






텍스트 정확한 초상화와 장면을 위한 Qwen Image 2512 ComfyUI 워크플로우#
이 워크플로우는 Qwen Image 2512를 사용하여 프롬프트를 고충실도 이미지로 전환합니다. 강력한 텍스트-이미지 정렬, 현실적인 사람, 장면 내 신뢰할 수 있는 이중 언어 텍스트 렌더링이 필요한 창작자를 위해 설계되었습니다. Qwen의 VAE와 텍스트 인코더, 그리고 몇 단계의 생성 가속을 위한 선택적 Lightning LoRA가 사전 연결되어 있어 최소한의 설정으로 프롬프트에서 결과로 이동할 수 있습니다.
컨셉 아트, 일러스트레이션, 간판, 포스터, 그리고 일상적인 사진 스타일에 사용하세요. Qwen Image 2512는 안정적인 구성과 선명한 타이포그래피를 제공하여 사람, 환경, 읽을 수 있는 텍스트를 혼합한 프롬프트에 적합한 선택입니다.
Comfyui Qwen Image 2512 워크플로우의 주요 모델#
- Qwen-Image 2512 기본 모델 (bfloat16). 조건부에서 이미지를 합성하는 핵심 확산 모델입니다. Comfy‑Org 패키지에서 Comfy‑ready 가중치가 제공됩니다. 모델 파일
- Qwen2.5‑VL 7B 텍스트 인코더. Qwen Image 2512의 레이아웃, 스타일 및 텍스트 렌더링을 구동하는 조건 벡터로 프롬프트를 인코딩합니다. 텍스트 인코더 파일
- Qwen Image VAE. 샘플러가 생성한 잠재를 RGB 이미지로 충실하게 디코딩합니다. VAE 파일
- Qwen‑Image‑2512‑Lightning‑4steps‑V1.0 LoRA (선택적). 몇 단계의 생성 가속을 위한 커뮤니티 LoRA로 품질의 미세한 타협을 통해 렌더링 속도를 가속화합니다. LoRA 카드
- 모델 패밀리와 훈련 접근 방식에 대한 배경은 Qwen‑Image 기술 보고서를 참조하세요. 논문
Comfyui Qwen Image 2512 워크플로우 사용 방법#
전체 흐름: 프롬프트가 인코딩되고, 선택한 해상도에서 잠재 캔버스가 생성되며, 모델 스택이 기본 모델과 선택적 LoRA를 적용하고, 샘플러가 잠재를 정제하기 위해 반복하며, VAE가 최종 이미지를 디코딩하여 저장합니다.
- Qwen‑Image‑2512 그룹 개요
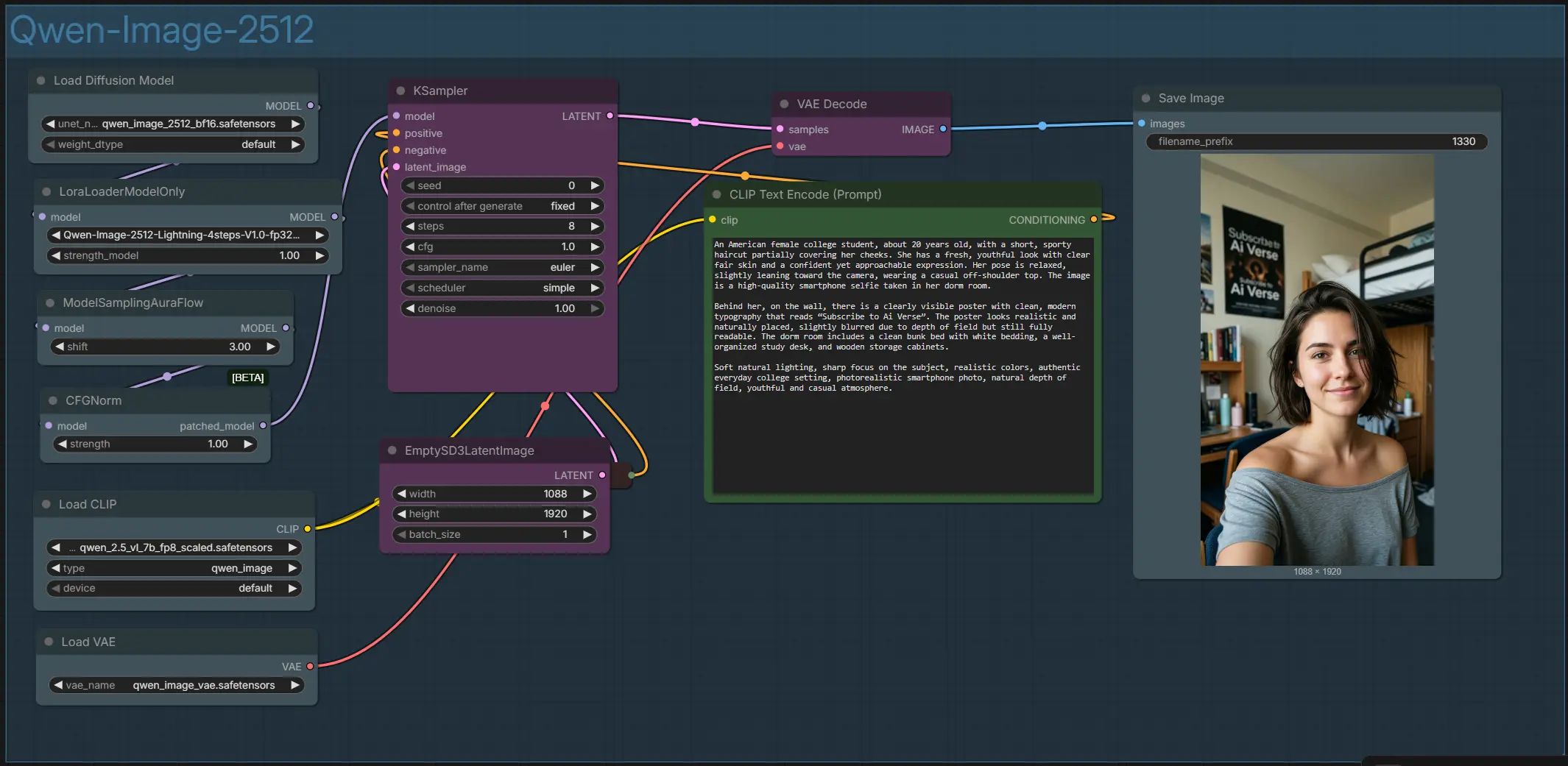
- 전체 그래프는 "Qwen‑Image‑2512"라는 단일 그룹 내에 정리되어 있습니다. 텍스트 인코더, 모델 및 LoRA 스택, 샘플링 도우미, VAE 디코드를 연결합니다. 긍정적 및 부정적 프롬프트, 캔버스 크기, 몇 가지 샘플러 설정으로 외관을 제어합니다. 출력은 ComfyUI 출력 폴더에 저장된 고해상도 초상화 스타일 이미지입니다.
CLIPTextEncode(#52)와 선택적 부정적CLIPTextEncode(#32)를 사용한 프롬프트CLIPTextEncode(#52)에 주요 설명을 입력하세요. 장면, 주제 및 렌더링할 이미지 내 텍스트를 작성하세요; Qwen Image 2512는 간판, 포스터, UI 목업 및 이중 언어 캡션에 특히 강합니다.CLIPTextEncode(#32)를 사용하여 아티팩트나 원치 않는 스타일을 회피하도록 선택적 부정을 사용하세요. 정확한 구문이 필요할 경우 텍스트 조각을 따옴표 안에 유지하세요.
EmptySD3LatentImage(#57)를 사용한 캔버스 및 종횡비- 여기에서 목표 너비와 높이를 선택하여 구성을 설정하세요. 인물 및 셀피에는 세로 형식이 잘 맞으며, 제품 및 장면 레이아웃에는 정사각형 및 가로 비율이 적합합니다. 더 큰 캔버스는 세부사항을 더 정밀하게 제공하지만 메모리와 시간이 더 소요됩니다; 프레이밍이 마음에 들 때까지 처음에는 적당하게 시작한 후 점차적으로 확대하세요. 일관성은 반복 간 동일한 종횡비를 유지할 때 향상됩니다.
UNETLoader(#100)와LoraLoaderModelOnly(#101)를 사용한 모델 및 LoRA 스택- 기본 생성기는
UNETLoader(#100)를 통해 로드된 Qwen Image 2512입니다. 더 빠른 렌더링을 원한다면LoraLoaderModelOnly(#101)에서 Lightning LoRA를 활성화하여 몇 단계의 워크플로우로 전환하세요. 이 스택은 샘플링이 시작되기 전에 현실감, 레이아웃 및 텍스트-이미지 정렬에 대한 모델의 기능을 설정합니다.
- 기본 생성기는
ModelSamplingAuraFlow(#43)와CFGNorm(#55)를 사용한 샘플링 도우미- 이 두 노드는 안정적이고 대조 균형 잡힌 샘플링을 위해 모델을 준비합니다.
ModelSamplingAuraFlow(#43)는 텍스처가 과도하게 조리되지 않고 세부사항을 선명하게 유지하도록 일정을 조정합니다.CFGNorm(#55)는 가이던스를 정규화하여 프롬프트를 따르면서 일관된 색상과 노출을 유지합니다.
- 이 두 노드는 안정적이고 대조 균형 잡힌 샘플링을 위해 모델을 준비합니다.
KSampler(#54)를 사용한 디노이징 및 정제- 노이즈에서 일관된 이미지로 잠재를 점진적으로 개선하는 핵심 단계입니다. 반복성을 위해 시드를 설정하고, 샘플러와 스케줄러를 선택하며, 몇 단계 실행할지 선택합니다. Lightning이 활성화된 경우 몇 단계로 목표를 설정할 수 있습니다; 기본 모델만 사용할 경우 최대 충실도를 위해 더 많은 단계를 사용하세요.
VAEDecode(#45)와SaveImage(#117)를 사용한 디코딩 및 저장- 샘플링 후, VAE는 잠재로부터 RGB를 깨끗하게 재구성하고
SaveImage는 최종 PNG를 기록합니다. 색상이나 대비가 잘못된 것처럼 보이면 포스트 프로세싱보다는 가이던스나 프롬프트 문구를 다시 방문하세요; Qwen Image 2512는 설명적인 조명과 재질 단서에 잘 반응합니다.
- 샘플링 후, VAE는 잠재로부터 RGB를 깨끗하게 재구성하고
Comfyui Qwen Image 2512 워크플로우의 주요 노드#
UNETLoader(#100)- 전반적인 기능과 스타일 공간을 결정하는 Qwen‑Image‑2512 기본 모델을 로드합니다. GPU가 허용하는 경우 bf16 빌드를 사용하여 최대 품질을 얻으세요. 메모리를 맞추거나 처리량을 늘려야 하는 경우에만 fp8 또는 압축 변형으로 전환하세요.
LoraLoaderModelOnly(#101)- 기본 모델 위에 Qwen‑Image‑2512‑Lightning‑4steps‑V1.0 LoRA를 적용합니다.
strength_model을 올리거나 낮추어 속도 조정과 기본 충실도를 혼합하거나, 0으로 설정하여 비활성화하세요. 이 LoRA가 활성화된 경우,KSampler에서 단계를 몇 번으로 줄여 속도 향상을 실현하세요.
- 기본 모델 위에 Qwen‑Image‑2512‑Lightning‑4steps‑V1.0 LoRA를 적용합니다.
ModelSamplingAuraFlow(#43)- 흐름 스타일 일정에 대한 모델의 샘플링 동작을 패치하여 종종 더 선명한 가장자리와 적은 얼룩을 생성합니다. 결과가 과도하게 선명하거나 세밀하지 않게 보이면
shift매개변수를 약간 조정하고 다시 샘플링하세요. 테스트할 때 다른 변수를 안정적으로 유지하여 효과를 격리하세요.
- 흐름 스타일 일정에 대한 모델의 샘플링 동작을 패치하여 종종 더 선명한 가장자리와 적은 얼룩을 생성합니다. 결과가 과도하게 선명하거나 세밀하지 않게 보이면
CFGNorm(#55)- 분류기 자유 가이던스를 정규화하여 세탁되거나 과포화된 출력을 방지합니다.
strength를 사용하여 정규화가 얼마나 단호하게 작동해야 하는지를 결정하세요. 텍스트 정확도가 떨어질 경우, CFG를 더 높이기보다는 정규화 강도를 높이세요.
- 분류기 자유 가이던스를 정규화하여 세탁되거나 과포화된 출력을 방지합니다.
EmptySD3LatentImage(#57)- 프레이밍과 종횡비를 정의하는 잠재 캔버스 크기를 설정합니다. 사람의 경우, 초상화 비율은 왜곡을 줄이고 신체 비율을 돕습니다; 포스터의 경우, 정사각형 또는 가로 비율은 레이아웃과 텍스트 블록을 강조합니다. 구성이 마음에 들 때만 해상도를 높이세요.
CLIPTextEncode(#52)와CLIPTextEncode(#32)- 긍정적 인코더 (#52)는 장면에 렌더링할 명시적 텍스트 문자열을 포함하여 설명을 조건으로 변환합니다. 부정적 인코더 (#32)는 아티팩트, 여분의 손가락 또는 시끄러운 배경과 같은 원치 않는 특성을 억제합니다. 최상의 정렬을 위해 프롬프트를 간결하고 사실적으로 유지하세요.
KSampler(#54)- 시드, 샘플러, 스케줄러, 단계, CFG 및 디노이즈 강도를 제어합니다. Qwen Image 2512와 함께, 중간 CFG 값은 일반적으로 모델의 강력한 텍스트 정렬을 보존합니다; 글자가 변형될 경우, 샘플러를 변경하기 전에 CFG를 낮추세요. 빠른 초안을 위해 Lightning을 활성화하고 매우 적은 단계를 시도한 후, 최종 렌더링이 필요할 경우 단계를 늘리세요.
VAELoader(#34)와VAEDecode(#45)- 충실한 색상과 세부 사항을 재구성하기 위해 Qwen의 VAE를 로드하고 적용합니다. 색상 변화를 피하기 위해 VAE를 기본 모델과 쌍으로 유지하세요. 기본 가중치를 전환할 경우, 일치하는 VAE 빌드로 전환하세요.
선택적 추가 기능#
- 이미지 내 텍스트 프롬프팅
- 정확한 단어를 직선 따옴표 안에 넣고 "깨끗한 현대 타이포그래피"나 "굵은 산세리프"와 같은 간략한 타이포그래피 큐를 추가하세요. 텍스트가 나타나야 할 위치를 앵커로 하기 위한 "벽 포스터"나 "상점 앞 간판"과 같은 배치 힌트를 포함하세요.
- Lightning을 사용한 더 빠른 반복
- Lightning LoRA를 활성화하고 프리뷰를 위한 적은 단계를 사용하세요. 프레이밍과 워딩이 올바르면 LoRA 강도를 비활성화하거나 줄이고 단계를 늘려 최대 충실도를 회복하세요.
- 종횡비 선택
- 변형 전반에 걸쳐 일관된 비율을 유지하세요. 사람에게는 초상화, 제품 또는 로고 연구에는 정사각형, 환경 또는 슬라이드에는 가로를 사용하세요. 나중에 업스케일할 경우, 구성을 유지하기 위해 동일한 비율을 유지하세요.
- 가이던스 규율
- Qwen Image 2512는 일반적으로 적당한 CFG를 선호합니다. 텍스트 충실도가 떨어질 경우, 더 많은 가이던스를 쌓기보다는 CFG를 낮추거나
CFGNorm강도를 높이세요.
- Qwen Image 2512는 일반적으로 적당한 CFG를 선호합니다. 텍스트 충실도가 떨어질 경우, 더 많은 가이던스를 쌓기보다는 CFG를 낮추거나
- 재현성
- 결과가 마음에 들면 시드를 잠그어 안전하게 반복할 수 있습니다. 영향을 이해하기 전에 한 번에 하나의 제어를 변경하세요.
감사의 말씀#
이 워크플로우는 다음 작업과 리소스를 구현하고 구축합니다. Qwen Image 2512 모델 파일에 대한 기여와 유지 관리에 대해 Comfy-Org에 감사드립니다. 권위 있는 세부 사항은 아래에 링크된 원본 문서와 저장소를 참조하세요.
리소스#
- Comfy-Org/Qwen Image 2512 모델 파일
- Hugging Face: Comfy-Org/Qwen-Image_ComfyUI
- 문서 / 릴리스 노트: Qwen Image 2512 모델 파일
참고: 참조된 모델, 데이터 세트 및 코드의 사용은 해당 저자 및 유지 관리자가 제공한 라이선스 및 조건에 따릅니다.