
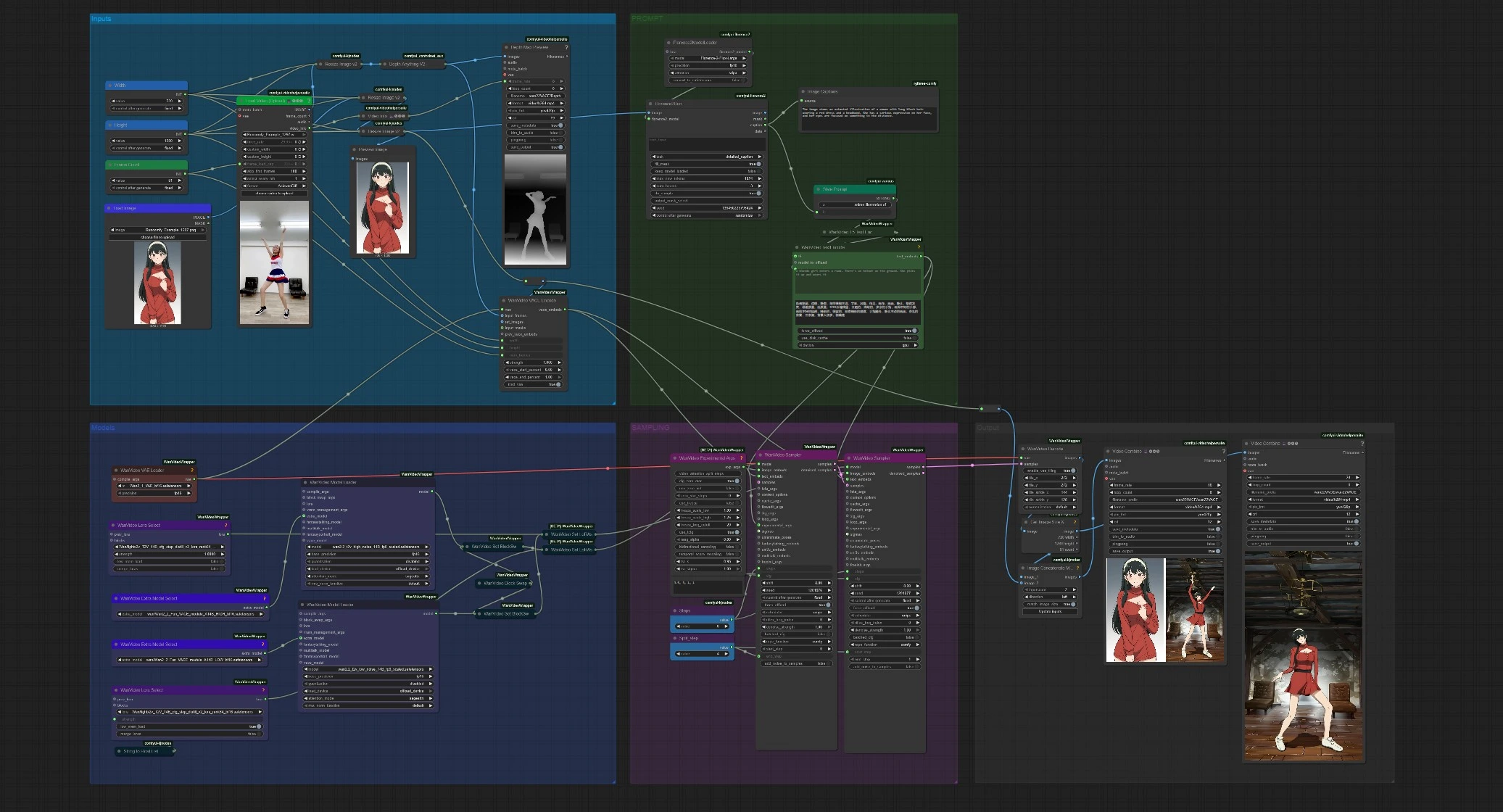
ComfyUI를 위한 Wan 2.2 VACE 포즈 기반 비디오 생성#
이 ComfyUI Wan 2.2 VACE 워크플로우는 단일 참조 이미지를 소스 클립의 포즈, 리듬 및 카메라 움직임을 따르는 동작 일치 비디오로 변환합니다. Wan 2.2 VACE를 사용하여 정체성을 보존하면서 복잡한 신체 동작을 부드럽고 현실적인 애니메이션으로 변환합니다.
댄스 생성, 모션 전송 및 창의적인 캐릭터 애니메이션을 위해 설계된 이 워크플로우는 참조 이미지에서 스타일 프롬프트를 자동화하고, 소스 비디오에서 모션 신호를 추출하며, 모션 일관성과 세부사항을 균형 있게 조정하는 두 단계의 Wan 2.2 샘플러를 실행합니다.
ComfyUI Wan 2.2 VACE 워크플로우의 주요 모델#
- Wan 2.2 14B 텍스트-비디오 모델 (고노이즈 및 저노이즈 변종). 이중 단계는 세부 정제를 위해 저노이즈 백본을 사용하는 강력한 모션 형성을 위해 고노이즈 백본을 사용합니다.
- Wan 2.1 VAE (bf16). Wan 2.2 VACE를 위한 잠재 비디오 프레임을 디코딩하고 인코딩합니다.
- Google UMT5-XXL 인코더. Wan 2.2에서 조건화에 사용되는 높은 용량의 텍스트 기능을 제공합니다. Model card
- Microsoft Florence-2 (Flux Large). 참조 이미지에서 풍부한 캡션을 생성하여 프롬프트를 부트스트랩하고 스타일화합니다. Repo
- Depth Anything v2 (ViT-L). 모션 소스 비디오에서 프레임별 깊이 맵을 생성하여 구조와 움직임을 안내합니다. Repo
ComfyUI Wan 2.2 VACE 워크플로우 사용 방법#
워크플로우는 다섯 개의 그룹화된 단계로 나뉩니다: 입력, 프롬프트, 모델, 샘플링, 출력. 참조 이미지 하나와 짧은 모션 비디오 하나를 제공합니다. 그래프는 모션 안내를 계산하고, VACE 정체성 기능을 인코딩하며, 두 번의 Wan 2.2 샘플러를 실행하고 최종 애니메이션과 선택적 사이드바이사이드 미리보기를 저장합니다.
입력#
VHS_LoadVideo (#141)에서 모션 소스 클립을 로드합니다. 간단한 컨트롤로 트림하고 메모리 한도를 설정할 수 있습니다. 프레임은 일관성을 위해 크기가 조정된 후 DepthAnythingV2Preprocessor (#135)가 포즈, 레이아웃 및 카메라 움직임을 포착하는 밀집 깊이 시퀀스를 계산합니다. LoadImage (#113)로 정체성 이미지를 로드합니다; 자동으로 크기가 조정되고 미리보기되어 샘플링 전 프레이밍을 확인할 수 있습니다.
프롬프트#
Florence2Run (#137)이 참조 이미지를 분석하고 자세한 캡션을 반환합니다. Style Prompt (#138)이 그 캡션을 짧은 스타일 문구와 연결한 후, WanVideoTextEncode (#16)가 UMT5-XXL을 사용하여 최종 긍정적 및 부정적 프롬프트를 인코딩합니다. 스타일 문구를 자유롭게 편집하거나 창의적인 방향을 강화하려면 긍정적 프롬프트를 완전히 교체할 수 있습니다. 이 프롬프트 임베딩은 두 샘플러 단계를 조건화하여 생성된 비디오가 참조에 충실하도록 유지합니다.
모델#
WanVideoVAELoader (#38)이 인코딩/디코딩에 사용되는 Wan VAE를 로드합니다. 두 개의 WanVideoModelLoader 노드가 Wan 2.2 14B 모델을 준비합니다: 하나는 고노이즈, 하나는 저노이즈로 각각 WanVideoExtraModelSelect (#99, #107)에서 선택된 VACE 모듈로 보강됩니다. 선택적 정제 LoRA는 WanVideoLoraSelect (#56, #97)를 통해 첨부되어 기본 모델을 변경하지 않고 선명도나 스타일을 조정할 수 있습니다. 이 구성은 VACE 가중치, LoRA 또는 노이즈 변종을 교체할 수 있도록 설계되어 그래프의 나머지 부분을 건드리지 않고도 가능합니다.
샘플링#
WanVideoVACEEncode (#100)이 세 가지 신호를 VACE 임베딩으로 융합합니다: 모션 시퀀스 (깊이 프레임), 참조 이미지 및 대상 비디오 기하학. 첫 번째 WanVideoSampler (#27)는 고노이즈 모델을 사용하여 모션, 관점 및 전반적인 스타일을 확립하기 위해 분할 단계까지 실행됩니다. 두 번째 WanVideoSampler (#90)는 그 잠재 상태에서 계속하여 저노이즈 모델로 텍스처, 가장자리 및 작은 세부사항을 회복하면서 모션을 소스에 고정합니다. 짧은 CFG 스케줄과 단계 분할은 각 단계가 결과에 얼마나 영향을 미치는지를 제어합니다.
출력#
WanVideoDecode (#28)이 최종 잠재 상태를 프레임으로 변환합니다. 두 개의 저장된 비디오를 얻습니다: 깨끗한 렌더와 참조 옆에 생성된 프레임을 배치하는 사이드바이사이드 합성. 별도의 “Depth Map Preview”가 추론된 깊이 시퀀스를 보여주어 모션 안내를 한눈에 진단할 수 있습니다. 프레임 속도 및 파일명 설정은 VHS_VideoCombine 출력 (#139, #60, #144)에서 사용할 수 있습니다.
ComfyUI Wan 2.2 VACE 워크플로우의 주요 노드#
WanVideoVACEEncode (#100)#
두 샘플러에서 사용되는 VACE 정체성과 기하학 임베딩을 생성합니다. 모션 프레임과 참조 이미지를 제공하십시오; 노드는 너비, 높이 및 프레임 수를 처리합니다. 지속 시간이나 비율을 변경하면 이 노드를 목표 비디오 레이아웃과 일치하도록 동기화하십시오.
WanVideoSampler (#27)#
고노이즈 Wan 2.2 모델을 사용하는 첫 번째 단계 샘플러. steps, 짧은 cfg 스케줄, end_step 분할을 조정하여 모션 형성에 할당되는 궤적의 양을 결정합니다. 큰 모션 또는 카메라 변경은 약간 늦은 분할에서 더 이익을 얻습니다.
WanVideoSampler (#90)#
저노이즈 Wan 2.2 모델을 사용하는 두 번째 단계 샘플러. start_step을 동일한 분할 값으로 설정하여 첫 번째 단계에서 매끄럽게 계속됩니다. 텍스처가 과도하게 날카롭거나 드리프트가 발생하면 나중 cfg 값을 줄이거나 LoRA 강도를 낮추십시오.
DepthAnythingV2Preprocessor (#135)#
소스 비디오에서 안정적인 깊이 시퀀스를 추출합니다. 깊이를 모션 안내로 사용하면 Wan 2.2 VACE가 장면 레이아웃, 손 포즈 및 폐색을 유지하는 데 도움이 됩니다. 빠른 반복을 위해 입력 프레임을 더 작게 조정할 수 있습니다; 최종 렌더링을 위해 더 높은 해상도의 프레임을 제공하여 구조적 충실도를 높이십시오.
WanVideoTextEncode (#16)#
긍정적 및 부정적 프롬프트를 UMT5-XXL로 인코딩합니다. 프롬프트는 Florence2Run에서 자동으로 생성되지만, 아트 방향을 위해 이를 무시할 수 있습니다. 프롬프트를 간결하게 유지하십시오; VACE 정체성 안내로 인해 더 적은 키워드가 종종 더 깔끔하고 덜 제한적인 모션 전송을 제공합니다.
선택적 추가 기능#
- 가장 안정적인 Wan 2.2 VACE 전송을 위해 명확한 주제 분리와 일관된 조명을 가진 모션 클립을 선택하세요.
- 사이드바이사이드 출력을 사용하여 최종 패스를 렌더링하기 전에 얼굴 정렬과 의상 연속성을 확인하세요.
- 모션이 너무 경직되어 보이면 분할을 약간 더 일찍 이동하여 저노이즈 단계에 더 많은 여유를 주십시오.
- 정체성이 드리프트하면 LoRA 영향을 약간 증가시키거나 프롬프트를 단순화하십시오.
- 깊이 미리보기를 자주 사용하세요: 깊이가 시끄러우면 다른 소스 클립을 시도하거나 입력 크기 조정을 조정하여 아티팩트를 줄이세요.
감사의 글#
이 워크플로우는 다음 작업 및 리소스를 구현하고 기반으로 합니다. 우리는 워크플로우를 위한 Wan 2.2 VACE Source의 ComfyUI 커뮤니티 창작자들의 기여와 유지보수에 감사드립니다. 권위 있는 세부정보는 아래 링크된 원본 문서 및 저장소를 참조하십시오.
리소스#
- Wan 2.2 VACE Source/Wan 2.2 VACE Source
- 문서 / 릴리스 노트: Wan 2.2 VACE @ComfyUI
참고: 참조된 모델, 데이터셋 및 코드의 사용은 해당 저자 및 유지보수자가 제공하는 라이선스 및 조건에 따릅니다.

