
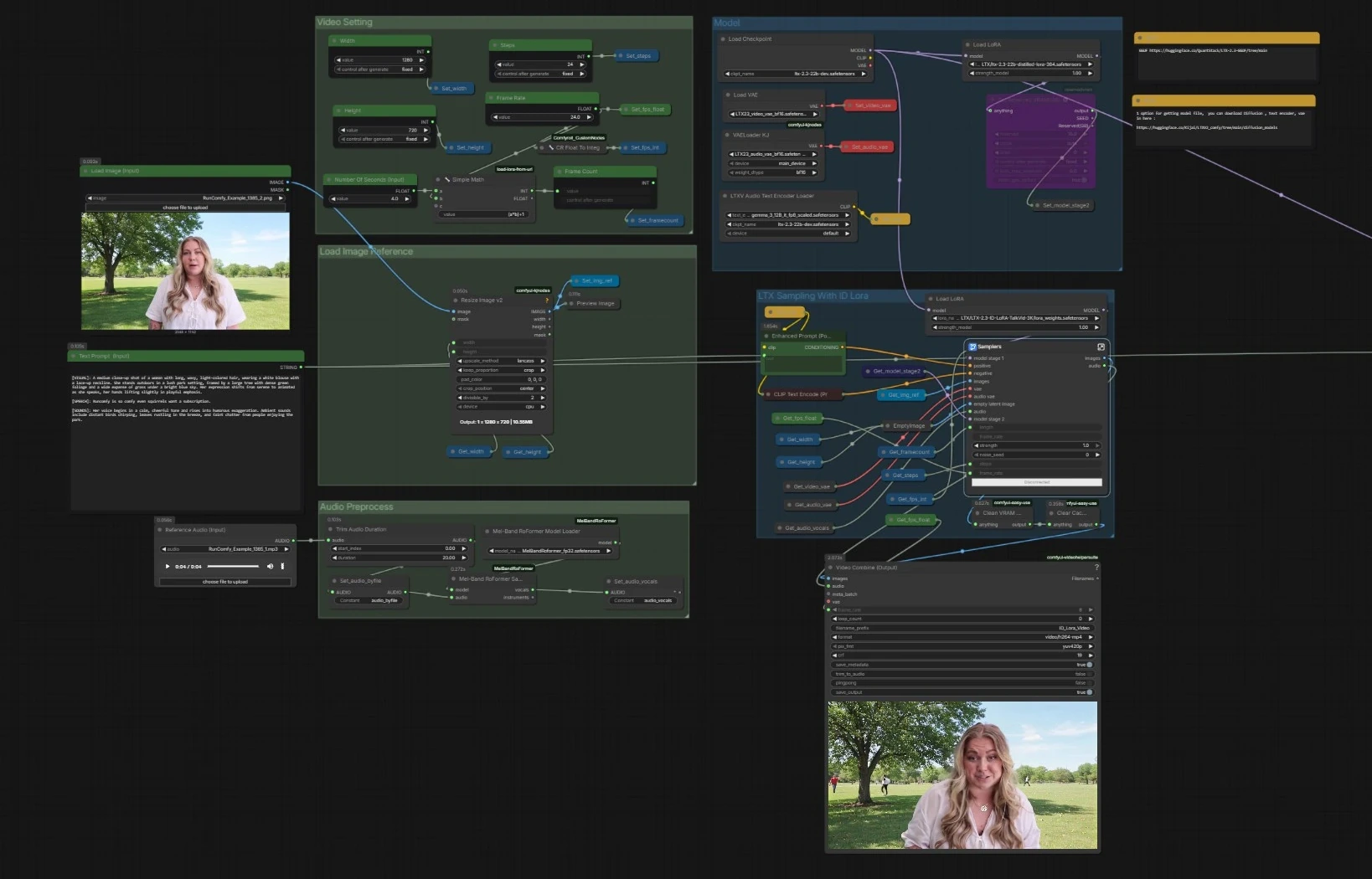
Fluxo de trabalho de vídeo falante LTX 2.3 ID-LoRA para ComfyUI#
Este fluxo de trabalho transforma uma única imagem de rosto, um curto clipe de voz e um prompt em um vídeo falante totalmente sincronizado. Baseado no LTX‑2.3, ele funde áudio e visuais em um único processo de difusão e adiciona um adaptador de identidade In‑Context LoRA para que a pessoa na sua imagem de referência permaneça consistente em todos os quadros. O LTX 2.3 ID-LoRA é ideal para avatares, apresentadores virtuais e qualquer cenário onde sincronização labial, semelhança e controle de prompt devem se alinhar em uma única passagem.
Você fornece três coisas: uma imagem de referência, uma ou duas frases de áudio e um prompt de texto descrevendo a aparência e performance. O caminho LTX 2.3 ID-LoRA lida com a identidade enquanto um pré-processador de áudio leve melhora a clareza da voz para sinais labiais mais fortes. O resultado é um vídeo coerente, que preserva a identidade, com fala sincronizada que não requer treinamento por sujeito.
Modelos principais no fluxo de trabalho Comfyui LTX 2.3 ID-LoRA#
- Lightricks LTX‑2.3 22B base checkpoint. O modelo de base áudio-vídeo conjunto que gera quadros e som sincronizados a partir de condicionamento de texto, imagem e áudio. É o gerador principal usado por este pipeline ComfyUI. Model card
- LTX‑2.3 distilled LoRA 384. Adaptador LoRA oficial que aplica orientação destilada ao modelo base para estabilizar e acelerar a amostragem sem sacrificar a qualidade. É inserido como o modelo de segunda etapa neste fluxo de trabalho. Veja a tabela de checkpoints na página LTX‑2.3. Model card
- LTX‑2.3 spatial upscaler x2. Upscaler em espaço latente usado dentro do subgrafo do sampler para elevar o detalhe espacial antes da decodificação, melhorando a fidelidade do rosto e das bordas no vídeo final. Model card
- Gemma 3 12B Instruct text encoder for LTX‑2.3. Fornece o condicionamento de texto que impulsiona estilo, cena e performance. Este fluxo de trabalho usa o codificador Gemma 3 empacotado para LTX‑2 no ComfyUI. Comfy‑Org text encoders
- LTX‑2.3 VAEs para vídeo e áudio. VAEs construídos para propósito específico decodificam latentes visuais e acústicos produzidos pelo modelo em imagens e uma forma de onda. Builds compatíveis bf16 são referenciadas no grafo. Fontes de exemplo: Video VAE · Audio VAE
- Mel‑Band RoFormer para separação vocal. Pré-processador opcional que extrai vocais limpos do áudio de referência para que o modelo possa rastrear sílabas e formas da boca de maneira mais confiável. Paper · ComfyUI node
- LTX 2.3 ID‑LoRA (IC‑LoRA). Um LoRA de identidade em contexto treinado para uso em vídeos falantes que inclina o gerador em direção ao rosto na sua imagem de referência enquanto respeita os sinais de prompt e voz. Lightricks documenta o uso de LoRA e IC‑LoRA com LTX‑2.3 na página do modelo. Model card
Como usar o fluxo de trabalho Comfyui LTX 2.3 ID-LoRA#
Fluxo geral. O pipeline carrega o LTX‑2.3 base com codificadores de texto e VAEs, prepara sua imagem e áudio, e então executa um sampler LTX de duas etapas que combina texto, a referência de rosto e uma faixa vocal para gerar quadros e fala sincronizados. Um sampler paralelo sem ID‑LoRA é incluído para comparações rápidas. Quadros finais e áudio são muxados em um MP4.
- Modelo
- O grafo carrega o checkpoint base com
CheckpointLoaderSimple(#5493), os codificadores de texto baseados em Gemma viaLTXAVTextEncoderLoader(#5494), e os VAEs dedicados para vídeoVAELoader(#5651) e áudioVAELoaderKJ(#5649). Em seguida, aplica dois adaptadores: o LoRA destilado oficial para formar um modelo de segunda etapa e o LTX 2.3 ID-LoRA para condicionamento de identidade através deLoraLoaderModelOnly(#5573). - Esta etapa garante que o gerador entenda seu prompt, tenha as pilhas de decodificação corretas e esteja preparado com orientação de eficiência e viés de identidade.
- Geralmente, você não modifica nada aqui além de trocar checkpoints ou LoRAs se tiver alternativas.
- O grafo carrega o checkpoint base com
- Configuração de Vídeo
- Controla dimensões de saída, taxa de quadros, passos e comprimento.
Width(#5284),Height(#5286) eFrame Rate(#5289) alimentam uma pequena utilidade que calcula o total de quadros a partir de segundos, mantendo o tempo consistente entre áudio e vídeo. - As configurações são armazenadas uma vez e lidas por todos os nós a jusante para que os dois samplers e o muxer permaneçam alinhados.
- Ajuste esses valores primeiro quando quiser um aspecto, suavidade ou duração diferentes.
- Controla dimensões de saída, taxa de quadros, passos e comprimento.
- Carregar Imagem de Referência
- Forneça uma única imagem de rosto clara através de
Load Image (Input)(#5525). A imagem é redimensionada comImageResizeKJv2(#5280) para corresponder à sua saída escolhida. - Esta imagem pré-processada se torna o âncora para identidade no estágio LTX 2.3 ID-LoRA, guiando semelhança e composição do tiro.
- Use uma foto bem iluminada, frontal e com mínimo de desfoque de movimento para melhores resultados.
- Forneça uma única imagem de rosto clara através de
- Pré-processamento de Áudio
- Insira um curto WAV ou MP3 usando
Reference Audio (Input)(#5652). O clipe é cortado se necessário e então passado paraMelBandRoFormerSampler(#5473) para isolar vocais. - Vocais limpos ajudam o modelo a inferir fonemas e tempo para movimentos labiais precisos e ritmo de fala.
- Se seu áudio já for apenas voz, você pode pular a separação e alimentá-lo diretamente.
- Insira um curto WAV ou MP3 usando
- Amostragem LTX com ID Lora
- Este é o caminho principal. O subgrafo do sampler (
Samplers(#5278)) mistura seu prompt positivo deEnhanced Prompt (Positive)(#5174), a lista negativa, a referência de rosto e a faixa vocal através do pipeline latente AV do LTX‑2.3. LTXVReferenceAudioalinha movimento com fala enquantoLTXVImgToVideoInplaceinjeta a imagem de rosto no latente como um âncora. O adaptador LTX 2.3 ID-LoRA direciona o gerador para a identidade do seu sujeito.- O estágio inclui um upscaler latente interno para elevar o detalhe antes da decodificação. Ele gera quadros mais um fluxo de áudio sincronizado.
- Este é o caminho principal. O subgrafo do sampler (
- Amostragem LTX sem ID Lora
- Um sampler espelhado (
Samplers(#5643)) executa o mesmo condicionamento, mas sem o adaptador ID‑LoRA. Use isso para verificações A/B ou quando quiser mais liberdade longe da identidade de referência. - Todo o resto permanece idêntico, então as diferenças que você notar são devidas apenas ao condicionamento de identidade.
- Este caminho pode ser útil para rascunhos rápidos ou saídas criativas.
- Um sampler espelhado (
- Combinação e Saída de Vídeo
- Quadros e áudio gerados são muxados para MP4 com
Video Combine (Output)(#5218). A taxa de quadros vem da sua configuração global, então movimento e sincronização labial correspondem ao tempo do sampler. - O
Video Combinesecundário (#5645) pré-visualiza o ramo sem ID‑LoRA se você o habilitou, o que é útil para comparações. - O fluxo de trabalho limpa o cache entre execuções para manter o VRAM estável em sessões longas.
- Quadros e áudio gerados são muxados para MP4 com
Nós principais no fluxo de trabalho Comfyui LTX 2.3 ID-LoRA#
LoraLoaderModelOnly(#5573)- Carrega o LTX 2.3 ID-LoRA que preserva a identidade facial. Reduza seu peso se quiser mais variação criativa ou aumente para fixar mais firmemente a semelhança. Combine-o cuidadosamente com a força do prompt para que identidade e estilo não compitam. Referência: uso de LTX‑2.3 LoRA na página do modelo. Model card
LTXVReferenceAudio(#5589)- Converte seu áudio de referência em condicionamento para tempo de sílaba, prosódia e formas da boca. Alimente fala limpa para melhor alinhamento. Se você ouvir bombeamento ou articulação fora do ritmo, encurte ou simplifique o clipe em vez de aumentar a força.
LTXVImgToVideoInplace(#5245, também usado mais tarde)- Injeta a imagem de rosto no fluxo de vídeo latente como um prior espacial. O controle de força da imagem equilibra a adesão à foto versus liberdade de movimento. Para forte identidade com movimento natural, mantenha a força da imagem moderada e deixe o ID‑LoRA carregar a semelhança.
LTXVConditioning(#5621)- Empacota condicionamento de texto e sinais de tempo para os samplers LTX. Certifique-se de que sua entrada de taxa de quadros corresponda à sua taxa de quadros de saída para que campos de movimento e tempo de fonema permaneçam coerentes.
VHS_VideoCombine(#5218)- Muxa quadros e áudio para o arquivo final. Se seu áudio for ligeiramente mais longo que os quadros, habilite a poda aqui para evitar uma cauda preta final. Para compatibilidade com plataformas, mantenha as configurações padrão H.264, a menos que você tenha um motivo para mudá-las. Referência de nó: ComfyUI‑VideoHelperSuite
MelBandRoFormerSampler(#5473)- Separa vocais da música usando um transformador de banda Mel para que o gerador se trave na fala. Se sibilantes borram ou plosivas estouram, tente um arquivo de modelo diferente da mesma família ou reduza a intensidade do input. Leitura de fundo: arXiv
Extras opcionais#
- Para gerações mais estáveis com LTX‑2.3, use largura e altura divisíveis por 32 e escolha uma contagem de quadros de 8n + 1 conforme documentado por Lightricks. Model card
- Mantenha a imagem de referência consistente com seu prompt. Se você descrever iluminação externa, mas fornecer uma foto interna, a identidade pode se manter enquanto a cor e a sombra lutam contra o prompt.
- Dê ao áudio 2 a 8 segundos com ritmo natural. Clipes supercomprimidos ou reverberantes reduzem a fidelidade da sincronização labial mesmo após a separação vocal.
- Quando os rostos se deslocam, reduza ligeiramente a força da imagem e confie mais no LTX 2.3 ID-LoRA. Quando os rostos vagam muito, faça o oposto.
- Para tomadas mais longas, gere em segmentos que compartilham a mesma semente e configurações globais, depois junte clipes na edição de vídeo, se necessário.
Referências e repositórios úteis#
- Pesos abertos e notas do LTX‑2.3: Página do modelo Hugging Face
- Nós oficiais do ComfyUI para LTX Video: Lightricks/ComfyUI‑LTXVideo
- Base de código e artigo do LTX‑2: Lightricks/LTX‑Video · arXiv
- Codificadores IT Gemma 3 12B para LTX no ComfyUI: Comfy‑Org/ltx‑2 text_encoders
- Fundo do Mel‑Band RoFormer: arXiv
Agradecimentos#
Este fluxo de trabalho implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos aos criadores do LTX 2.3 ID-LoRA Source para o fluxo de trabalho LTX 2.3 ID-LoRA Source por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- LTX 2.3 ID-LoRA Source
- Docs / Notas de Lançamento: YouTube @Benji’s AI Playground
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.