
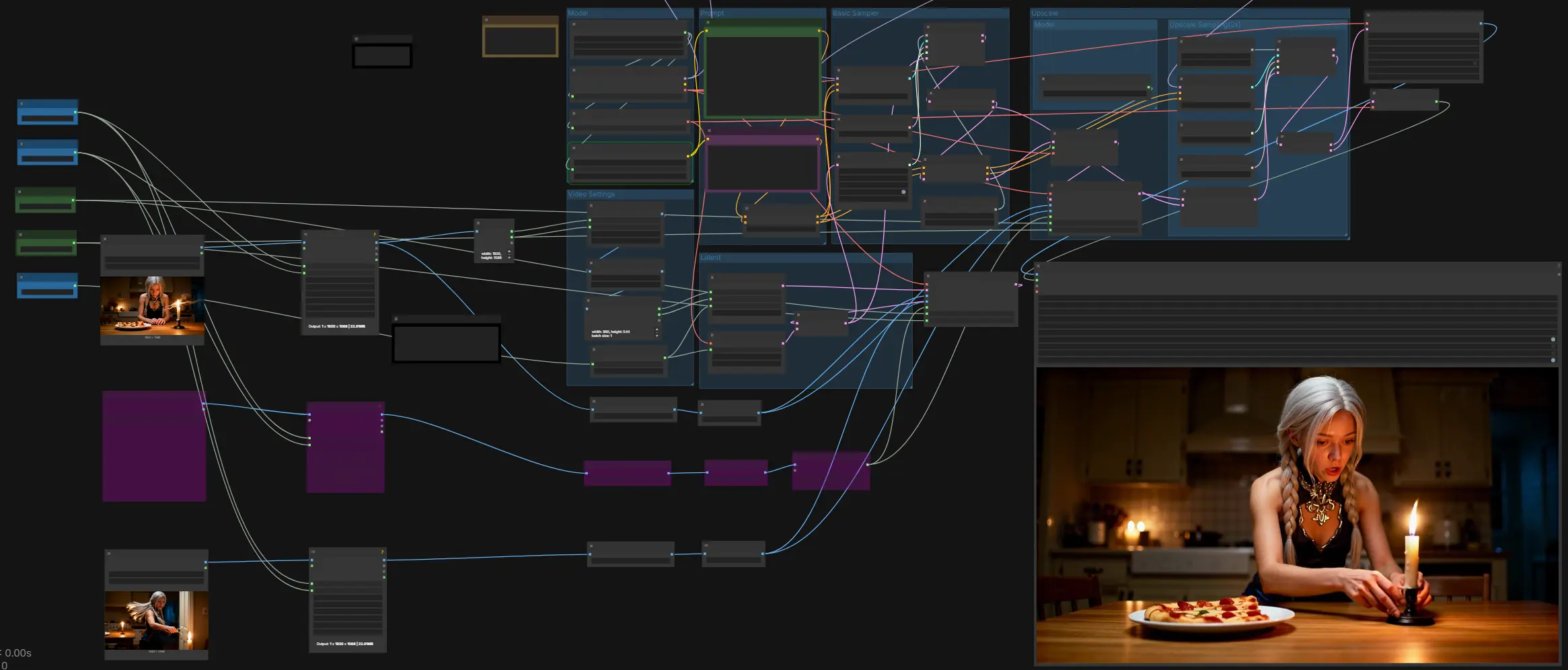
LTX-2 First Last Frame: geração de vídeo controlada de início a fim, sincronizada com áudio em ComfyUI#
LTX-2 First Last Frame é um fluxo de trabalho do ComfyUI para criadores que desejam movimento cinematográfico preciso entre um quadro inicial e um quadro final definidos, enquanto geram áudio e visuais sincronizados em uma única passagem. Ao condicionar em ambas as imagens (e opcionalmente um quadro intermediário guia), o pipeline preserva identidade, enquadramento e iluminação ao longo da tomada, então direciona o movimento para pousar exatamente no último quadro. É projetado para batidas narrativas, transições de título ou cena, movimentos de câmera, e qualquer momento onde a continuidade temporal e o alinhamento de áudio importam.
Impulsionado pelo modelo em tempo real LTX-2, o fluxo de trabalho mantém a iteração rápida enquanto oferece controle fino sobre prompts, comportamento da câmera via LoRAs, e força do primeiro/último quadro. O resultado é uma sequência suave e coerente cujo tempo, aparência e som seguem suas direções do primeiro ao último quadro.
Nota: Para tipos de máquina abaixo de 2x Large, por favor, use o modelo "ltx-2-19b-dev-fp8.safetensors" !
Modelos chave no fluxo de trabalho LTX-2 First Last Frame do Comfyui#
- LTX-2 19B (dev). O modelo central de geração de vídeo que produz latentes de áudio-vídeo conjuntos a partir de texto e controles de quadros; suporta iteração em tempo real e LoRAs conscientes de câmera. Veja o repositório oficial e pesos: Lightricks/LTX-2 on GitHub e Lightricks/LTX-2 on Hugging Face.
- Gemma 3 12B Instruct text encoder for LTX-2. Fornece compreensão de linguagem robusta e ajustada por instrução para prompting visual e de áudio neste pipeline; empacotado para ComfyUI como um codificador de texto compatível com LTX. Referência de pesos: Comfy-Org/ltx-2 split text encoders.
- LTXV Audio VAE (vocoder de 24 kHz). Codifica e decodifica latentes de áudio para que a trilha sonora seja gerada junto com o vídeo e permaneça sincronizada com a ação na tela. Veja o contexto da família de modelos em Lightricks/LTX-2.
- LTX-2 Spatial Upscaler x2. Um upscaler latente para resultados de alta resolução mais limpos após a passagem base, usado durante a etapa de amostragem de upscale. Os pesos estão disponíveis em Lightricks/LTX-2.
- LTX-2 LoRA pack for camera control and detail. LoRAs opcionais como Dolly In/Out/Left/Right, Jib Up/Down, Static, e um Image-Conditioning Detailer moldam o movimento da câmera e detalhes finos. Navegue pela coleção oficial: Lightricks LTX-2 LoRAs.
Como usar o fluxo de trabalho Comfyui LTX-2 First Last Frame#
Este fluxo de trabalho move-se de entradas e prompts para uma amostra de áudio-vídeo base, depois executa uma passagem de upscale guiada 2x antes de decodificar e muxar para MP4 com áudio. Ele depende de controles de primeiro/último quadro em ambas as etapas base e de upscale, com um quadro intermediário opcional para estabilizar a trajetória.
Model#
O grupo Model carrega o checkpoint LTX-2, o codificador de texto Gemma 3 12B Instruct, e o LTXV Audio VAE. Use o painel ckpt_name para selecionar entre variantes padrão e FP8 com base no seu GPU. O codificador de texto é fornecido por LTXAVTextEncoderLoader e alimenta tanto prompts positivos quanto negativos. O áudio VAE permite a geração conjunta de áudio-vídeo para que diálogo, efeitos ou ambiente descritos no prompt surjam com os visuais.
Prompt#
Escreva a cena no prompt positivo e liste características indesejáveis no prompt negativo. Descreva ações ao longo do tempo, especificidades visuais chave, e eventos sonoros na ordem em que devem ocorrer. O bloco LTXVConditioning aplica seu prompt junto com a taxa de quadros escolhida para que o tempo e o movimento sejam interpretados de forma consistente. Trate o áudio como parte do prompt quando precisar de fala, efeitos ou ambiente.
Video Settings#
Defina Width, Height, e total de Video Frames, então escolha Length para o espaçamento de controle primeiro/último, se necessário. O fluxo de trabalho garante que as dimensões correspondam aos requisitos do modelo e escala as entradas de forma apropriada. Se suas imagens de entrada forem maiores, o gráfico lê seu tamanho para inicializar a tela latente e redimensiona os quadros fornecidos para se ajustar. Escolha uma taxa de quadros que corresponda à sua entrega pretendida.
Latent#
Este grupo constrói um vídeo latente vazio e um áudio latente correspondente, então os concatena para que o modelo amostre áudio e vídeo juntos. É onde o guia de primeiro/último quadro é injetado pela primeira vez na passagem base. Fornecer um quadro intermediário é opcional, mas útil para estabilizar identidade ou pose chave no meio da tomada. O resultado é um único latente AV pronto para a amostragem base.
Basic Sampler#
A passagem base usa ruído aleatório, um agendador, e o guia configurado para resolver seu prompt em um latente AV coerente. O guia recebe condicionamento positivo e negativo mais qualquer modelo modificado por LoRA. Após a amostragem, o latente é dividido novamente em vídeo e áudio para que o vídeo possa ser upscalado enquanto o áudio é mantido alinhado. Esta etapa define o movimento global, ritmo, e ritmo de áudio que a passagem de upscale irá refinar.
Upscale#
O upscaler eleva o latente para uma resolução espacial mais alta antes de uma segunda passagem de amostragem. O controle de primeiro/último quadro é reaplicado nesta resolução mais alta para travar os quadros de abertura e fechamento com precisão. Você também pode alimentar um quadro intermediário aqui para manter características estáveis através do upscale. O resultado é um latente AV mais nítido que preserva o movimento planejado.
Model#
Este grupo Model carrega o upscaler latente LTX-2 usado pelo grupo Upscale. Ele prepara o modelo espacial x2 específico e o expõe ao nó upsampler latente. Alterne modelos aqui se você mantiver múltiplos upscalers. Deixe este grupo intocado se você estiver satisfeito com o comportamento padrão x2.
Upscale Sampling(2x)#
A segunda passagem realiza amostragem guiada no latente upscalado usando um sampler separado e cronograma sigma. Um guia consciente de corte alinha o condicionamento à nova resolução para que os detalhes permaneçam consistentes. A saída é dividida novamente em vídeo e áudio para decodificação. Esta passagem melhora principalmente bordas, melhora pequenos textos ou texturas, e mantém a correspondência do primeiro/último quadro.
LTX-2-19b-IC-LoRA-Detailer#
Este grupo aplica um LoRA orientado a detalhes ajustado para o caminho de condicionamento de imagem do LTX-2. Ative-o quando você quiser mais microdetalhes ou texturas mais apertadas após o condicionamento em imagens reais. Mantenha a força moderada para evitar sobrecarregar seu prompt ou restrições de quadro. Se suas entradas já forem nítidas e bem iluminadas, você pode ignorar este LoRA.
Camera-Control-Dolly-In#
Use este LoRA quando a câmera deve se mover em direção ao sujeito ao longo do tempo. Ele inclina o modelo em direção ao movimento para frente enquanto respeita os alvos de primeiro/último. Combine com pistas textuais descrevendo o movimento para o efeito mais forte. Reduza a força se o movimento ultrapassar seu enquadramento pretendido.
Camera-Control-Dolly-Out#
Selecione este quando a tomada deve se afastar do sujeito. Ajuda a criar paralaxe negativa e contexto de ampliação à medida que a sequência progride. Mantenha o último quadro alinhado com sua composição de saída para pousar o movimento de forma limpa. Combine com prompts de áudio atmosférico para revelações cinematográficas.
Camera-Control-Dolly-Left#
Aplica um movimento lateral para a esquerda que é lido como um dolly ou caminhão. Bom para batidas de conversa ou revelações através de um conjunto. Se objetos se mancharem ou derivarem, aumente ligeiramente a força do primeiro/último ou adicione um quadro intermediário. Equilibre com pequenas dicas textuais como "movimento lento para a esquerda" para complementar o LoRA.
Camera-Control-Dolly-Right#
O espelho de Dolly-Left, isso inclina o movimento para o lado direito. Funciona bem para seguir um personagem ou panoramizar para um novo sujeito. Mantenha a força do LoRA modesta se você também solicitar um empurrão para evitar sinais conflitantes. Certifique-se de que a composição do último quadro corresponda ao seu ponto final desejado.
Camera-Control-Jib-Up#
Cria uma elevação vertical, útil para revelações de levantamento ou tomadas de estabelecimento. Combine com prompts superficiais sobre mudança de perspectiva e mudança de horizonte para clareza. Quando o movimento é forte, observe tetos ou exposição do céu; ajuste o prompt negativo para evitar destaques estourados. Se necessário, adicione um quadro intermediário mostrando a enquadramento de meio de subida.
Camera-Control-Jib-Down#
Produz uma descida controlada, frequentemente usada para se estabelecer em um detalhe ou personagem. Pode ser emparelhado com uma cama de áudio mais silenciosa para ênfase. Certifique-se de que o último quadro contenha o objeto ou rosto alvo para que o movimento se resolva de forma decisiva. Ajuste a força do LoRA se a descida parecer muito rápida.
Camera-Control-Static#
Trava a câmera virtual no lugar quando você deseja ação sem movimento de câmera. Isso é útil para diálogos ou tomadas de produto onde apenas o sujeito se move. Combine com controle de primeiro/último quadro para manter a composição perfeitamente estável. Adicione movimento sutil através do prompt de texto em vez de um LoRA de câmera.
Nós chave no fluxo de trabalho LTX-2 First Last Frame do Comfyui#
LTXVFirstLastFrameControl_TTP (#227)#
Injeta restrições de imagem de primeiro e último no latente AV base. Ajuste first_strength para controlar quão estritamente o primeiro quadro é correspondido e last_strength para determinar quão forte a sequência pousa no quadro final. Se o meio do clipe se desviar, forneça um quadro intermediário via LTXVMiddleFrame_TTP e mantenha as forças moderadas para evitar restringir demais o movimento.
LTXVMiddleFrame_TTP (#181)#
Insere opcionalmente um quadro guia em uma posição escolhida entre o início e o fim para estabilizar identidade ou pose. Aumente strength quando o sujeito mudar muito no meio da tomada. Use com moderação; os melhores resultados vêm de uma única referência intermediária bem escolhida, em vez de muitas restrições concorrentes.
LTXVLatentUpsampler (#217)#
Realiza o upscale espacial x2 no espaço latente usando o upscaler espacial LTX-2. Use isso antes da passagem de amostragem 2x para que os detalhes de alta resolução sejam refinados pelo modelo em vez de esticados. Se a memória estiver apertada, mantenha o uso de LoRA mínimo durante esta etapa.
LTXVFirstLastFrameControl_TTP (#223)#
Reaplica a orientação de início/fim (e opcionalmente intermediário) após o upscale x2. Isso garante que os quadros decodificados finais correspondam precisamente às suas referências de primeiro e último na resolução de entrega. Se o upscale introduzir microdeslocamentos, aumente ligeiramente last_strength aqui em vez de na etapa base.
LTXVSpatioTemporalTiledVAEDecode (#230)#
Decodifica o vídeo latente de alta resolução em quadros usando tiling espácio-temporal. Ajuste as configurações de tile e overlap somente quando você vir costuras ou cintilação temporal; maior overlap custa mais VRAM, mas melhora a consistência. Mantenha last_frame_fix para casos extremos onde o quadro final mostra pequeno desvio.
VHS_VideoCombine (#254)#
Muxa quadros decodificados e o áudio gerado em um único MP4. Defina format, pix_fmt, e crf para seu alvo de entrega, e escolha uma frame_rate consistente com o condicionamento. Habilite a gravação de metadados para manter registros de reprodutibilidade com cada renderização.
Extras opcionais#
- Use pesos FP8 do LTX-2 se seu GPU for limitado; mude de volta para precisão total para a maior fidelidade quando o VRAM permitir. Os pesos estão em Lightricks/LTX-2.
- As dimensões funcionam melhor quando largura e altura são da forma 32n + 1; o total de quadros funciona melhor como 8n + 1. O fluxo de trabalho corrige automaticamente para os valores válidos mais próximos, se necessário.
- Descreva dicas de áudio diretamente no seu prompt positivo (diálogo, efeitos, ambiente). O latente conjunto AV do modelo mantém lábios, ações, e sons alinhados.
- Comece com forças de primeiro/último moderadas; aumente a força do último para acertar a pose final, ou adicione um quadro intermediário para estabilizar a identidade.
- Aplique apenas um LoRA de câmera por vez para um intento claro. Navegue pelas opções oficiais na coleção Lightricks LTX-2 LoRA.
Agradecimentos#
Este fluxo de trabalho implementa e constrói sobre os seguintes trabalhos e recursos. Agradecemos @AIKSK pela Referência de Fluxo de Trabalho LTX-2 First Last Frame por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e repositórios vinculados abaixo.
Recursos#
- RunningHub/LTX-2 First Last Frame Workflow Reference
- Docs / Release Notes: LTX-2 First Last Frame Workflow Reference from AIKSK
Nota: O uso dos modelos, conjuntos de dados, e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.