
SkyReels V3 ComfyUI: 정체성을 충실히 반영한 이미지, 비디오, 오디오에서 비디오 생성#
SkyReels V3 ComfyUI는 SkyReels V3 다중 모드 비디오 모델을 ComfyUI에 가져와서 정지 이미지를 애니메이션화하고, 기존 촬영을 확장하며, 정확한 립싱크로 오디오 기반의 말하는 아바타를 구축할 수 있는 생산 준비 완료 워크플로우입니다. 영화 같은 움직임, 강력한 주제 정체성, 시간적 일관성을 원하는 창작자를 위해 설계되었습니다.
이 워크플로우는 독립적으로 실행하거나 연결할 수 있는 네 개의 집중 파이프라인을 제공합니다: 이미지에서 비디오로의 캐릭터 애니메이션, 비디오에서 비디오로의 연속, 오디오에서 비디오로의 말하는 아바타, 그리고 이야기 흐름을 위한 다음 샷 생성. 각 경로는 명확한 입력 지점과 합리적인 기본값을 포함하여 자산을 투입하고 고품질 SkyReels V3 출력을 빠르게 렌더링할 수 있습니다.
2X Large 및 그 이상의 기계에 대한 주의 사항 (R2V 워크플로우): 실행하기 전에
Patch Sage Attention KJ(#240)sage_attention를disabled로 설정하십시오. 활성화된 상태로 두면SM90 kernel is not available오류가 발생할 수 있습니다.
Comfyui SkyReels V3 ComfyUI 워크플로우의 주요 모델#
- WanVideo FP8 패키지의 SkyReels V3 비디오 백본 (R2V, V2V Shot, A2V). 이들은 정체성을 인식한 움직임, 비디오 연속성, 오디오로 조건화된 립싱크를 처리하는 핵심 생성기입니다. Hugging Face에서 WanVideo 패키지의 SkyReels V3 가중치를 여기에서 확인하세요.
- 이미지 안내 및 참조 임베딩을 위한 OpenCLIP Vision ViT 모델. 프레임 전반에 걸쳐 외형과 스타일을 보존하는 강력한 시각적 기능을 제공합니다. 프로젝트 페이지: open_clip.
- 프롬프트 이해를 위한 UMT5 텍스트 인코더. 스타일, 장면 및 동작을 유도하기 위한 풍부한 언어 조건을 제공합니다. 레포: umt5.
- 립싱크 및 오디오 분석을 위한 Wav2Vec2 음성 기능. 중국어 기본 변형이 기본적으로 지원되며 유사한 영어 변형도 작동합니다. 모델 카드: TencentGameMate/chinese-wav2vec2-base.
- 음성-텍스트 변환을 위한 Qwen3‑ASR‑1.7B. 참조 오디오를 전사하고 음성 복제 TTS 프롬프트를 부트스트랩하는 데 사용됩니다. 모델 카드: Qwen/Qwen3-ASR-1.7B.
- 보컬 분리를 위한 MelBandRoFormer. 립싱크 임베딩 전에 깨끗한 음성 트랙이 필요할 때 유용합니다. 모델 카드: Kijai/MelBandRoFormer_comfy.
- 쇼트 인식 프롬프트 생성을 위한 MiniCPM‑V. 이전 영상을 분석하고 이야기 연속성을 위한 다음 샷을 제안합니다. 모델 허브: OpenBMB/MiniCPM-V.
Comfyui SkyReels V3 ComfyUI 워크플로우 사용 방법#
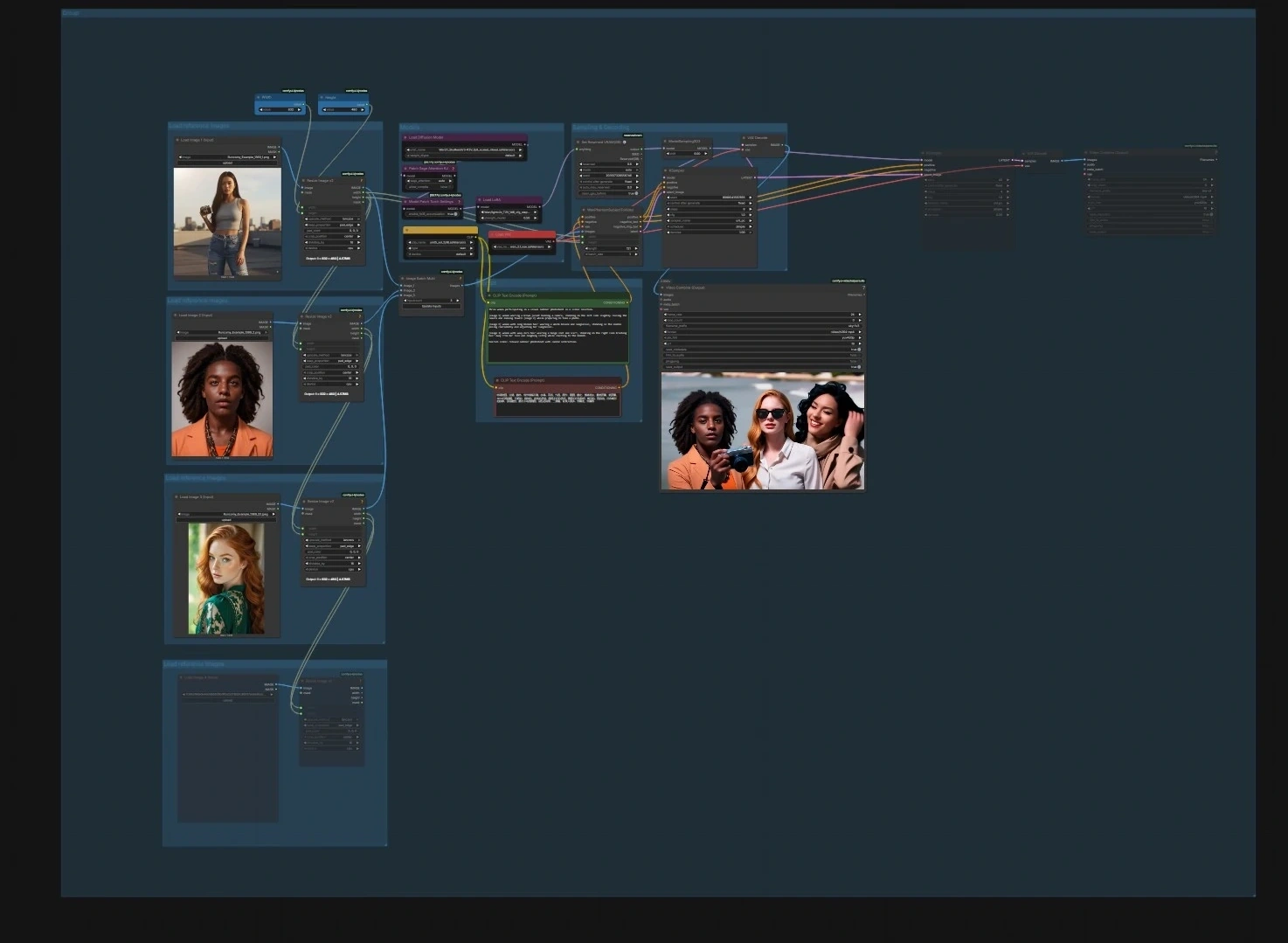
그래프는 네 개의 파이프라인으로 구성되어 있습니다. 각 파이프라인을 독립적으로 실행하거나 순서대로 실행하여 더 긴 편집을 만들 수 있습니다.
이미지에서 비디오로의 캐릭터 애니메이션#
- 모델.
UNETLoader(#241),CLIPLoader(#242),VAELoader(#194)를 사용하여 모델 그룹에서 UNet, CLIP 및 VAE를 로드합니다. 모델 패치 노드PathchSageAttentionKJ(#240)와ModelPatchTorchSettings(#239)는 주의 및 수학 설정을 최적화하고,LoraLoaderModelOnly(#250)를 사용하여 스타일 또는 모션 LoRA를 SkyReels 모델에 혼합할 수 있습니다. - 참조 이미지 로드. 세 개의 "Load reference images" 그룹을 사용하여 1–3개의 초상화 또는 포즈를 가져옵니다. 리사이즈 도우미
ImageResizeKJv2(#291, #298, #299, #304)는 종횡비를 맞추고 배치합니다. 더 깨끗한 정체성 사진이 더 안정적인 결과를 제공합니다. - 프롬프트.
CLIPTextEncode(#6)를 사용하여 프롬프트 그룹에 장면 및 동작 텍스트를 입력하고, 원하지 않는 특성을 멀리 유도하기 위한 선택적 부정 텍스트 인코더CLIPTextEncode(#7)를 사용합니다. 언어는 동작 및 프레이밍에 대해 간결하고 구체적으로 유지하십시오. - 샘플링 및 디코딩.
WanPhantomSubjectToVideo(#249)는 참조 및 프롬프트를 정체성을 인식한 잠재로 결합하여KSampler(#149)를 통해ModelSamplingSD3(#48)에 공급합니다.VAEDecode(#264)에서 디코딩된 프레임은VHS_VideoCombine(#280)을 사용하여 영화로 패키징됩니다. 목표 프레임 속도와 파일 형식을 설정하십시오.
비디오에서 비디오로의 연속 루프#
- 입력 비디오 및 설정.
VHS_LoadVideo(#329)를 사용하여 소스 클립을 가져옵니다. 생성할 추가 세그먼트 수와 세그먼트 간 중첩 정도를 "Number of Extend" (#342) 및 "Overlapping Frames" (#341) 정수 도우미를 사용하여 설정합니다.ImageResizeKJv2(#327)는 샘플러의 해상도를 표준화합니다. - 루프 샘플링 연속 비디오. 루프 쌍
easy forLoopStart(#331) 및easy forLoopEnd(#332)는 클립을 창으로 이동하여 전환을 안정화합니다. 각 창은WanVideoEncode(#326)로 인코딩되고,WanVideoEmptyEmbeds(#328)를 통해 중립 또는 제어 임베드가 수신되며,WanVideoModelLoader(#319)에서WanVideoSampler(#320)가 디노이즈합니다. 프레임은WanVideoDecode(#321)로 디코딩되고,VHS_VideoCombine(#322, #335)로 미리보기 또는 저장됩니다. - 성능 도우미.
WanVideoTorchCompileSettings(#323) 및WanVideoBlockSwap(#325)는 더 긴 또는 더 높은 해상도 실행을 위한 컴파일 및 메모리 트릭을 활성화합니다.
오디오에서 비디오로의 말하는 아바타#
- 1 – 오디오 생성.
FB_Qwen3TTSVoiceClonePrompt(#416) 및FB_Qwen3TTSVoiceClone(#412)를 사용하여 음성 복제 음성 트랙을 생성하거나,LoadAudio(#417)를 사용하여 사전 녹음된 음성을 로드할 수 있습니다.Qwen3ASRLoader(#414) 및Qwen3ASRTranscribe(#413)는 참조 클립에서 텍스트를 추출하여 TTS 프롬프트를 시드하는 데 도움을 줍니다. - 2 – 오디오 기능.
DownloadAndLoadWav2VecModel(#348)는MultiTalkWav2VecEmbeds(#350)에 음성에서 립 모션 임베딩을 생성합니다. 길이는 오디오에 맞춰져 있으며PreviewAudio(#422)로 미리 볼 수 있습니다.Any Switch (rgthree)(#435)를 사용하여 TTS 출력 또는 가져온 파일을 구동 트랙으로 선택하십시오. - 3 – 입력 이미지. "3 - Input image" 그룹에서 말하는 얼굴을 로드하고
ImageResizeKJv2(#370)로 크기를 조정합니다. 깨끗하고 정면을 향한 초상화와 일관된 조명이 가장 잘 작동합니다. - 참조 비디오 생성. 먼저
WanVideoImageToVideoEncode(#392)를 사용하여 정지 이미지에서 짧은 시각적 앵커를 생성합니다.CLIPVisionLoader(#352)와WanVideoClipVisionEncode(#351)의 CLIP-Vision 기능은 다음 단계에서 정체성을 안정화합니다. 샘플링 설정 그룹에서 스케줄러WanVideoSchedulerv2(#385)가 준비됩니다. - 오디오 립싱크 생성.
WanVideoImageToVideoSkyreelsv3_audio(#383)는 시작 이미지, 선택적 참조 프레임 및 CLIP-Vision 임베딩을 이미지 조건화에 결합합니다.WanVideoSamplerv2(#384)는 SkyReels A2V 모델로 디노이즈하며WanVideoSamplerExtraArgs(#386)는 정확한 입 모양을 위한MultiTalk립싱크 임베딩을 주입합니다.WanVideoPassImagesFromSamples(#381)는 디코딩된 프레임을VHS_VideoCombine(#346)으로 스트리밍하여 최종 비디오를 오디오와 함께 뮤직싱합니다.
비디오에서 비디오로의 다음 샷 생성#
- 비디오 프레임 전처리.
VHS_LoadVideo(#443)를 사용하여 이전 샷을 가져오고ImageResizeKJv2(#441)로 크기를 조정합니다.GetImageRangeFromBatch(#445)는 컨텍스트 슬라이스를 선택하여WanVideoEncode(#440)로 잠재로 변환합니다.WanVideoEmptyEmbeds(#442)는 조건 창을 준비합니다. - 자동 비디오 프롬프트.
CreateVideo(#450)는 컨텍스트 프레임에서 컴팩트한 프록시 클립을 조립하여AILab_MiniCPM_V_Advanced(#449)가 다음 샷 프롬프트를 작성하는 데 분석합니다.ShowText|pysssss(#447)에서 초안을 검사하거나 수정하고WanVideoTextEncodeCached(#444)로 임베딩하여 샘플링합니다. - 모델 및 샘플링.
WanVideoModelLoader(#436)와WanVideoVAELoader(#438)를 사용하여 V2V 샷 모델을 로드합니다. 선택적WanVideoBlockSwap(#439)는 VRAM을 처리합니다.WanVideoSampler(#451)는 연속성을 생성하고WanVideoDecode(#437)는 프레임을 렌더링하며VHS_VideoCombine(#446)은 최종 샷을 출력합니다. 이 SkyReels V3 ComfyUI 경로는 각 새로운 컷이 이전 것을 존중해야 하는 스토리보드 및 사전 시각화에 이상적입니다.
Comfyui SkyReels V3 ComfyUI 워크플로우의 주요 노드#
WanPhantomSubjectToVideo(#249). 배치된 참조 이미지와 텍스트 큐에서 정체성을 인식한 잠재를 구축하여 샘플러를 구동합니다. 참조의 수와 다양성을 조정하여 유사성 잠금과 창의적 움직임 사이를 균형 있게 유지하십시오. 드리프트를 피하기 위해 이를 공급하는 리사이즈 노드를 일관되게 유지하십시오. 참조: GitHub의 WanVideo Wrapper에는 구현 노트와 예상 입력이 포함되어 있습니다 ComfyUI‑WanVideoWrapper.WanVideoImageToVideoEncode(#392). 정지를 안정적인 샷 시드로 인코딩하고 선택적으로 포즈와 프레이밍을 위한 CLIP-Vision 지침을 혼합합니다. 오디오 기반 단계 전에 앵커 프레임을 생성하여 파이프라인 전반에 걸쳐 정체성과 카메라 설정을 일관되게 유지하세요. 래퍼 문서: ComfyUI‑WanVideoWrapper.WanVideoImageToVideoSkyreelsv3_audio(#383). A2V 샘플러에 맞춘 이미지 임베딩을 준비하고 선택적 참조 비디오 프레임을 병합합니다. 샘플러 경로와 너비 및 높이를 일치시키십시오.WanVideoSamplerv2및MultiTalkWav2VecEmbeds와 쌍을 이루어 정확한 립싱크를 제공합니다.WanVideoSamplerv2(#384, #387). 이미지 및 텍스트 임베딩과 스케줄러 설정을 수용하는 SkyReels V3의 주요 디노이저입니다.WanVideoSamplerExtraArgs노드 (#386, #409)는 립싱크, 루프 또는 컨텍스트 기능이 주입되는 곳입니다. A2V 및 I2V 모델 간 전환 시 연결된 상태를 유지하십시오. 구현 세부사항: ComfyUI‑WanVideoWrapper.MultiTalkWav2VecEmbeds(#350). 음성을 시간적으로 정렬된 임베딩으로 변환하여 입 모션을 구동합니다. 의도된 프레임 예산을 맞추고 깨끗한 보컬을 보장하면 음소 정확도가 크게 향상됩니다. Wav2Vec 참조 모델: TencentGameMate/chinese-wav2vec2-base.AILab_MiniCPM_V_Advanced(#449). 이전 샷을 분석하고 캐릭터, 배경, 동작, 분위기, 조명을 위한 구조화된 프롬프트를 작성합니다. V2V 다음 샷 경로를 사용할 때 이야기 연속성을 유지하는 데 사용합니다. 결과 텍스트는WanVideoTextEncodeCached로 흐릅니다. 모델 패밀리: OpenBMB/MiniCPM-V.
선택적 추가 기능#
- 연결된 노드 간 이미지, 비디오 및 샘플러 해상도를 일관되게 유지하여 종횡비 왜곡과 정체성 깜박임을 방지하십시오.
- 더 긴 확장을 위해 V2V 확장 루프에서 창 중첩을 늘려 세그먼트 간 전환을 부드럽게 만드십시오.
- GPU 메모리가 부족할 경우,
ReservedVRAMSetter(#312, #448) 노드를 활성화 상태로 두고 샘플링 전에 컴파일 설정 블록을 사용하십시오. - 말하는 아바타가 비트를 벗어나는 경우,
MultiTalk임베딩을 생성하기 전에 깨끗한 음성 또는 MelBandRoFormer로 보컬을 분리하는 것을 우선시하십시오. - 최종 전달 설정은
VHS_VideoCombine출력 노드에서 프레임 속도, 픽스 형식 및 CRF로 제어됩니다. 원본과 일치하는 프레임 속도로 원활한 편집을 수행하십시오.
이 README는 SkyReels V3 ComfyUI 그래프 전체를 다루며, 프로젝트에 맞는 경로를 선택하고 필요에 따라 결합하여 일관된 스토리 준비 비디오를 최소한의 시행착오로 렌더링할 수 있습니다.
감사의 글#
이 워크플로우는 다음 작업 및 리소스를 구현하고 기반으로 합니다. SkyReels V3 ComfyUI 워크플로우에 대한 기여와 유지를 위한 @Benji’s AI Playground 및 SkyReels에 감사드립니다. 권위 있는 세부 사항은 아래에 연결된 원본 문서 및 리포지토리를 참조하십시오.
리소스#
- **SkyReels/V3 ComfyUI 소스json