tiver espaço, tente uma quantização menos agressiva para maximizar a fidelidade. Referência de implementação: city96/ComfyUI-GGUF.
LoraLoaderModelOnly (#89)#
Aplica o LoRA Qwen‑Image‑Lightning em cima do modelo base para acelerar a convergência e fortalecer edições. Aumente strength_model para enfatizar o efeito deste LoRA ou diminua para orientação sutil. Página do modelo: lightx2v/Qwen-Image-Lightning. Referência do nó principal: comfyanonymous/ComfyUI.
ImageScaleToTotalPixels (#93, #108)#
Redimensiona cada entrada para uma contagem total de pixels consistente usando reamostragem de alta qualidade. Aumentar o alvo de megapixels gera resultados mais nítidos ao custo de tempo e memória; diminuí-lo acelera a iteração. Mantenha ambas as referências em escalas semelhantes para ajudar o Qwen Image Edit 2509 a mesclar elementos de forma limpa. Referência do nó principal: comfyanonymous/ComfyUI.
KSampler (#3)#
Executa as etapas de difusão que transformam a tela latente de acordo com suas condições. Ajuste as etapas e o amostrador para equilibrar velocidade e fidelidade, e varie a semente para explorar múltiplas composições a partir da mesma configuração. Para edições apertadas que preservam a estrutura da Imagem 2, mantenha a contagem de etapas moderada e confie no prompt e nas referências para controle. Referência do nó principal: comfyanonymous/ComfyUI.
Extras opcionais#
- Trate a Imagem 2 como a tela e a Imagem 1 como a doadora; descreva no prompt quais elementos devem ser transferidos e quais devem permanecer.
- Use negativos concisos para conter halos, desvio de textura ou superestilização; listas negativas longas podem conflitar com seu objetivo.
- Se os resultados parecerem muito conservadores, aumente ligeiramente a força do LoRA ou os passos de amostragem; se eles se desviarem muito da base, reduza-os.
- Aumente o alvo de megapixels ao finalizar, então reutilize a mesma semente para aumentar a escala da composição exata que você gostou.
- Mantenha os prompts concretos: sujeito, ação, cenário e estilo. O Qwen Image Edit 2509 responde melhor a intenções claras com alguns descritores fortes.
Agradecimentos#
Este fluxo de trabalho implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos profundamente a RobbaW pelo Qwen Image Edit 2509 Workflow por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- RobbaW/Qwen Image Edit 2509 Workflow
- Hugging Face: QuantStack/Qwen-Image-Edit-2509-GGUF
- Docs / Release Notes: Qwen Image Edit 2509 Workflow @RobbaW from Reddit r/comfyui
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.





