
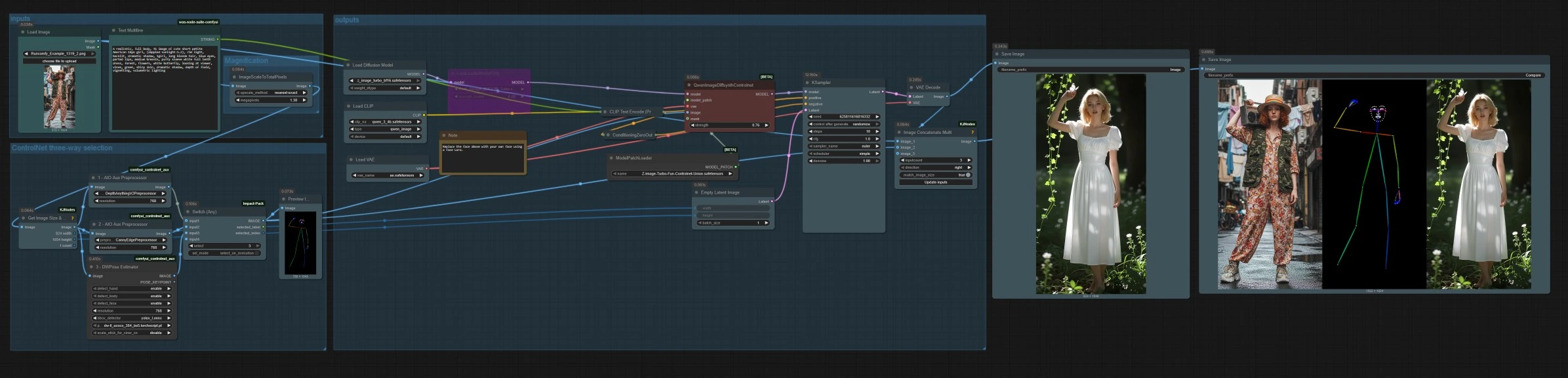








ComfyUI에서 구조 기반 이미지 생성을 위한 Z 이미지 ControlNet 워크플로우#
이 워크플로우는 ComfyUI에 Z 이미지 ControlNet을 도입하여 참조 이미지에서 정밀한 구조로 Z-Image Turbo를 조종할 수 있도록 합니다. 하나의 그래프에 세 가지 가이드 모드를 번들로 제공하며, 깊이, 캔니 가장자리 및 인간 포즈를 포함하여 작업에 맞게 전환할 수 있습니다. 결과는 빠르고 고품질의 텍스트 또는 이미지-투-이미지 생성을 제공하며, 레이아웃, 포즈 및 구성이 제어되면서 반복할 수 있습니다.
아티스트, 컨셉 디자이너 및 레이아웃 플래너를 위해 설계된 이 그래프는 이중 언어 프롬프트 및 선택적 LoRA 스타일링을 지원합니다. 선택한 제어 신호의 깨끗한 미리보기를 얻고 깊이, 캔니 또는 포즈를 최종 출력과 비교하는 자동 비교 스트립을 제공합니다.
Comfyui Z 이미지 ControlNet 워크플로우의 주요 모델#
- Z-Image Turbo 확산 모델 6B 매개변수. 프롬프트 및 제어 신호로부터 사실적인 이미지를 빠르게 생성하는 주요 생성기입니다. alibaba-pai/Z-Image-Turbo
- Z 이미지 ControlNet 유니온 패치. Z-Image Turbo에 다중 조건 제어를 추가하고 하나의 모델 패치에서 깊이, 가장자리 및 포즈 가이드를 가능하게 합니다. alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
- Depth Anything v2. 깊이 모드에서 구조 지침으로 사용되는 밀집 깊이 지도를 생성합니다. LiheYoung/Depth-Anything-V2 on GitHub
- DWPose. 포즈 기반 생성에 필요한 인간 키포인트와 신체 포즈를 추정합니다. IDEA-Research/DWPose
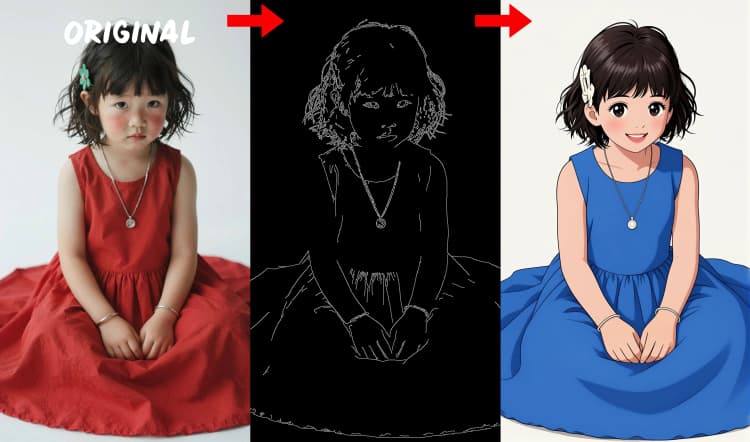
- 캔니 가장자리 감지기. 레이아웃 중심 제어를 위한 깨끗한 선화 및 경계를 추출합니다.
- ComfyUI용 ControlNet Aux 전처리기. 이 그래프에서 사용되는 깊이, 가장자리 및 포즈에 대한 통합된 래퍼를 제공합니다. comfyui_controlnet_aux
Comfyui Z 이미지 ControlNet 워크플로우 사용 방법#
높은 수준에서 참조 이미지를 로드하거나 업로드하고, 깊이, 캔니 또는 포즈 중 하나의 제어 모드를 선택한 다음 텍스트 프롬프트로 생성합니다. 그래프는 효율적인 샘플링을 위해 참조를 스케일링하고, 일치하는 가로 세로 비율로 잠재를 구축하며, 최종 이미지와 나란히 비교 스트립을 저장합니다.
입력#
LoadImage (#14)를 사용하여 참조 이미지를 선택합니다. Text Multiline (#17)에 텍스트 프롬프트를 입력합니다. Z-Image 스택은 이중 언어 프롬프트를 지원합니다. 프롬프트는 CLIPLoader (#2) 및 CLIPTextEncode (#4)에 의해 인코딩됩니다. 순수한 구조 기반 이미지-투-이미지를 선호한다면 프롬프트를 최소화하고 선택한 제어 신호에 의존할 수 있습니다.
ControlNet 세 가지 선택#
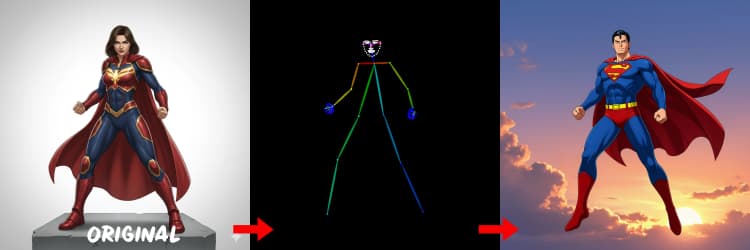
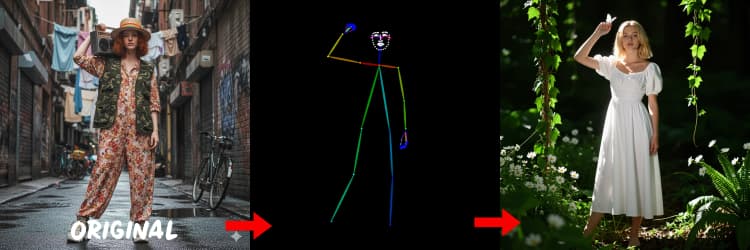
세 가지 전처리기가 참조를 제어 신호로 변환합니다. AIO_Preprocessor (#45)는 Depth Anything v2로 깊이를 생성하고, AIO_Preprocessor (#46)는 캔니 가장자리를 추출하며, DWPreprocessor (#56)는 전체 신체 포즈를 추정합니다. ImpactSwitch (#58)를 사용하여 Z 이미지 ControlNet을 구동하는 신호를 선택하고, PreviewImage (#43)를 확인하여 선택한 제어 맵을 확인합니다. 장면 기하학을 원할 때 깊이를, 명확한 레이아웃이나 제품 사진을 원할 때 캔니를, 캐릭터 작업을 원할 때 포즈를 선택하세요.
OpenPose에 대한 팁: 1. 전체 신체에 가장 적합: OpenPose는 프롬프트에 "전체 신체"를 포함할 때 가장 잘 작동합니다 (~70-90% 정확도). 2. 클로즈업에는 피하세요: 얼굴에 대한 정확도는 크게 떨어집니다. 대신 Depth 또는 Canny (낮음/중간 강도)를 사용하세요. 3. 프롬프트가 중요합니다: 프롬프트는 ControlNet에 큰 영향을 미칩니다. 비어 있는 프롬프트를 피하여 흐릿한 결과를 방지하세요.
확대#
ImageScaleToTotalPixels (#34)는 품질과 속도의 균형을 맞추기 위해 참조를 실용적인 작업 해상도로 조정합니다. GetImageSizeAndCount (#35)은 스케일된 크기를 읽고 너비와 높이를 전달합니다. EmptyLatentImage (#6)는 리사이즈된 입력의 비율에 맞는 잠재 캔버스를 생성하여 구성이 일관되게 유지됩니다.
출력#
QwenImageDiffsynthControlnet (#39)는 기본 모델을 Z 이미지 ControlNet 유니온 패치 및 선택한 제어 이미지와 융합하고, KSampler (#7)는 긍정적 및 부정적 조건에 의해 안내된 결과를 생성합니다. VAEDecode (#8)는 잠재를 이미지로 변환합니다. 워크플로우는 두 가지 출력을 저장합니다. SaveImage (#31)는 최종 이미지를 기록하고, SaveImage (#42)는 ImageConcatMulti (#38)를 통해 참조, 제어 맵 및 결과를 포함하는 비교 스트립을 기록하여 빠른 QA를 제공합니다.
Comfyui Z 이미지 ControlNet 워크플로우의 주요 노드#
ImpactSwitch (#58)#
생성을 구동하는 제어 이미지를 선택합니다. 깊이, 캔니 또는 포즈를 선택하여 각 제한이 구성을 어떻게 형성하는지 비교합니다. 레이아웃을 반복할 때 목표에 가장 적합한 가이드를 빠르게 테스트할 수 있습니다.
QwenImageDiffsynthControlnet (#39)#
기본 모델, Z 이미지 ControlNet 유니온 패치, VAE 및 선택한 제어 신호를 연결합니다. strength 매개변수는 모델이 제어 입력을 얼마나 엄격하게 따르는지와 프롬프트를 결정합니다. 엄격한 레이아웃 일치를 위해 강도를 높이고, 창의적인 변화를 위해서는 줄입니다.
AIO_Preprocessor (#45)#
Depth Anything v2 파이프라인을 실행하여 밀집 깊이 지도를 생성합니다. 더 자세한 구조를 위해 해상도를 높이거나 더 빠른 미리보기를 위해 줄입니다. 건축 장면, 제품 사진 및 기하학이 중요한 풍경과 잘 어울립니다.
DWPreprocessor (#56)#
사람 및 캐릭터에 적합한 포즈 지도를 생성합니다. 사지 가시성이 좋고 심하게 가려지지 않을 때 가장 잘 작동합니다. 손이나 다리가 보이지 않으면 더 명확한 참조 또는 더 완전한 신체 가시성을 가진 다른 프레임을 시도하세요.
LoraLoaderModelOnly (#54)#
스타일 또는 아이덴티티 큐를 위한 선택적 LoRA를 기본 모델에 적용합니다. strength_model을 조정하여 LoRA를 부드럽게 또는 강하게 혼합합니다. 얼굴 LoRA를 교체하여 피사체를 개인화하거나 스타일 LoRA를 사용하여 특정 모양을 고정할 수 있습니다.
KSampler (#7)#
프롬프트 및 제어를 사용하여 확산 샘플링을 수행합니다. 반복 가능성을 위해 seed, 정제 예산을 위해 steps, 프롬프트 준수를 위해 cfg, 초기 잠재로부터의 편차를 위해 denoise를 조정합니다. 이미지-투-이미지 편집의 경우, 구조를 유지하기 위해 denoise를 낮추고, 더 큰 변화를 허용하려면 값을 높입니다.
선택적 추가 기능#
- 구성을 단단히 조여야 할 때, 깨끗하고 균일하게 조명된 참조와 함께 깊이 모드를 사용하세요. 캔니는 강한 대비에 적합하고, 포즈는 전체 신체 샷에 적합합니다.
- 원본 이미지에서 미세한 편집을 위해, denoise를 적당히 유지하고 ControlNet 강도를 높여 충실한 구조를 얻으세요.
- 더 많은 세부 사항이 필요할 때, 확대 그룹의 대상 픽셀을 늘린 후 빠른 초안을 위해 다시 줄이세요.
- 비교 출력을 사용하여 깊이 대 캔니 대 포즈를 빠르게 A/B 테스트하여 주제에 가장 신뢰할 수 있는 제어를 선택하세요.
- 예제 LoRA를 자신의 얼굴 또는 스타일 LoRA로 교체하여 재훈련 없이 아이덴티티 또는 아트 방향을 통합하세요.
감사의 글#
이 워크플로우는 다음 작업 및 리소스를 구현하고 확장합니다. Z 이미지 ControlNet을 위한 Alibaba PAI의 기여 및 유지 관리에 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서 및 저장소를 참조하세요.
리소스#
- Alibaba PAI/Z 이미지 ControlNet
- Hugging Face: alibaba-pai/Z-Image-Turbo-Fun-Controlnet-Union
참고: 참조된 모델, 데이터셋 및 코드의 사용은 해당 저자 및 유지 관리자가 제공한 라이센스 및 조건에 따릅니다.

