
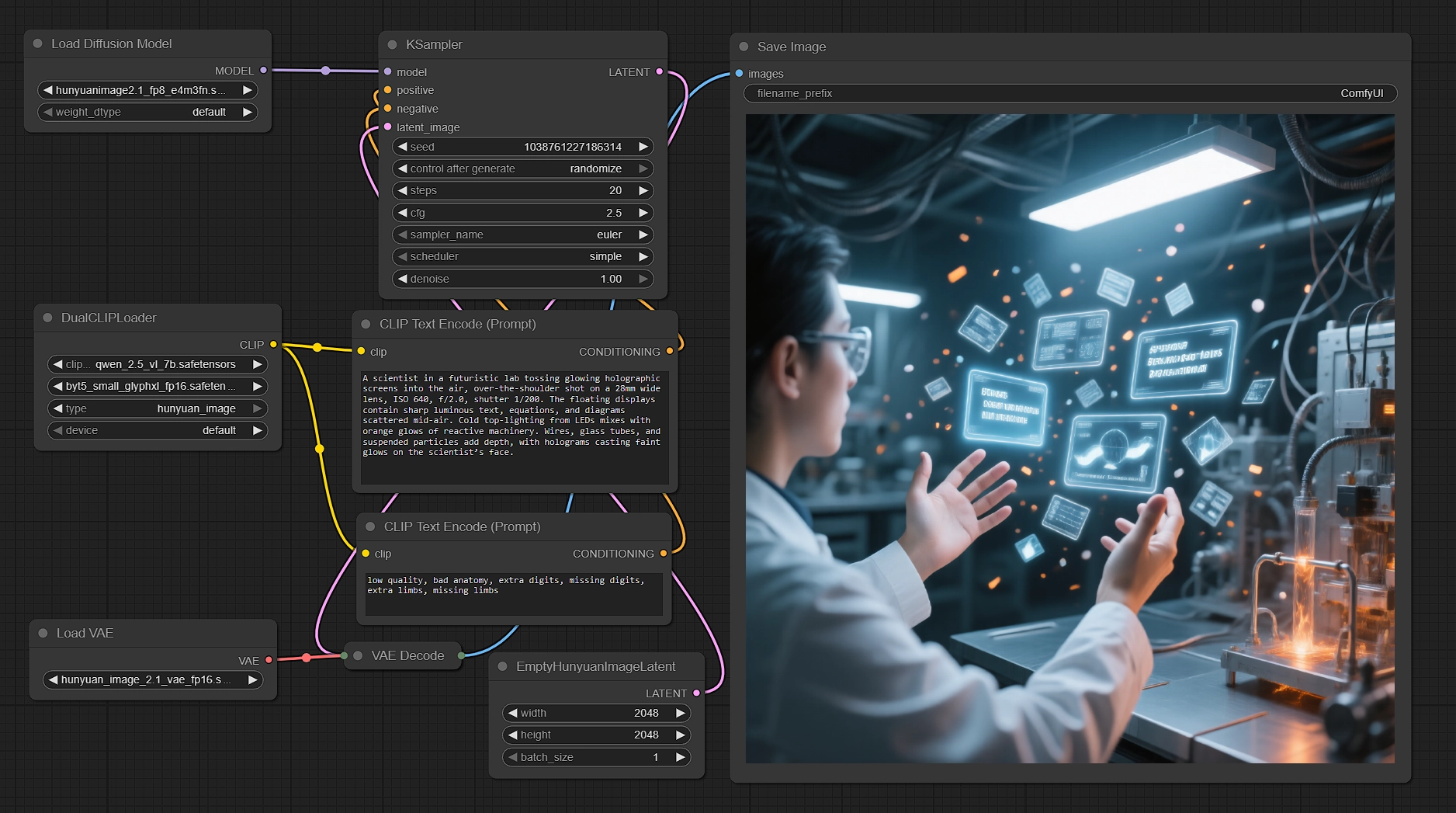










Gere imagens nativas 2K com Hunyuan Image 2.1 em ComfyUI#
Este fluxo de trabalho transforma seus prompts em renderizações nativas 2048×2048 nítidas usando Hunyuan Image 2.1. Ele combina o transformador de difusão da Tencent com codificadores de texto duplos para elevar o alinhamento semântico e a qualidade de renderização de texto, então amostra eficientemente e decodifica através do VAE de alta compressão correspondente. Se você precisa de cenas, personagens e texto claro em imagem prontos para produção em 2K enquanto mantém velocidade e controle, este fluxo de trabalho ComfyUI Hunyuan Image 2.1 foi feito para você.
Criadores, diretores de arte e artistas técnicos podem inserir prompts multilíngues, ajustar alguns controles e obter consistentemente resultados nítidos. O gráfico é fornecido com um prompt negativo sensato, uma tela nativa 2K e um FP8 UNet para manter o VRAM sob controle, demonstrando o que Hunyuan Image 2.1 pode entregar prontamente.
Modelos principais no fluxo de trabalho Comfyui Hunyuan Image 2.1#
- HunyuanImage‑2.1 da Tencent. Modelo base de texto para imagem com um backbone de transformador de difusão, codificadores de texto duplos, um VAE 32×, pós-treinamento RLHF e destilação meanflow para amostragem eficiente. Links: Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct. Codificador multimodal de visão e linguagem usado aqui como codificador de texto semântico para melhorar a compreensão de prompts em cenas complexas e idiomas. Link: Hugging Face
- ByT5 Small. Codificador em nível de byte sem tokenização que fortalece o manuseio de caracteres e glifos para renderização de texto dentro de imagens. Links: Hugging Face · Paper
Como usar o fluxo de trabalho Comfyui Hunyuan Image 2.1#
O gráfico segue um caminho claro do prompt aos pixels: codificar texto com dois codificadores, preparar uma tela latente nativa 2K, amostrar com Hunyuan Image 2.1, decodificar através do VAE correspondente e salvar a saída.
Codificação de texto com codificadores duplos#
- O
DualCLIPLoader(#33) carrega Qwen2.5‑VL‑7B e ByT5 Small configurados para Hunyuan Image 2.1. Este conjunto duplo permite que o modelo interprete a semântica da cena enquanto permanece robusto a glifos e texto multilíngue. - Insira sua descrição principal em
CLIPTextEncode(#6). Você pode escrever em inglês ou chinês, misturar dicas de câmera e iluminação e incluir instruções de texto na imagem. - Um prompt negativo pronto para uso em
CLIPTextEncode(#7) suprime artefatos comuns. Você pode adaptá-lo ao seu estilo ou deixá-lo como está para resultados equilibrados.
Tela latente em 2K nativo#
EmptyHunyuanImageLatent(#29) inicializa a tela em 2048×2048 com um único lote. Hunyuan Image 2.1 é projetado para geração 2K, portanto, tamanhos 2K nativos são recomendados para melhor qualidade.- Ajuste a largura e altura se necessário, mantendo proporções que Hunyuan suporta. Para proporções alternativas, mantenha dimensões amigáveis ao modelo para evitar artefatos.
Amostragem eficiente com Hunyuan Image 2.1#
UNETLoader(#37) carrega o checkpoint FP8 para reduzir o VRAM enquanto preserva a fidelidade, então alimentaKSampler(#3) para remoção de ruído.- Use as condições positivas e negativas dos codificadores para direcionar a composição e clareza. Ajuste a semente para variedade, etapas para qualidade versus velocidade, e orientação para aderência ao prompt.
- O fluxo de trabalho foca no caminho do modelo base. Hunyuan Image 2.1 também suporta uma etapa de refinamento; você pode adicionar uma mais tarde se quiser um polimento extra.
Decodificar e salvar#
VAELoader(#34) traz o VAE do Hunyuan Image 2.1, eVAEDecode(#8) reconstrói a imagem final da latente amostrada com o esquema de compressão 32× do modelo.SaveImage(#9) grava a saída no diretório escolhido. Defina um prefixo claro para o nome do arquivo se planeja iterar entre sementes ou prompts.
Nós principais no fluxo de trabalho Comfyui Hunyuan Image 2.1#
DualCLIPLoader (#33)#
Este nó carrega o par de codificadores de texto que Hunyuan Image 2.1 espera. Mantenha o tipo de modelo definido para Hunyuan, e selecione Qwen2.5‑VL‑7B e ByT5 Small para combinar forte compreensão de cena com manuseio de texto sensível a glifos. Se você iterar no estilo, ajuste o prompt positivo junto com a orientação em vez de trocar codificadores.
CLIPTextEncode (#6 e #7)#
Estes nós transformam seus prompts positivos e negativos em condicionamento. Mantenha o prompt positivo conciso no topo, depois adicione dicas de lente, iluminação e estilo. Use o prompt negativo para suprimir artefatos como membros extras ou texto ruidoso; reduza se achar que está excessivamente restritivo para seu conceito.
EmptyHunyuanImageLatent (#29)#
Define a resolução e lote de trabalho. O padrão 2048×2048 alinha-se com a capacidade nativa 2K do Hunyuan Image 2.1. Para outras proporções, escolha pares de largura e altura amigáveis ao modelo e considere aumentar ligeiramente as etapas se você se afastar muito do quadrado.
KSampler (#3)#
Conduz o processo de remoção de ruído com Hunyuan Image 2.1. Aumente as etapas quando precisar de microdetalhes mais finos, diminua para rascunhos rápidos. Aumente a orientação para uma aderência mais forte ao prompt, mas observe a sobresaturação ou rigidez; diminua para mais variação natural. Troque sementes para explorar composições sem alterar seu prompt.
UNETLoader (#37)#
Carrega o UNet do Hunyuan Image 2.1. O checkpoint FP8 incluído mantém o uso de memória modesto para saída 2K. Se você tiver VRAM suficiente e quiser o máximo de espaço para configurações agressivas, considere uma variante de maior precisão do mesmo modelo das versões oficiais.
VAELoader (#34) e VAEDecode (#8)#
Estes nós devem corresponder ao lançamento do Hunyuan Image 2.1 para decodificar corretamente. O VAE de alta compressão do modelo é fundamental para geração rápida 2K; emparelhar o VAE correto evita mudanças de cor e texturas blocadas. Se você mudar o modelo base, sempre atualize o VAE conforme necessário.
Extras opcionais#
- Prompting
- Hunyuan Image 2.1 responde bem a prompts estruturados: assunto, ação, ambiente, câmera, iluminação, estilo. Para texto na imagem, cite as palavras exatas que deseja e mantenha-as breves.
- Velocidade e memória
- O UNet FP8 já é eficiente. Se precisar espremer ainda mais, desative lotes grandes e prefira menos etapas. Nós opcionais de carregador GGUF estão presentes no gráfico, mas desativados por padrão; usuários avançados podem trocá-los ao experimentar checkpoints quantizados.
- Proporções
- Mantenha tamanhos amigáveis a 2K nativo para melhores resultados. Se aventurar em formatos largos ou altos, verifique uma renderização limpa e considere um pequeno aumento de etapas.
- Refinamento
- Hunyuan Image 2.1 suporta uma etapa de refinamento. Para experimentá-la, adicione um segundo sampler após a passagem base com um checkpoint de refinamento e um leve remoção de ruído para preservar a estrutura enquanto aumenta o microdetalhe.
- Referências
- Detalhes do modelo Hunyuan Image 2.1 e downloads: Hugging Face · GitHub
- Qwen2.5‑VL‑7B‑Instruct: Hugging Face
- ByT5 Small e paper: Hugging Face · Paper
Agradecimentos#
Este fluxo de trabalho implementa e constrói sobre os seguintes trabalhos e recursos. Agradecemos sinceramente @Ai Verse e Hunyuan por Hunyuan Image 2.1 Demo por suas contribuições e manutenção. Para detalhes autoritativos, consulte a documentação original e os repositórios vinculados abaixo.
Recursos#
- Hunyuan/Hunyuan Image 2.1 Demo
- Docs / Notas de Lançamento: Tutorial do Hunyuan Image 2.1 Demo de @Ai Verse
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.


