
LTX-2.3 ICLoRA LipDub para ComfyUI#
LTX-2.3 ICLoRA LipDub é um fluxo de trabalho ComfyUI de duas passagens, controlado por vídeo e áudio, que dubla uma pessoa falando enquanto mantém a identidade e o movimento consistentes. Combina o condicionamento de texto e vídeo do Lightricks LTX-2.3 com o LipDub IC-LoRA para alinhar o movimento labial precisamente à fala fornecida, refinando o resultado em alta resolução para detalhes nítidos. O gráfico é preparado para RunComfy com nomes de entrada/saída padronizados para que você possa trocar mídia e repetir execuções de forma confiável.
Este fluxo de trabalho ComfyUI LTX-2.3 ICLoRA LipDub é ideal para criadores que precisam de dublagem multilíngue, reformulação ou correções semelhantes a ADR enquanto preservam a performance original. Forneça um vídeo de origem que já inclua a fala-alvo, descreva a cena e o que a pessoa deve dizer, e o fluxo de trabalho sintetizará visuais e áudio sincronizados em um clipe finalizado.
Modelos chave no fluxo de trabalho Comfyui LTX-2.3 ICLoRA LipDub#
- Modelo de vídeo base LTX-2.3 22B. O modelo de difusão fundamental que gera o vídeo e governa como os prompts orientam a aparência, o movimento e o estilo.
- LTX-2.3 IC-LoRA LipDub. Um LoRA especializado para dublagem labial que condiciona o modelo a seguir a fala fornecida e alinhar as formas da boca aos fonemas enquanto preserva a identidade e o movimento da cabeça. Model card
- LTX-2.3 Audio VAE. Codifica a fala de entrada em um latente de áudio que pode ser injetado no condicionamento de texto e depois decodificado de volta para a forma de onda, garantindo que o tempo fique travado nos quadros.
- LTX-2.3 Spatial Upscaler x2. Aumenta a resolução espacial dos vídeos latentes antes da passagem de refinamento em alta resolução, melhorando a textura sem alterar o movimento.
- LTX-2.3 Distilled LoRA (384). Um LoRA de fortalecimento usado junto com o ponto de verificação base para melhorar o detalhe e a estabilidade temporal sem overfitting ao quadro de referência.
Como usar o fluxo de trabalho Comfyui LTX-2.3 ICLoRA LipDub#
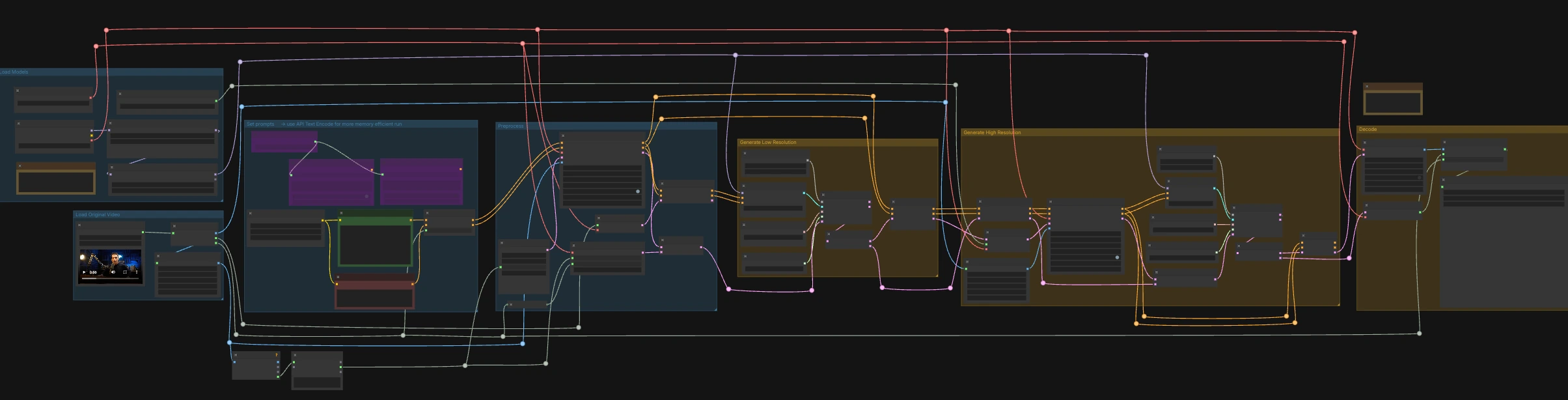
Este fluxo de trabalho é executado em duas etapas coordenadas: uma passagem de baixa resolução para travar o tempo e as formas labiais ao áudio, seguida por uma passagem de alta resolução que aumenta e refina os detalhes enquanto preserva a sincronização. Comece carregando um vídeo de origem que já contenha a fala desejada, depois escreva a linha de texto que você quer que a pessoa diga.
Carregar Vídeo Original#
O nó LoadVideo (#5002) importa seu clipe de origem com áudio embutido. GetVideoComponents (#5010) extrai quadros, áudio e taxa de quadros; a taxa de quadros é compartilhada por todo o gráfico para que vídeo e áudio permaneçam alinhados. Dois redimensionadores, Resize Image/Mask (s1 size) (#5009) e Resize Image/Mask (s2 size) (#5003), preparam fluxos de imagem de trabalho para as passagens de baixa e alta resolução. A contagem de quadros é medida e arredondada para comprimentos amigáveis ao amostrador para que a decodificação permaneça estável.
Carregar Modelos#
CheckpointLoaderSimple (#5017) carrega o modelo base LTX-2.3 22B e VAE usados em todo o gráfico. Dois carregadores, LoraLoaderModelOnly (#5018) e LTXICLoRALoaderModelOnly (#5012), adicionam o LoRA destilado e o IC-LoRA LipDub no topo da base para que o gerador siga a fala enquanto preserva a identidade. LTXVAudioVAELoader (#4010) fornece o VAE de áudio para codificação/decodificação da trilha sonora. A saída latent_downscale_factor do carregador IC-LoRA é intencionalmente não utilizada aqui porque o treinamento do LipDub assume quadros de referência em resolução total, correspondendo à nota incluída.
Definir Prompts#
Escreva sua descrição de cena e linha falada exata em CLIP Text Encode (Positive Prompt) (#2483). Use CLIP Text Encode (Negative Prompt) (#2612) para minimizar características ou artefatos indesejados. Estes alimentam LTXVConditioning (#1241), que adapta o condicionamento ao domínio do vídeo e leva o contexto da taxa de quadros adiante. Para execuções de baixo VRAM, o gráfico também inclui codificadores baseados em API (🅛🅣🅧 Gemma API Text Encode - POSITIVE (#4980) e ... - NEGATIVE (#4981)) controlados pela string LTX API KEY (#4979); a fiação padrão usa codificadores locais.
Pré-processar#
LTXVAudioVAEEncode (#5005) converte a fala de origem em um latente de áudio, e LTXVSetAudioRefTokens (#5006) injeta esse latente no condicionamento de texto para que o gerador "ouça" o tempo e os fonemas. EmptyLTXVLatentVideo (#3059) prepara um vídeo latente de espaço reservado com o tamanho espacial correto e uma contagem de quadros alinhada à entrada. LTXAddVideoICLoRAGuide (#5004) anexa a orientação de referência IC-LoRA usando os quadros s1, estabelecendo identidade e atenção à região da boca antes da amostragem.
Gerar Baixa Resolução#
Um loop de difusão padrão é formado por CFGGuider (#4828), KSamplerSelect (#4831), ManualSigmas (#4984), e SamplerCustomAdvanced (#4829). O sampler opera em um latente de áudio+vídeo composto por LTXVConcatAVLatent (#4528), garantindo que o condicionamento de áudio participe de cada etapa. Após a amostragem, LTXVSeparateAVLatent (#4845) divide o latente para que LTXVSetAudioRefTokens (#5013) possa congelar a mesma representação de fala para a passagem de alta resolução. Esta etapa trava as formas labiais na fala e define a linha de base do movimento no tamanho s1.
Gerar Alta Resolução#
LTXVLatentUpsampler (#4975) eleva o vídeo latente usando o Spatial Upscaler x2, preservando o movimento enquanto adiciona capacidade para detalhes espaciais. LTXAddVideoICLoRAGuide (#5014) reaplica o IC-LoRA no tamanho s2 usando os quadros de alta resolução para que identidade, região da boca, e características finas sejam reforçadas. Um segundo loop de difusão (CFGGuider (#4964), KSamplerSelect (#4976), ManualSigmas (#4985), SamplerCustomAdvanced (#4971)) refina o latente ampliado enquanto LTXVConcatAVLatent (#4969) mantém o latente de fala congelado em sincronia. LTXVCropGuides (#5011, #5015) gerencia cortes seguros e guias de região para que o rosto permaneça devidamente enquadrado em ambas as passagens.
Decodificar#
LTXVTiledVAEDecode (#4995) converte o vídeo latente final em imagens usando blocos para eficiência de VRAM, e LTXVAudioVAEDecode (#4848) retorna o áudio sincronizado. CreateVideo (#4849) monta os quadros e o áudio na taxa de quadros original, e SaveVideo (#4852) grava o arquivo com o nome pré-preenchido RunComfy; altere este valor para personalizar suas saídas. O resultado é um clipe LTX-2.3 ICLoRA LipDub totalmente sincronizado pronto para revisão ou entrega.
Nós chave no fluxo de trabalho Comfyui LTX-2.3 ICLoRA LipDub#
LTXICLoRALoaderModelOnly (#5012)#
Carrega o LipDub IC-LoRA e o anexa ao modelo base para que o movimento labial siga a fala de entrada sem substituir a identidade. Se você precisar de controle labial mais forte ou mais sutil, ajuste o peso do LoRA aqui; mantenha-o coordenado com qualquer LoRA adicional que você aplique na pilha para evitar supercondicionamento.
LTXAddVideoICLoRAGuide (#5004)#
Aplica a orientação IC-LoRA na etapa de baixa resolução usando os quadros de referência reduzidos. É aqui que o fluxo de trabalho primeiro trava a identidade e a atenção à região da boca; use-o para testes A/B alternando o guia para ver o efeito da orientação de referência no tempo e articulação.
LTXAddVideoICLoRAGuide (#5014)#
Reaplica a orientação IC-LoRA em alta resolução com os quadros s2 para que a passagem refinada preserve a mesma identidade do falante e formas labiais precisas. Se você alterar o tamanho do quadro de alta resolução, revise este nó para manter o guia de referência consistente com sua saída alvo.
LTXVSetAudioRefTokens (#5006)#
Vincula a fala codificada ao seu condicionamento de texto para que o sampler alinhe visiomas com fonemas. Use o mesmo latente de áudio em todas as passagens para resultados estáveis; este gráfico lida com isso automaticamente, mas se você trocar o áudio no meio da execução, deve atualizar tanto o condicionamento quanto o latente concatenado.
LTXVLatentUpsampler (#4975)#
Amplia o vídeo latente com o LTX-2.3 Spatial Upscaler x2 para abrir espaço para detalhes finos antes do sampler de alta resolução. Se o VRAM estiver apertado, combine isso com dimensões s2 menores ou tiling mais leve no decodificador para equilibrar qualidade e rendimento.
LTXVTiledVAEDecode (#4995)#
Decodifica o latente final em quadros usando tiling para ajustar grandes saídas em GPUs limitadas. Ajuste a contagem de blocos e a sobreposição aqui para trocar velocidade por pegada de memória; menos blocos são mais rápidos, mas requerem mais VRAM, enquanto mais blocos reduzem o VRAM ao custo de tempo.
Extras Opcionais#
- Prompting para dublagem: inclua as palavras exatas que você quer que sejam faladas; o modelo não traduz automaticamente. Use o script nativo do idioma alvo, mantenha-se a um único falante e procure um comprimento semelhante ao da linha original para que o ritmo permaneça natural.
- Dicas de desempenho: se você atingir limites de VRAM, reduza o redimensionamento s2 em
Resize Image/Mask (s2 size)(#5003) e aumente o tiling emLTXVTiledVAEDecode(#4995). Para repetibilidade, mantenha as sementesRandomNoisefixas em ambas as passagens. - Padrões de fluxo de trabalho: o nome do arquivo de entrada de exemplo é pré-preenchido em
LoadVideo(#5002), e o salvador define um nome de saída consistente. Substitua ambos para rodar múltiplas execuções LTX-2.3 ICLoRA LipDub sem sobrescrever resultados. - Enquadramento: se o rosto se mover para perto das bordas, ajuste
LTXVCropGuides(#5011, #5015) para que a região da boca permaneça em um corte estável em ambas as passagens.
Agradecimentos#
Este fluxo de trabalho implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos a Lightricks pelo modelo LTX-2.3-22b-IC-LoRA-LipDub e à RunComfy pelo fluxo de trabalho compartilhado ComfyUI (fonte Cloud Save) por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3-22b-IC-LoRA-LipDub
- arXiv: arXiv:2601.22143
- RunComfy/Cloud Save source
- Docs / Release Notes: RunComfy shared workflow
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.
