
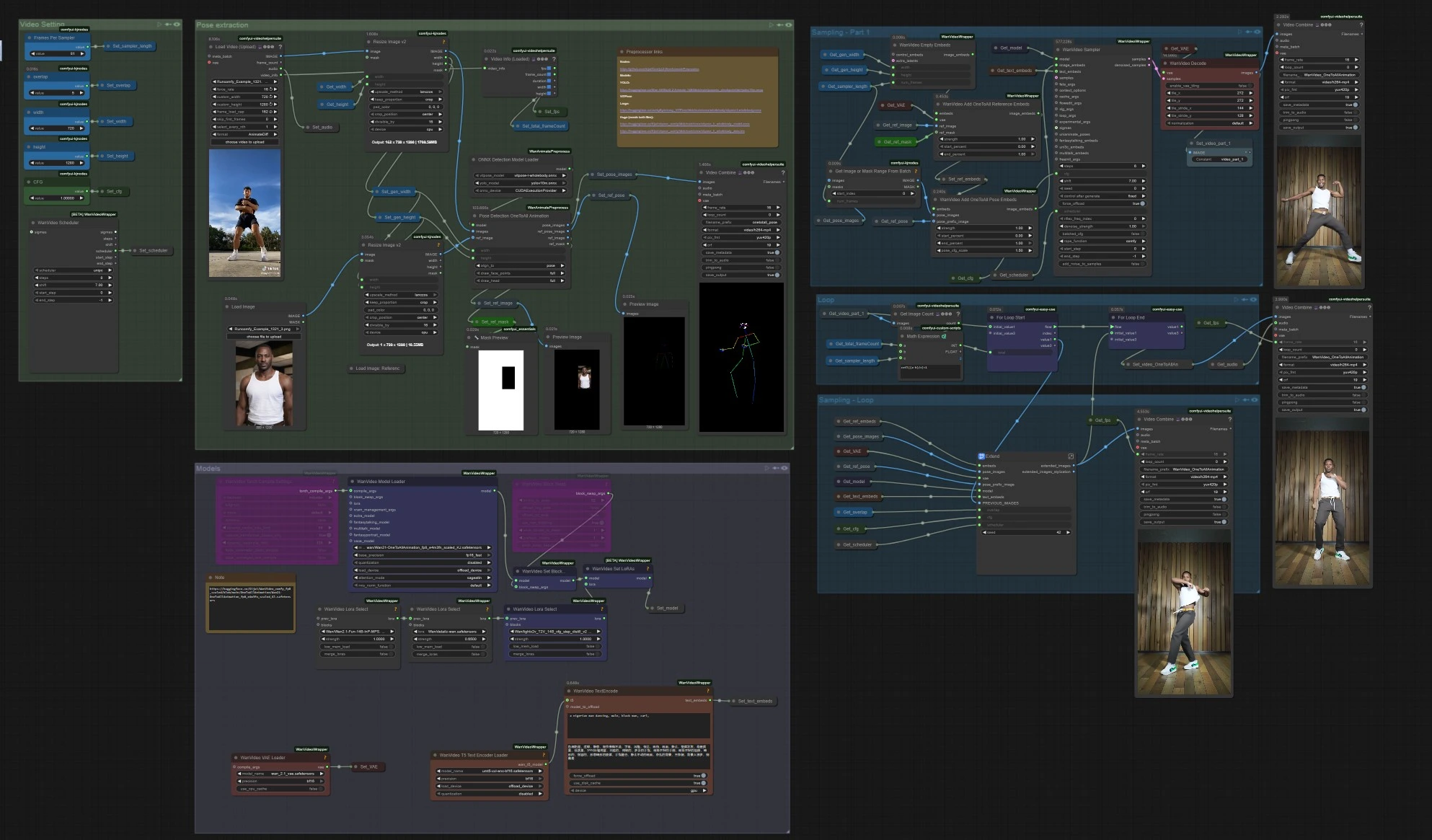
One to All Animation: vídeo de longa duração e alinhado a poses no ComfyUI#
Este fluxo de trabalho One to All Animation transforma um clipe de referência curto em vídeo estendido e de alta fidelidade, mantendo movimento, alinhamento de pose e identidade do personagem consistentes em toda a sequência. Construído em torno da geração de vídeo Wan 2.1 com orientação de pose de corpo inteiro e um extensor de janela deslizante, é ideal para captura de dança, performance e tomadas narrativas onde você deseja que uma única aparência siga um movimento complexo.
Se você é um criador que precisa de saídas estáveis, direcionadas por poses, sem tremores ou desvios de identidade, o One to All Animation oferece um caminho claro: extraia poses do seu vídeo de origem, fusione-as com uma imagem e máscara de referência, gere o primeiro segmento, depois estenda esse segmento repetidamente até que todo o comprimento seja coberto.
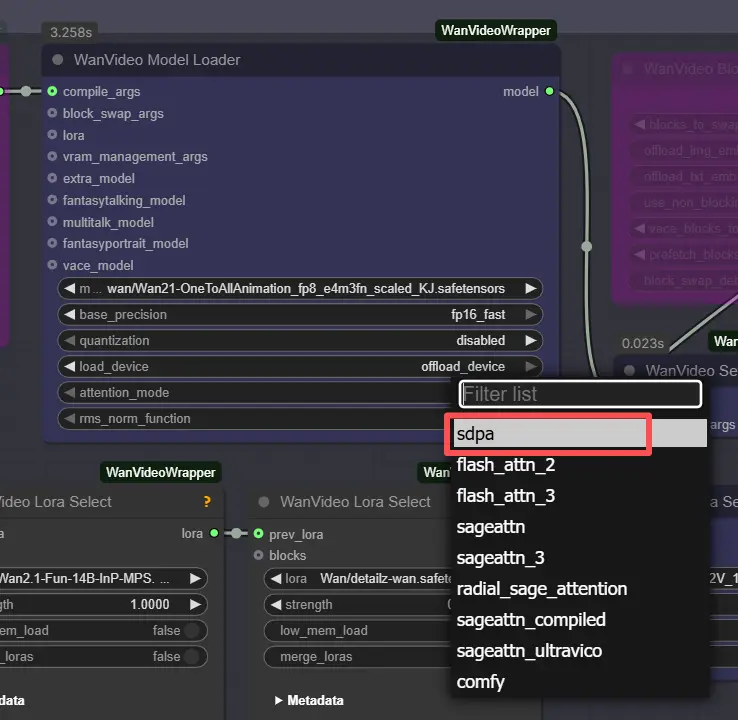
Nota: Em máquinas 2XL ou 3XL, por favor, defina o attention_mode para "sdpa" no nó WanVideo Model Loader. O backend segeattn padrão pode causar problemas de compatibilidade em GPUs de alto desempenho.
Modelos chave no fluxo de trabalho Comfyui One to All Animation#
- Wan 2.1 OneToAllAnimation (geração de vídeo). O principal modelo de difusão usado para alta qualidade de movimento e retenção de identidade. Exemplo de pesos: Wan21-OneToAllAnimation fp8 escalado por Kijai. Model card
- UMT5-XXL text encoder. Codifica prompts para geração de vídeo Wan. Model card
- ViTPose Whole-Body (estimativa de pose). Produz pontos-chave esqueléticos densos que impulsionam a fidelidade de pose. Veja o artigo ViTPose e os pesos ONNX de corpo inteiro. Paper • Weights
- Detector YOLOv10m (detecção de pessoa/região). Acelera a extração de poses robustas ao focar o estimador no sujeito. Paper • Weights
- Alternativa opcional ViTPose-H. Modelo de corpo inteiro de maior capacidade para movimento desafiador. Weights e data file
- Pacotes LoRA opcionais para estilo/controle. Exemplos de LoRAs usados neste gráfico incluem Wan2.1-Fun-InP-MPS, detailz-wan e lightx2v T2V; eles refinam textura, detalhes ou controle in-loco sem re-treinamento.
Como usar o fluxo de trabalho Comfyui One to All Animation#
Fluxo geral
- O fluxo de trabalho lê seu vídeo de movimento de referência, extrai poses de corpo inteiro, prepara embeddings One to All Animation que fundem pose e uma referência de personagem, gera um clipe inicial, depois estende esse clipe repetidamente com sobreposição até que toda a duração seja coberta. Finalmente, ele mescla áudio e exporta um vídeo completo.
Extração de pose
- Carregue sua fonte de movimento em
VHS_LoadVideo(#454). Os quadros são redimensionados comImageResizeKJv2(#131) para corresponder à proporção de geração para amostragem estável. OnnxDetectionModelLoader(#128) carrega YOLOv10m e ViTPose de corpo inteiro;PoseDetectionOneToAllAnimation(#141) então produz um mapa de poses por quadro, uma imagem de pose de referência e uma máscara de referência limpa.- Use
PreviewImage(#145) para inspecionar rapidamente se as poses acompanham o sujeito. Imagens claras e de alto contraste com mínimo borrão de movimento produzem os melhores resultados de One to All Animation.
Modelos
WanVideoModelLoader(#22) carrega pesos Wan 2.1 OneToAllAnimation;WanVideoVAELoader(#38) fornece o VAE emparelhado. Se desejar, empilhe LoRAs de estilo/controle viaWanVideoLoraSelect(#452, #451, #56) e aplique-os comWanVideoSetLoRAs(#80).- Os prompts de texto são codificados por
WanVideoTextEncode(#16). Escreva um prompt positivo conciso e focado na identidade e um negativo forte para manter o personagem no modelo.
Configuração de vídeo
- A largura e a altura são definidas no grupo “Configuração de Vídeo” e propagadas para extração e geração de poses para que tudo permaneça alinhado.
Nota: ⚠️ Limite de Resolução : Este fluxo de trabalho é fixo em 720×1280 (720p). Usar qualquer outra resolução causará erros de incompatibilidade de dimensão a menos que o fluxo de trabalho seja reconfigurado manualmente.
WanVideoScheduler(#231) e o controleCFGselecionam o cronograma de ruído e a força do prompt. CFG mais alto adere mais ao prompt; valores mais baixos acompanham a pose um pouco mais soltos, mas podem reduzir artefatos.VHS_VideoInfoLoaded(#440) lê o fps e a contagem de quadros do clipe de origem, que o loop usa para determinar quantas janelas de One to All Animation são necessárias.
Amostragem – Parte 1
WanVideoEmptyEmbeds(#99) cria um contêiner para condicionamento no tamanho alvo.WanVideoAddOneToAllReferenceEmbeds(#105) injeta sua imagem de referência e suaref_maskpara bloquear a identidade e preservar ou ignorar áreas como fundo ou roupas.WanVideoAddOneToAllPoseEmbeds(#98) anexa aspose_imagesextraídas epose_prefix_imagepara que o primeiro segmento gerado siga o movimento da fonte desde o primeiro quadro.WanVideoSampler(#27) produz o clipe latente inicial, que é decodificado porWanVideoDecode(#28) e opcionalmente visualizado ou salvo comVHS_VideoCombine(#139). Este é o segmento de semente a ser estendido.
Loop
VHS_GetImageCount(#327) eMathExpression|pysssss(#332) calculam quantas passagens de extensão são necessárias com base nos quadros totais e no comprimento por passagem.easy forLoopStart(#329) inicia as passagens de extensão usando o clipe inicial como contexto de partida.
Amostragem – Loop
Extend(#263) é o coração do One to All Animation de longa duração. Ele recomputa o condicionamento comWanVideoAddOneToAllExtendEmbeds(dentro do subgráfico) para manter a continuidade dos latentes anteriores, depois amostra e decodifica a próxima janela.ImageBatchExtendWithOverlap(dentro deExtend) mistura cada nova janela no vídeo acumulado usando uma regiãooverlap, suavizando fronteiras e reduzindo costuras temporais.easy forLoopEnd(#334) anexa cada bloco estendido. O resultado é armazenado viaSet_video_OneToAllAnimation(#386) para exportação.
Exportação
VHS_VideoCombine(#344) grava o vídeo final, usando o fps de origem e áudio opcional deVHS_LoadVideo. Se preferir um resultado silencioso, omita ou silencie a entrada de áudio aqui.
Nós chave no fluxo de trabalho Comfyui One to All Animation#
PoseDetectionOneToAllAnimation (#141)
- Detecta o sujeito e estima pontos-chave de corpo inteiro que impulsionam a orientação de pose. Apoiado por YOLOv10 e ViTPose, é robusto para movimentos rápidos e occlusão parcial. Se o seu sujeito se desviar ou cenas com múltiplas pessoas confundirem o detector, corte sua entrada ou mude para os pesos ViTPose-H de maior capacidade vinculados acima.
WanVideoAddOneToAllReferenceEmbeds (#105)
- Funde uma imagem de referência e
ref_maskno condicionamento para que identidade, roupa ou regiões protegidas permaneçam estáveis ao longo dos quadros. Máscaras apertadas preservam rostos e cabelos; máscaras mais amplas podem bloquear fundos. Ao mudar a aparência, troque a referência e mantenha o mesmo movimento.
WanVideoAddOneToAllPoseEmbeds (#98)
- Vincula mapas de pose e uma pose de prefixo aos embeddings de One to All Animation. Para coreografia mais rígida, aumente a influência da pose; para interpretação mais livre, reduza ligeiramente. Combine com LoRAs quando desejar textura consistente enquanto ainda combina com o movimento.
WanVideoSampler (#27)
- O principal amostrador de vídeo que transforma embeddings e texto no clipe latente inicial.
cfgcontrola a adesão ao prompt, eschedulertroca qualidade, velocidade e estabilidade. Use a mesma família de amostradores aqui e no loop para evitar cintilação.
Extend (#263)
- Um subgráfico compacto que realiza extensão de janela deslizante com sobreposição. A configuração de
overlapé o dial chave: mais sobreposição mistura transições mais suavemente ao custo de computação extra; menos sobreposição é mais rápida, mas pode revelar costuras. Este nó também reutiliza latentes anteriores para manter cena e personagem coerentes entre janelas.
VHS_VideoCombine (#344)
- Multiplexação final e salvamento. Defina o
frame_ratea partir do fps detectado para manter o tempo de movimento fiel à sua fonte. Você pode cortar ou repetir na pós-produção, mas exportar na cadência original preserva a sensação da performance.
Extras opcionais#
- Notas de instalação para pré-processadores. Os nós de extração de pose vêm do complemento da comunidade. Veja o repositório para configuração e colocação de ONNX. ComfyUI-WanAnimatePreprocess
- Prefira ViTPose-H para movimento difícil. Troque para ViTPose-H quando mãos/pés estiverem rápidos ou parcialmente ocultos; baixe tanto o modelo quanto seu arquivo de dados das páginas vinculadas acima.
- Ajuste para execuções longas. Se você atingir limites de VRAM, reduza o comprimento da janela por passagem ou simplifique pilhas de LoRA. A sobreposição pode então ser aumentada um pouco para manter as transições limpas.
- Forte retenção de identidade. Use uma referência de alta qualidade, de frente, e pinte uma
ref_maskprecisa para proteger rosto, cabelo ou roupa. Isso é crítico para sequências longas de One to All Animation. - Imagens limpas ajudam. Alta velocidade do obturador, iluminação consistente e um sujeito claro em primeiro plano melhorarão dramaticamente o rastreamento de poses e reduzirão tremores nas saídas de One to All Animation.
- Utilitários de vídeo. O exportador e os nós auxiliares vêm do Video Helper Suite. Se você deseja controle adicional sobre codecs ou visualizações, verifique a documentação do projeto. Video Helper Suite
Agradecimentos#
Este fluxo de trabalho implementa e constrói sobre os seguintes trabalhos e recursos. Agradecemos sinceramente a Innovate Futures @ Benji pelo tutorial do fluxo de trabalho One to All Animation e ssj9596 pelo projeto One-to-All Animation por suas contribuições e manutenção. Para detalhes autoritativos, por favor, consulte a documentação e os repositórios originais vinculados abaixo.
Recursos#
- Innovate Futures @ Benji/One to All Animation Source
- GitHub: ssj9596/One-to-All-Animation
- Hugging Face: MochunniaN1/One-to-All-1.3b_1
- arXiv: 2511.22940
- Docs / Release Notes: Patreon post
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.



