






Virtual Try-On no ComfyUI com Edição de Imagem Qwen#
Este fluxo de trabalho Virtual Try-On gera visuais realistas de uma pessoa vestindo roupas selecionadas ao combinar uma foto de sujeito com uma ou mais imagens de roupa. Ele é projetado para moda, e-commerce e equipes de conteúdo que precisam de pré-visualizações rápidas de roupas sem composição manual ou sessões de fotos. O resultado é uma renderização limpa e bem ajustada que respeita a forma do corpo, pose, iluminação e características do tecido.
Nos bastidores, o gráfico condiciona a Edição de Imagem Qwen com suas imagens e um prompt em linguagem natural, guiando a edição para a transferência de vestuário. Você fornece uma imagem de pessoa e até três imagens de roupas; o fluxo de trabalho as organiza em um único painel de referência e realiza uma edição de imagem que coloca de forma confiável as roupas escolhidas no sujeito. Uma saída lado a lado integrada facilita a inspeção e iteração.
Modelos principais no fluxo de trabalho ComfyUI Virtual Try-On#
- Qwen-Image-Edit. O modelo central de edição por difusão que suporta edições semânticas e edições que preservam a aparência, permitindo trocas de roupas que seguem a pose do corpo e a iluminação enquanto mantêm a identidade. Model card
- Qwen2.5-VL 7B. O codificador de visão-linguagem usado para seguir instruções e compreensão visual, que ajuda o modelo a interpretar seu prompt e o painel de referência. Model card
- Qwen Image VAE. O autoencoder variacional usado para codificar e decodificar latentes de imagem, alinhado com a família de Imagens Qwen para resultados estáveis. Assets
- Virtual Try-On LoRA. Um adaptador leve especializado em transferência de vestuário que aprimora a colocação de roupas e a dinâmica de ajuste. Ele direciona a edição para a aplicação de roupas enquanto preserva o sujeito.
Como usar o fluxo de trabalho ComfyUI Virtual Try-On#
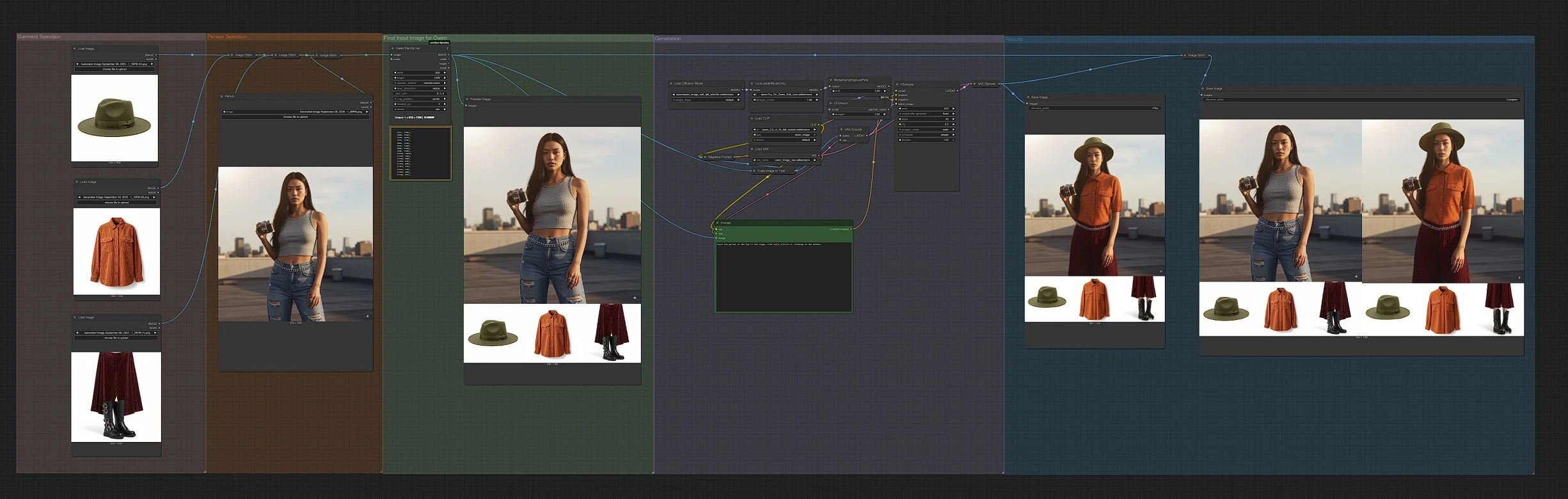
Em resumo: o fluxo de trabalho organiza suas entradas em uma única imagem onde a pessoa fica no topo e as roupas aparecem abaixo, depois codifica este painel e executa a Edição de Imagem Qwen para produzir o resultado do try-on. Os grupos trabalham em sequência da esquerda para a direita: Seleção de Roupas, Seleção de Pessoa, Imagem de Entrada Final para Qwen, Geração e Resultados.
Seleção de Roupas#
Carregue até três fotos de produtos nos nós de LoadImage de vestuário (LoadImage (#175), LoadImage (#177), LoadImage (#179)). O fluxo de trabalho compõe estas com ImageStitch (#280) e ImageStitch (#282) para formar uma faixa de roupas limpa. Fotos de produtos frontais com fundos desobstruídos funcionam melhor e tornam o Virtual Try-On mais confiável. Use uma peça de roupa ou várias para deixar o prompt escolher, e mantenha a escala consistente entre as imagens.
Seleção de Pessoa#
Adicione a foto do seu sujeito a LoadImage (#170). O gráfico empilha a imagem da pessoa acima da faixa de roupas usando ImageStitch (#284) para que o layout corresponda à instrução padrão. Uma visão frontal centralizada com iluminação clara aumenta o realismo. Almeje uma pose compatível com as roupas que você pretende experimentar.
Imagem de Entrada Final para Qwen#
O painel composto é padronizado com Qwen friendly res (ImageResizeKJv2 (#196)) para uma resolução favorecida pelos modelos de Imagem Qwen, e opcionalmente escalado via ImageScaleToTotalPixels (#115) para velocidade ou detalhe. Um PreviewImage (#240) mostra exatamente o que o modelo verá. Use Prompt (TextEncodeQwenImageEdit (#121)) para descrever a roupa que você quer na pessoa, por exemplo: "Vista a pessoa no topo da imagem com o casaco e a camisa mostrados abaixo." Se necessário, adicione restrições em Negative Prompt (TextEncodeQwenImageEdit (#114)) para evitar artefatos como mangas extras ou padrões incompatíveis.
Geração#
A espinha dorsal da difusão carrega Qwen-Image-Edit e aplica o try-on LoRA usando LoraLoaderModelOnly (#233), depois executa o sampler KSampler (#122) para realizar a edição. O modelo recebe dois sinais alinhados: semântica visual do painel e prompt, e aparência dos latentes de imagem codificados, um design que a Edição de Imagem Qwen usa para equilibrar identidade e fidelidade. Isso produz uma renderização Virtual Try-On realista que se ajusta à pose e iluminação do sujeito.
Resultados#
VAEDecode (#119) converte o latente em uma imagem que é salva como a saída principal do Virtual Try-On por SaveImage (#116). Para avaliação rápida, ImageStitch (#250) cria um painel de “Comparar” lado a lado da visão de entrada do modelo e o resultado final, depois SaveImage (#251) grava no disco. Use a visão de comparação para refinar prompts, trocar roupas ou ajustar entradas até que o ajuste pareça correto.
Nós principais no fluxo de trabalho ComfyUI Virtual Try-On#
Prompt (#121)#
Constrói o condicionamento que diz à Edição de Imagem Qwen como vestir o sujeito usando as roupas mostradas abaixo. Escreva instruções claras que referenciem posição e tipo de vestuário, por exemplo "Coloque o blazer preto e a camiseta branca na pessoa, mantenha as joias e o cabelo inalterados." Se várias roupas forem fornecidas, você pode especificar quais usar ou deixar o modelo escolher. Pequenas mudanças de palavras podem melhorar o alinhamento e reduzir a superedição.
Negative Prompt (#114)#
Fornece diretrizes para desencorajar edições indesejadas. Adicione termos concisos como "sem mangas extras, sem mudanças de logotipo, sem mudança de fundo" para preservar o contexto da cena e detalhes do produto. Use isso quando você ver artefatos como colares duplicados, padrões distorcidos ou mudanças de cor não intencionais.
Qwen friendly res (#196)#
Unifica o painel composto para dimensões amigáveis ao Qwen para geometria estável e melhor alinhamento de roupas. Escolha um aspecto que corresponda à sua moldura de sujeito e deixe espaço para a faixa de roupa abaixo. Se você mudar a orientação, atualize o prompt para que ele ainda descreva "pessoa no topo, roupas na parte inferior."
LoraLoaderModelOnly (#233)#
Aplica o LoRA Virtual Try-On que fortalece o comportamento de transferência de roupas. Se os resultados parecerem super estilizados ou a identidade se desviar, diminua o peso do LoRA. Se as roupas não estiverem sendo transferidas com confiança, aumente levemente. Execute novamente com a mesma seed para comparar mudanças de forma confiável.
KSampler (#122)#
Controla o detalhe e a aderência às suas instruções. Aumente os passos moderadamente para maior fidelidade ou diminua-os para pré-visualizações mais rápidas. Ajuste a escala de orientação se a edição estiver muito fraca ou muito agressiva e defina uma seed fixa quando você quiser resultados de Virtual Try-On repetíveis.
Extras opcionais#
- Escreva prompts que reflitam o layout: "Vista a pessoa no topo da imagem com as roupas mostradas na parte inferior."
- Fotos de produtos com fundos limpos e vistas frontais transferem-se de forma mais confiável no Virtual Try-On.
- Tamanhos amigáveis ao Qwen recomendados que funcionam bem: 832 x 1248, 1024 x 1024, 1248 x 832, 944 x 1104, 1184 x 880, 1328 x 800.
- Para pré-visualizações mais rápidas, reduza o número total de pixels em
ImageScaleToTotalPixels(#115), depois aumente para sua passagem final. - Se o ajuste estiver próximo, mas as texturas desalinhadas, tente um pequeno ajuste no prompt como "garantir que as mangas se alinhem com os braços" ou "manter a queda do tecido natural."
- Para preservação do fundo, adicione negativos como "não mudar o fundo" e evite termos de estilo que impliquem reestilização da cena.
Referências úteis sobre os modelos subjacentes:
- Model card do Qwen-Image-Edit: Hugging Face
- Model card do Qwen2.5-VL 7B: Hugging Face
- Recursos de Imagem Qwen para ComfyUI: Hugging Face
- Visão geral do projeto Qwen Image: GitHub
Agradecimentos#
Este fluxo de trabalho implementa e se baseia nos seguintes trabalhos e recursos. Agradecemos a @BenjisAIPlayground do Virtual Try-On Demo pelo fluxo de trabalho de demonstração. Para detalhes autoritativos, consulte a documentação e os repositórios originais vinculados abaixo.
Recursos#
- YouTube/Virtual Try-On Demo
- Docs / Release Notes @BenjisAIPlayground: Virtual Try-On Demo
Nota: O uso dos modelos, conjuntos de dados e código referenciados está sujeito às respectivas licenças e termos fornecidos por seus autores e mantenedores.




