
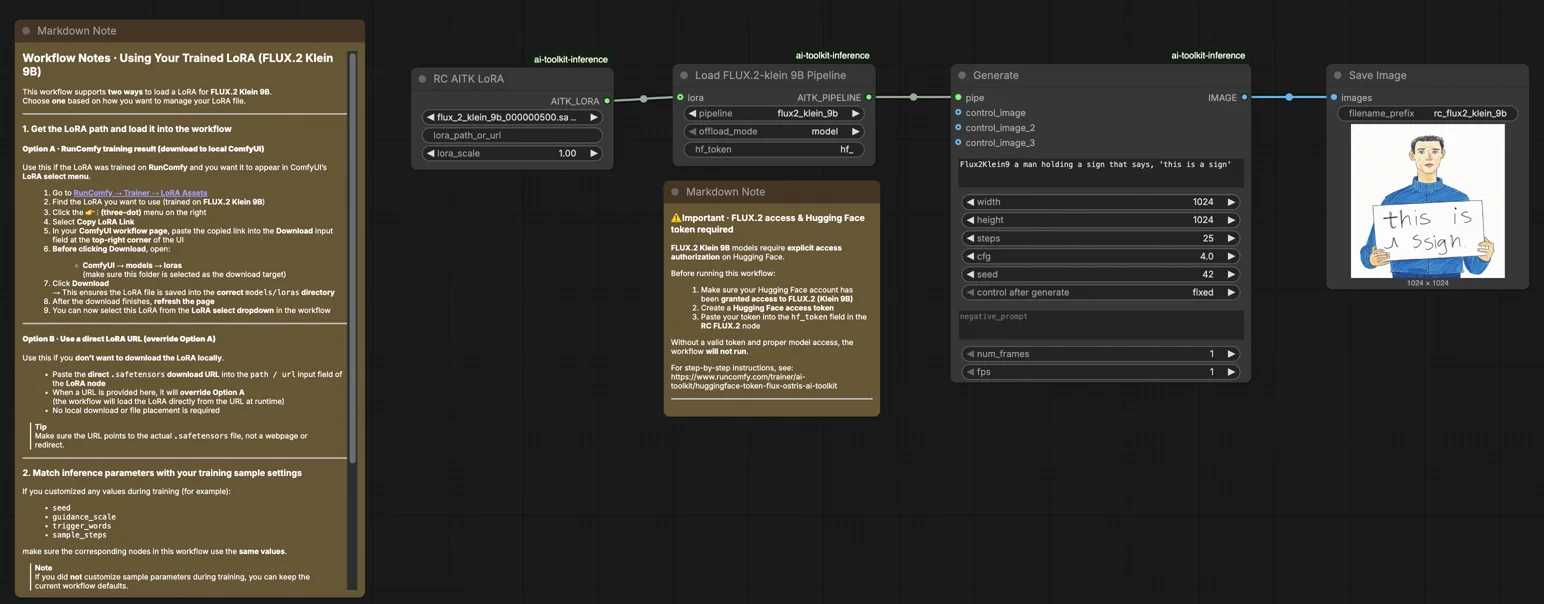
FLUX.2 Klein 9B LoRA ComfyUI Inferência: geração de LoRA alinhada à pré-visualização do AI Toolkit no ComfyUI#
Use este fluxo de trabalho RunComfy quando precisar de inferência ComfyUI que permaneça consistente com as pré-visualizações de treinamento do AI Toolkit para FLUX.2 Klein 9B LoRAs. A configuração roteia a geração através do Flux2Klein9BPipeline—um wrapper de pipeline específico do modelo open-sourced by RunComfy—em vez de um gráfico de amostragem padrão. Seu adaptador é aplicado via lora_path e lora_scale dentro desse pipeline, proporcionando comportamento correspondente ao treinamento de LoRA sem reconstrução manual do pipeline.
Por que a Inferência FLUX.2 Klein 9B LoRA ComfyUI frequentemente parece diferente no ComfyUI#
Quando o AI Toolkit renderiza uma pré-visualização de treinamento, ele executa o pipeline completo de inferência FLUX.2 Klein 9B—codificação de texto Qwen3-8B, agendamento de correspondência de fluxo e injeção interna de LoRA ocorrem como uma unidade coordenada. Um gráfico ComfyUI típico reassembla esses componentes de forma independente, o que introduz diferenças sutis na condicionamento, agendamento de ruído e ordem de aplicação do adaptador. O resultado é um desvio no nível do pipeline, não um único botão mal configurado. Flux2Klein9BPipeline preenche essa lacuna executando o próprio pipeline do modelo de ponta a ponta e injetando seu LoRA dentro dele. Referência: `src/pipelines/flux2_klein.py`.
Como usar o fluxo de trabalho de Inferência FLUX.2 Klein 9B LoRA ComfyUI#
Passo 1: Obtenha o caminho do LoRA e carregue-o no fluxo de trabalho (2 opções)#
Opção A — Resultado de treinamento RunComfy > download para ComfyUI local:
- Vá para Trainer > LoRA Assets
- Encontre o FLUX.2 Klein 9B LoRA que deseja usar
- Clique no menu ... (três pontos) à direita > selecione Copiar Link LoRA
- Na página do fluxo de trabalho ComfyUI, cole o link copiado no campo de entrada Download no canto superior direito da interface
- Antes de clicar em Download, certifique-se de que a pasta de destino está definida como ComfyUI > models > loras (esta pasta deve ser selecionada como destino do download)
- Clique em Download — o arquivo LoRA é salvo no diretório
models/lorascorreto - Após o término do download, atualize a página
- O LoRA agora aparece no menu suspenso de seleção LoRA — selecione-o

Opção B — URL Direto LoRA (substitui a Opção A):
- Cole o URL direto de download
.safetensorsno campo de entradapath / urldo nó LoRA - Quando um URL é fornecido aqui, ele substitui a Opção A — o fluxo de trabalho busca o LoRA diretamente do URL em tempo de execução
- Não é necessário download local ou colocação de arquivo
Dica: confirme se o URL resolve para o arquivo real .safetensors, não uma página de destino ou redirecionamento.

Passo 2: Corresponda os parâmetros de inferência com as configurações de amostra de treinamento#
Defina lora_scale no nó LoRA para controlar a força do adaptador—comece com o valor usado durante as pré-visualizações de treinamento e ajuste a partir daí.
Os parâmetros restantes estão nos nós Generate e Load Pipeline:
prompt— seu prompt de texto; inclua quaisquer palavras de gatilho do treinamentowidth/height— resolução de saída; corresponda ao tamanho da pré-visualização de treinamento para comparação direta (múltiplos de 16)sample_steps— etapas de inferência; FLUX.2 Klein 9B padrão é 25guidance_scale— força CFG; o padrão é 4.0 (Klein 9B não é guidance-distilled, então este valor molda diretamente a qualidade da saída)seed— fixe uma seed para reproduzir uma saída específica; mude para explorar variaçõesseed_mode—fixedourandomizehf_token— um token Hugging Face válido é necessário porque FLUX.2 Klein 9B é um modelo restrito; cole seu token no campohf_tokenno nó Load Pipeline
Dica de alinhamento de treinamento: se você personalizou os valores de amostragem durante o treinamento (seed, guidance_scale, sample_steps, palavras de gatilho), copie esses valores exatos para os campos correspondentes. Se você treinou no RunComfy, abra Trainer > LoRA Assets > Config para ver o YAML resolvido e transferir as configurações de pré-visualização/amostra.

Passo 3: Execute a Inferência FLUX.2 Klein 9B LoRA ComfyUI#
Clique em Queue/Run — o nó SaveImage grava os resultados na sua pasta de saída do ComfyUI.
⚠️ Importante · Acesso FLUX.2 & token Hugging Face necessário#
Os modelos FLUX.2 Klein 9B exigem autorização de acesso explícita no Hugging Face.
Antes de executar este fluxo de trabalho:
- Certifique-se de que sua conta Hugging Face tenha sido autorizada a acessar o FLUX.2 (Klein 9B)
- Crie um token de acesso Hugging Face
- Cole seu token no campo
hf_tokenno nó RC FLUX.2
Sem um token válido e acesso adequado ao modelo, o fluxo de trabalho não funcionará.
Para instruções passo a passo, veja: https://www.runcomfy.com/trainer/ai-toolkit/huggingface-token-flux-ostris-ai-toolkit
Lista de verificação rápida:
- ✅ Conta Hugging Face tem acesso ao FLUX.2 Klein 9B e um token válido está em
hf_token - ✅ LoRA está: baixado em
ComfyUI/models/loras(Opção A), ou carregado via um URL direto.safetensors(Opção B) - ✅ Página atualizada após o download local (somente Opção A)
- ✅ Parâmetros de inferência correspondem ao config de
samplede treinamento (se personalizado)
Se tudo acima estiver correto, os resultados de inferência aqui devem corresponder de perto às suas pré-visualizações de treinamento.
Solução de problemas de Inferência FLUX.2 Klein 9B LoRA ComfyUI#
A maioria das lacunas de “pré-visualização de treinamento vs inferência ComfyUI” no FLUX.2 Klein 9B vem de diferenças no nível do pipeline (caminho do codificador de texto, agendador/condicionamento e onde/como o adaptador é aplicado). O fluxo de trabalho RunComfy evita reconstruir o pipeline manualmente executando a geração através do Flux2Klein9BPipeline e injetando o LoRA dentro desse pipeline via lora_path / lora_scale, que é a maneira mais próxima de reproduzir o comportamento da pré-visualização do AI Toolkit no ComfyUI.
(1) Erro 401 Cliente.#
Por que isso acontece FLUX.2 Klein 9B é um modelo restrito do Hugging Face. Se sua conta não tiver acesso, ou nenhum token válido for fornecido, os pesos do modelo não podem ser baixados e a inferência falha com um erro 401.
Como corrigir
- Certifique-se de que sua conta Hugging Face tenha sido autorizada a acessar
black-forest-labs/FLUX.2-klein-base-9B. - Crie um token de acesso Hugging Face e cole-o no campo
hf_tokenno nó Load Pipeline. - Após confirmar o acesso e o token, execute a inferência através dos nós do pipeline do RunComfy AI Toolkit para que a autenticação e o carregamento do modelo ocorram em um pipeline consistente.
- Para instruções passo a passo, veja: https://www.runcomfy.com/trainer/ai-toolkit/huggingface-token-flux-ostris-ai-toolkit
(2) Erros CLIPLoader de modelos Flux 2 Klein#
Por que isso acontece Esses erros são causados por um descompasso do codificador de texto—por exemplo, carregando um codificador incompatível ou misturando ativos de codificador Klein 4B e Klein 9B. Isso geralmente aparece como desajustes de tamanho de incorporação ou vocabulário durante o carregamento do CLIP/codificador de texto.
Como corrigir
- Atualize o ComfyUI para a versão mais recente para garantir que o suporte FLUX.2 Klein esteja completo.
- Certifique-se de que o codificador de texto correto para Klein 9B é usado (Klein 9B requer Qwen3-8B; usar um codificador 4B falhará).
- Para inferência de LoRA alinhada à pré-visualização, prefira o wrapper de pipeline do RunComfy, que carrega o codificador correto e aplica o LoRA no mesmo pipeline usado para as pré-visualizações do AI Toolkit.
(3) formas de mat1 e mat2 não podem ser multiplicadas (512x2560 e 7680x3072)#
Por que isso acontece Este erro indica um descompasso de dimensão de condicionamento, tipicamente causado por usar o codificador errado ou um tipo de clip/condicionamento incorreto para FLUX.2 Klein 9B. O modelo recebe embeddings do formato errado, causando falha na multiplicação de matrizes durante a amostragem.
Como corrigir
- Se estiver montando gráficos manualmente, verifique se você está usando o codificador de texto específico FLUX.2 Klein e se o tipo de clip/condicionamento corresponde às expectativas do FLUX.2 Klein.
- Para a correção mais confiável, execute a inferência através do wrapper de pipeline FLUX.2 Klein 9B do RunComfy (
model_type = flux2_klein_9b) e injete seu LoRA vialora_path. Isso mantém toda a pilha de inferência—codificador, agendador e adaptador—alinhada ao pipeline com as pré-visualizações do AI Toolkit.
Execute agora a Inferência FLUX.2 Klein 9B LoRA ComfyUI#
Carregue o fluxo de trabalho, cole seu lora_path, insira um hf_token válido e deixe Flux2Klein9BPipeline manter a saída ComfyUI alinhada com suas pré-visualizações de treinamento do AI Toolkit.

