
Inferência Flex.1 LoRA: Execute AI Toolkit LoRA no ComfyUI para Resultados Correspondentes ao Treinamento#
Inferência Flex.1 LoRA: geração correspondente ao treinamento, em etapas mínimas no ComfyUI. A Inferência Flex.1 LoRA é um fluxo de trabalho RunComfy pronto para produção para executar Flex.1 LoRAs treinadas no AI Toolkit no ComfyUI com comportamento correspondente ao treinamento. É construído em torno do RC Flex.1 (RCFlex1), que envolve um pipeline de inferência específico para Flex.1 (em vez de um gráfico de amostragem genérico) e aplica sua LoRA de maneira consistente via lora_path e lora_scale; o RunComfy construiu e disponibilizou este nó em código aberto—veja o código nos repositórios da organização runcomfy-com no GitHub.
Use quando sua inferência LoRA parecer diferente do treinamento—por exemplo, as pré-visualizações do AI Toolkit parecem corretas, mas a mesma LoRA + prompt parece incorreta quando você muda para o ComfyUI.
Por que a Inferência Flex.1 LoRA muitas vezes parece diferente no ComfyUI & O que o nó personalizado RCFlex1 faz#
As pré-visualizações do AI Toolkit vêm de um pipeline de inferência específico para Flex.1. Muitos gráficos do ComfyUI reconstroem a pilha a partir de carregadores e amostradores genéricos, então "corresponder os números" (prompt/steps/CFG/seed) nem sempre é suficiente—diferenças no pipeline podem alterar padrões e onde/como a LoRA é aplicada.
RCFlex1 direciona a inferência por meio de um invólucro de pipeline específico para Flex.1 alinhado com as pré-visualizações do AI Toolkit, mantendo a injeção de LoRA consistente para Flex.1. Implementação de referência: `src/pipelines/flex1_alpha.py`
Como usar o fluxo de trabalho de Inferência Flex.1 LoRA#
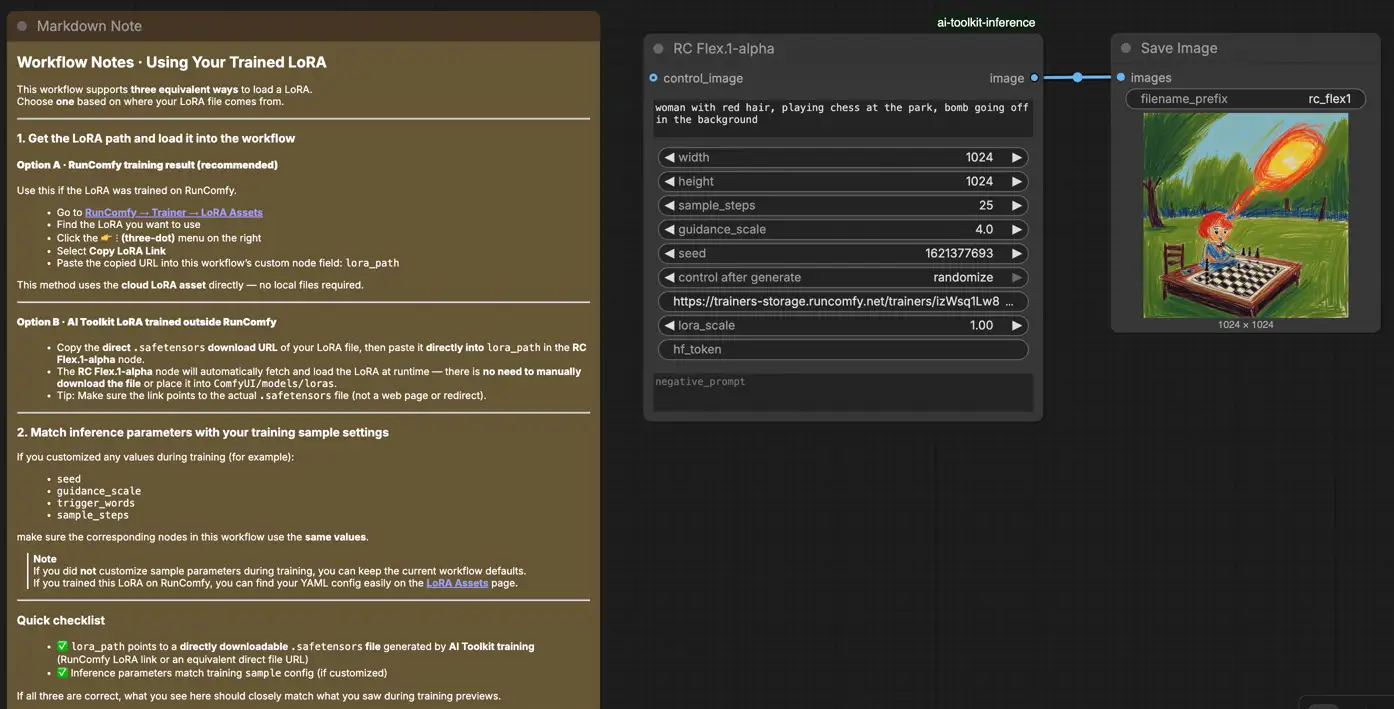
Passo 1: Abra o fluxo de trabalho#
Abra o fluxo de trabalho RunComfy Flex.1 LoRA Inference no ComfyUI.
Passo 2: Importe sua LoRA (2 opções)#
- Opção A (resultado de treinamento RunComfy): RunComfy → Trainer → LoRA Assets → encontre sua LoRA → ⋮ → Copy LoRA Link

- Opção B (AI Toolkit LoRA treinada fora do RunComfy): Copie um link de download direto
.safetensorspara sua LoRA e cole esse URL emlora_path(não é necessário baixá-lo paraComfyUI/models/loras).
Passo 3: Configure o RCFlex1 para Inferência Flex.1 LoRA#
Na interface do nó RCFlex1 Flex.1 LoRA Inference, defina os parâmetros restantes:
prompt: seu prompt de texto principal (inclua quaisquer tokens de gatilho que você usou durante o treinamento)negative_prompt: opcional; deixe em branco se você não usou um na amostragem de pré-visualizaçãowidth/height: resolução de saídasample_steps: etapas de amostragem (corresponda às suas configurações de pré-visualização ao comparar resultados)guidance_scale: CFG / orientação (corresponda ao seu CFG de pré-visualização)seed: use uma seed fixa para reprodutibilidade; altere-a para explorar variaçõeslora_scale: intensidade/força da LoRA
Para resultados correspondentes ao treinamento, abra seu YAML de treinamento do AI Toolkit e aplique os mesmos valores de amostragem aqui—especialmente width, height, sample_steps, guidance_scale, e seed. Se você treinou no RunComfy, abra Trainer → LoRA Assets → Config e reutilize os valores de pré-visualização/amostra.

Passo 4: Execute a Inferência Flex.1 LoRA#
- Clique em Queue/Run → SaveImage grava a saída automaticamente
Solucionando problemas de Inferência Flex.1 LoRA#
A maioria das incompatibilidades "pré-visualização de treinamento vs inferência no ComfyUI" vem de diferenças no pipeline (não de um único botão errado). A maneira mais rápida de recuperar resultados correspondentes ao treinamento é executar a inferência por meio do nó personalizado RC Flex.1 (RCFlex1) do RunComfy, que mantém a amostragem Flex.1 + injeção de LoRA alinhadas no nível do pipeline com o pipeline de pré-visualização do AI Toolkit.
(1) Por que a pré-visualização da amostra no AI Toolkit parece ótima, mas o mesmo prompt parece diferente no ComfyUI? Como posso reproduzir isso no ComfyUI?#
Por que isso acontece
Mesmo com o mesmo prompt / seed / steps, os resultados podem divergir quando o ComfyUI está executando um pipeline de inferência diferente do pipeline de pré-visualização do AI Toolkit. Com Flex.1 especificamente, diferenças no pipeline podem alterar padrões do modelo e onde/como a LoRA é injetada, o que se manifesta como "mesmo prompt, aparência diferente".
Como corrigir (recomendado)
- Execute a inferência com RCFlex1 para manter a inferência alinhada ao pipeline com as pré-visualizações do AI Toolkit (esta é a principal alavanca).
- Espelhe suas configurações de amostragem de pré-visualização do AI Toolkit:
width,height,sample_steps,guidance_scale,seed. - Use as mesmas palavras de gatilho (se você treinou com elas) e mantenha
lora_scaleigual à força de sua pré-visualização.
(2) Como carregar flux lora em flex usando diffusers#
Por que isso acontece
Flex.1 se desviou do Flux, então "carregá-lo como um Flux LoRA normal" pode levar a aplicação parcial, efeito fraco ou comportamento inesperado—especialmente se a LoRA não foi treinada para Flex.1.
Como corrigir (mais confiável)
- Para Flex.1 LoRAs treinadas no AI Toolkit: carregue via
lora_pathno RCFlex1 para que a injeção de LoRA aconteça dentro do pipeline de inferência alinhado Flex.1. - Se a LoRA foi treinada para um modelo base diferente, não espere transferência perfeita—reentreine a LoRA no Flex.1 no AI Toolkit para os resultados mais limpos.
(3) O objeto Flux não tem o atributo 'process_timestep#
Por que isso acontece
Isso geralmente indica um desajuste entre os nós/código que você está executando e o modelo/pipeline que você acha que está executando (desvio de versão, conjunto de nós errado ou mistura de ferramentas Flex/Flux incompatíveis).
Como corrigir
- Prefira executar a inferência Flex.1 por meio do RCFlex1, que mantém o caminho de execução no invólucro de pipeline Flex.1 pretendido.
- Se você atualizou o ComfyUI ou nós personalizados recentemente, atualize os nós relacionados e reinicie o ComfyUI para limpar importações/caches antigos.
- Verifique se você está realmente carregando Flex.1 como o modelo base para este fluxo de trabalho (não uma variante Flux diferente).
Execute a Inferência Flex.1 LoRA agora#
Abra o fluxo de trabalho RunComfy Flex.1 LoRA Inference, cole sua LoRA em lora_path, e execute RCFlex1 para inferência Flex.1 LoRA correspondente ao treinamento no ComfyUI.
