
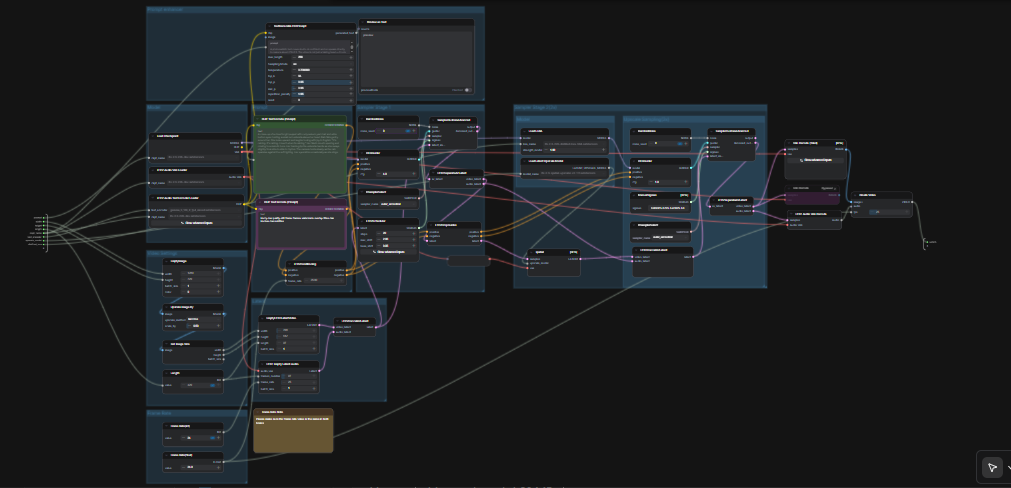
LTX 2.3 ComfyUI: Texto-para-Vídeo com áudio limpo, amostragem em duas etapas e aumento espacial de 2×#
Este fluxo de trabalho LTX 2.3 ComfyUI transforma sugestões curtas em vídeos cinematográficos polidos com áudio sincronizado. Ele é construído em torno do modelo LTX-2.3 da Lightricks e configurado para alta coerência visual, movimento estável e saída amigável para transmissão. Criadores, editores e artistas técnicos podem ir de uma única sugestão para um MP4 com áudio em uma única passagem, usando um gráfico simplificado que inclui um aprimorador de sugestão, duas etapas de amostragem e um aumentador latente de 2×.
Comparado a configurações típicas de texto-para-vídeo, este gráfico enfatiza a consistência de cena e a fidelidade da sugestão. O caminho padrão gera um AV latente, amplia-o no espaço latente para detalhes mais nítidos, depois decodifica para quadros e áudio antes de empacotar tudo em um arquivo de vídeo pronto para compartilhar. Se você está explorando modelos de vídeo de código aberto modernos, este fluxo de trabalho LTX 2.3 ComfyUI é uma maneira rápida de obter movimento de qualidade de produção.
Modelos principais no fluxo de trabalho Comfyui LTX 2.3 ComfyUI#
- LTX-2.3 22B (dev) checkpoint da Lightricks. O modelo central texto-para-vídeo que produz movimento de alta coerência e forte consistência de cena. Hugging Face • GitHub
- Gemma 3 12B Instruct text encoder (FP4 mixed). Fornece compreensão robusta de linguagem para melhor fundamentação da sugestão e detalhes de cena mais ricos. Hugging Face
- LTX-2.3 Spatial Upscaler x2 1.0. Um aumentador de espaço latente que aprimora os detalhes espaciais sem quebrar a consistência do movimento. Hugging Face
- LTX-2.3 22B Distilled LoRA (384). Um adaptador destilado que refina a fidelidade de textura e estabiliza o estilo durante a etapa de aumento/refinamento. Hugging Face
- LTX Audio VAE. O módulo de áudio emparelhado com LTX-2.3 que permite a geração de som limpo e sincronizado a partir da mesma sugestão. Hugging Face
Como usar o fluxo de trabalho Comfyui LTX 2.3 ComfyUI#
O gráfico funciona em duas passagens coordenadas. Primeiro, ele gera um AV latente em uma resolução de trabalho com sua sugestão. Em seguida, realiza um aumento latente de 2× e uma segunda passagem de amostragem com um LoRA destilado antes de decodificar para quadros e áudio, finalmente muxando para MP4.
Aprimorador de Sugestão#
O nó TextGenerateLTX2Prompt (#149) reescreve a linguagem simples em uma sugestão amigável ao modelo que cobre ações, visuais e dicas de áudio. Alimente-o com sua descrição de cena; imagens de referência opcionais podem ser conectadas quando você deseja orientação para enquadramento ou estilo. O texto gerado é roteado para um codificador positivo enquanto uma sugestão negativa focada na qualidade mantém os artefatos baixos. Esse equilíbrio ajuda o modelo LTX-2.3 a permanecer no escopo sem restringir excessivamente a criatividade.
Modelo#
O CheckpointLoaderSimple (#146) carrega o checkpoint LTX-2.3 22B e expõe tanto o modelo quanto seu VAE. LTXAVTextEncoderLoader (#147) traz o codificador de texto Gemma 3 12B Instruct que o fluxo de trabalho usa para condicionamento positivo e negativo. Mantenha essas seleções a menos que esteja testando outras variantes LTX, pois o restante do gráfico é ajustado para esse emparelhamento.
Configurações de Vídeo#
A resolução e a duração são definidas com uma estrutura de imagem leve e o controle Length. O gráfico lê o tamanho da imagem, escala para uma resolução de trabalho e encaminha esses valores para o criador de vídeo latente. Os modelos LTX têm restrições de passo; mantenha tamanhos que sigam um padrão de passo de 32 e comprimentos que se alinhem com a cadência de quadros do modelo. O gráfico ajustará suavemente valores ilegais para os mais próximos válidos, mas escolher tamanhos válidos desde o início produz a melhor composição.
Taxa de Quadros#
Dois pequenos controles definem FPS para condicionamento e codificação final: Frame Rate(int) (#141) e Frame Rate(float) (#140). Mantenha-os idênticos para que o tempo de movimento e o alinhamento de áudio permaneçam consistentes em todo o pipeline. Escolha uma taxa cinematográfica se desejar movimento mais suave ou corresponda aos padrões da plataforma ao direcionar formatos sociais.
Latente#
EmptyLTXVLatentVideo (#121) inicializa o vídeo latente e LTXVEmptyLatentAudio (#119) faz o mesmo para o áudio. LTXVConcatAVLatent (#122) os mescla em um único AV latente para que a orientação do texto possa direcionar ambas as modalidades juntas. LTXVConditioning (#120) anexa condicionamento positivo e negativo, e LTXVCropGuides (#115) adapta a orientação ao layout espacial do latente para um enquadramento mais confiável.
Estágio de Amostragem 1#
Este estágio cria o AV latente inicial usando RandomNoise (#151), KSamplerSelect (#144), e o LTXVScheduler (#112) com um CFGGuider (#139) consciente do LTX. O agendador é adaptado para LTX para equilibrar a estabilidade temporal com a adesão à sugestão. Se você deseja mais variação, altere a semente de ruído; para uma adesão mais firme ao roteiro, favoreça amostradores que mantenham a coerência temporal.
Modelo (LoRA)#
LoraLoaderModelOnly (#143) aplica o LoRA destilado LTX-2.3 antes do refinamento. Este adaptador melhora sutilmente o polimento de textura e a fidelidade de estilo sem perder a consistência do movimento. É mais perceptível na pele, tecido e reflexos especulares.
Amostragem de Aumento (2×)#
LTXVLatentUpsampler (#130) realiza um aumento espacial de 2× no espaço latente usando o LatentUpscaleModelLoader (#114) carregado e o VAE base. Como o aumento acontece antes da decodificação, você retém a suavidade temporal enquanto ganha detalhes espaciais finos. Os latentes de vídeo e áudio ampliados são então reunidos com LTXVConcatAVLatent (#129) para a passagem de refinamento.
Estágio de Amostragem 2 (2×)#
A segunda passagem refina o latente ampliado usando RandomNoise (#127), KSamplerSelect (#145), e um agendamento ManualSigmas (#113) sob um CFGGuider (#116). Este estágio é onde microdetalhes e nitidez de bordas são finalizados. Funciona melhor quando o LoRA está ativo e a sugestão é específica sobre texturas e iluminação.
Decodificação e Saída#
LTXVSeparateAVLatent (#135) divide o latente refinado para que VAEDecodeTiled (#137) possa reconstruir quadros enquanto LTXVAudioVAEDecode (#138) restaura o áudio. CreateVideo (#133) mescla quadros e áudio no FPS escolhido, e o nó SaveVideo de nível superior grava um MP4 na pasta de vídeos do fluxo de trabalho. O resultado é um arquivo limpo, pronto para compartilhar, produzido inteiramente dentro do pipeline LTX 2.3 ComfyUI.
Nós principais no fluxo de trabalho Comfyui LTX 2.3 ComfyUI#
TextGenerateLTX2Prompt(#149): Converte descrições simples em sugestões estruturadas que cobrem movimento, atributos visuais e áudio. Ajuste sua redação aqui primeiro ao direcionar batidas de história ou ritmo; geralmente produz ganhos maiores do que ajustes de amostrador.LTXVScheduler(#112): Um agendador específico do LTX que molda como o ruído é removido ao longo do tempo. Combine-o cuidadosamente com o amostrador escolhido para equilibrar estabilidade temporal e fidelidade da sugestão.LTXVLatentUpsampler(#130): Realiza um aumento espacial de 2× diretamente no espaço latente, preservando a continuidade do movimento enquanto adiciona detalhes nítidos. Use-o quando quiser resultados mais nítidos sem recorrer a aumentadores pós-decodificação.LoraLoaderModelOnly(#143): Aplica o LoRA destilado LTX-2.3 para refinamento. Aumente a influência para um controle de estilo mais apertado; reduza se desejar a aparência mais ampla do modelo base.CreateVideo(#133): Mescla quadros decodificados com áudio gerado no FPS selecionado para que o tempo e a sincronização labial permaneçam intactos. Se você mudar o FPS, mantenha ambos os controles de taxa de quadros correspondentes.
Extras opcionais#
- Dicas de sugestão: Descreva ações ao longo do tempo, liste elementos visuais chave e especifique sons ou diálogos esperados. Frases claras e concisas dão ao codificador LTX-2.3 o melhor sinal.
- Dimensões e comprimento: Prefira tamanhos em um passo de 32 e comprimentos que respeitem a cadência de quadros do modelo. Embora o gráfico ajuste automaticamente valores próximos, entradas válidas melhoram a composição e reduzem tremores sutis.
- Iteração rápida: Altere a semente
RandomNoiseentre as execuções para explorar variantes enquanto mantém a mesma sugestão e configurações. - Troca de modelo: Os padrões são ajustados para LTX-2.3 22B com Gemma 3 12B IT e o aumentador espacial de 2×. Troque os modelos somente se entender como cada um afeta o condicionamento e a decodificação.
Agradecimentos#
Este fluxo de trabalho implementa e constrói sobre os seguintes trabalhos e recursos. Agradecemos à Lightricks pelo modelo LTX-2.3 e à EyeForAILabs pelo tutorial no YouTube por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios listados abaixo.
Recursos#
- Lightricks/LTX-2.3
- GitHub: Lightricks/LTX-2
- Hugging Face: Lightricks/LTX-2.3
- arXiv: 2601.03233
- EyeForAILabs/YouTube Tutorial
- Docs / Release Notes: YouTube Channel from @eyeforailabs
Nota: O uso dos modelos, conjuntos de dados e códigos referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.